Core Concepts
Orkes Conductor is a platform for building distributed systems. Fundamentally it takes care of orchestrating your flows reliably through various pieces in your applications, such as code, functions, APIs, and more. The process of orchestrating using Conductor revolves around three main concepts: Tasks, Workers, and Workflows.
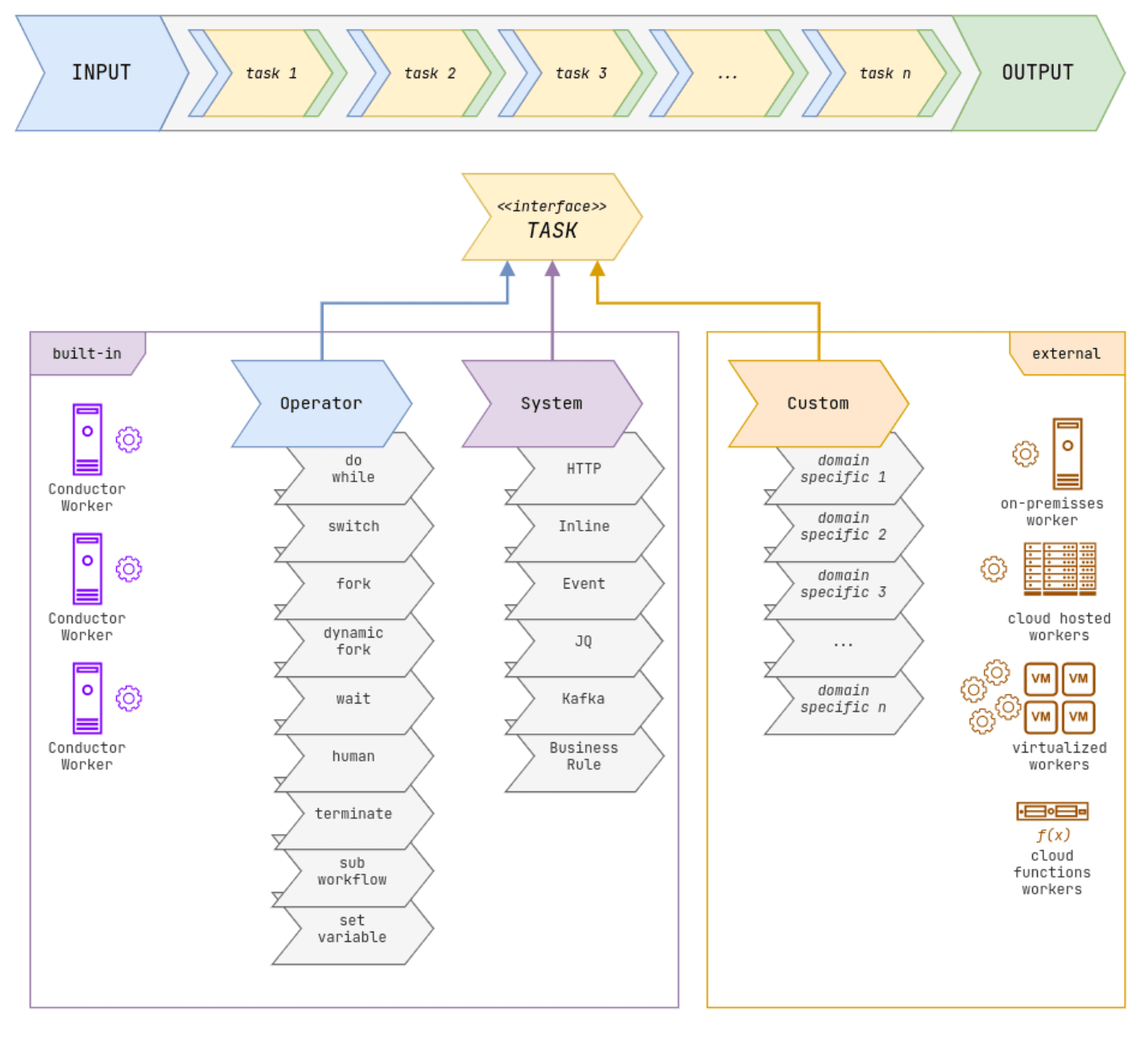
Tasks
A Task represents a unit of work or a step in your flow, such as making an HTTP call, sending an email, processing data files or executing some logic. A task is the basic building block of a workflow that can be further classified into operators, system tasks, or custom code workers.
An Operator in a workflow is your programming language construct, such as a switch, loop, fork/join or return statement, whereas a System task is a pre-built task used for most common operators, such as an event task, HTTP task, polling an endpoint, and many more.
Workers
A worker is responsible for executing a task. Operators and System tasks are handled by the Conductor server, whereas the user-defined tasks are managed by applications implementing them. This worker will poll Conductor server to receive and execute any scheduled work. Conductor passes the inputs to the task worker for execution and collects the output back and the process continues to the next step as per the workflow definition.
Conductor is agnostic to how the workers are deployed and provide lightweight SDKs in all major languages that allow you to expose existing functionality as Conductor Workers. Workers can run on bare metal, containers, VMs, or as serverless functions.
Workflows
Workflow can be defined as the collection of tasks and operators that specifies the order and execution of the defined tasks. This orchestration occurs in a hybrid ecosystem that encircles serverless functions, microservices, and monolithic applications. Furthermore, as the Conductor is language agnostic, the orchestration can be across any programming language.
Workflow = {Tasks + Workers}