ENGINEERING
Workflows as a Distributed Transactional Backend

Viren Baraiya
CTO
Last updated: April 26, 2023
April 26, 2023
9 min read








Join thousands of developers building the future with Orkes.
In a recent blog, a16z discussed the state of the modern transactional stack and called out Orkes Conductor as one of the important frameworks of the modern transactional backend. That article discusses the current state and landscape of application development platforms that provide transaction management capabilities out of the box. In this article, we look at the two main approaches — database-oriented and workflow-oriented transactional backends — and discuss the architecture of an application leveraging each of them and weigh the pros and cons of the two approaches.
All modern apps are distributed systems. In modern applications, different components or services often need to work together to provide a seamless user experience. For example, a mobile app might need to communicate with a back-end service to retrieve data or process a user’s request. This requires the app and the service to exchange information over a network, which is a key characteristic of a distributed system.
Moreover, modern applications often rely on cloud computing and other infrastructure services, such as databases, message queues, and caching systems, which are distributed by nature. These services provide key features like scalability, fault tolerance, and high availability, all of which are essential for modern applications to meet the demands of a global audience.
The distributed nature of modern applications allows them to be more flexible, scalable, and resilient, which is why they have become the preferred architecture for modern day enterprise software development.
Compare this to a traditional enterprise application where all the requests from clients are executed within a database transaction and all of the data required to serve the need of the application resides in a single application specific database. This works great but creates a pattern of monolith that is harder to scale, change and difficult to maintain in the longer term. Also, there is a question of long running workflows which could span over days if not months or even years, where the question of maintaining application transactions still requires a solution that is not offered by databases.
This brings an important question — if you are adopting an application architecture that is running distributed services, how do you handle transactions that span across multiple services?
Consider an order management system:
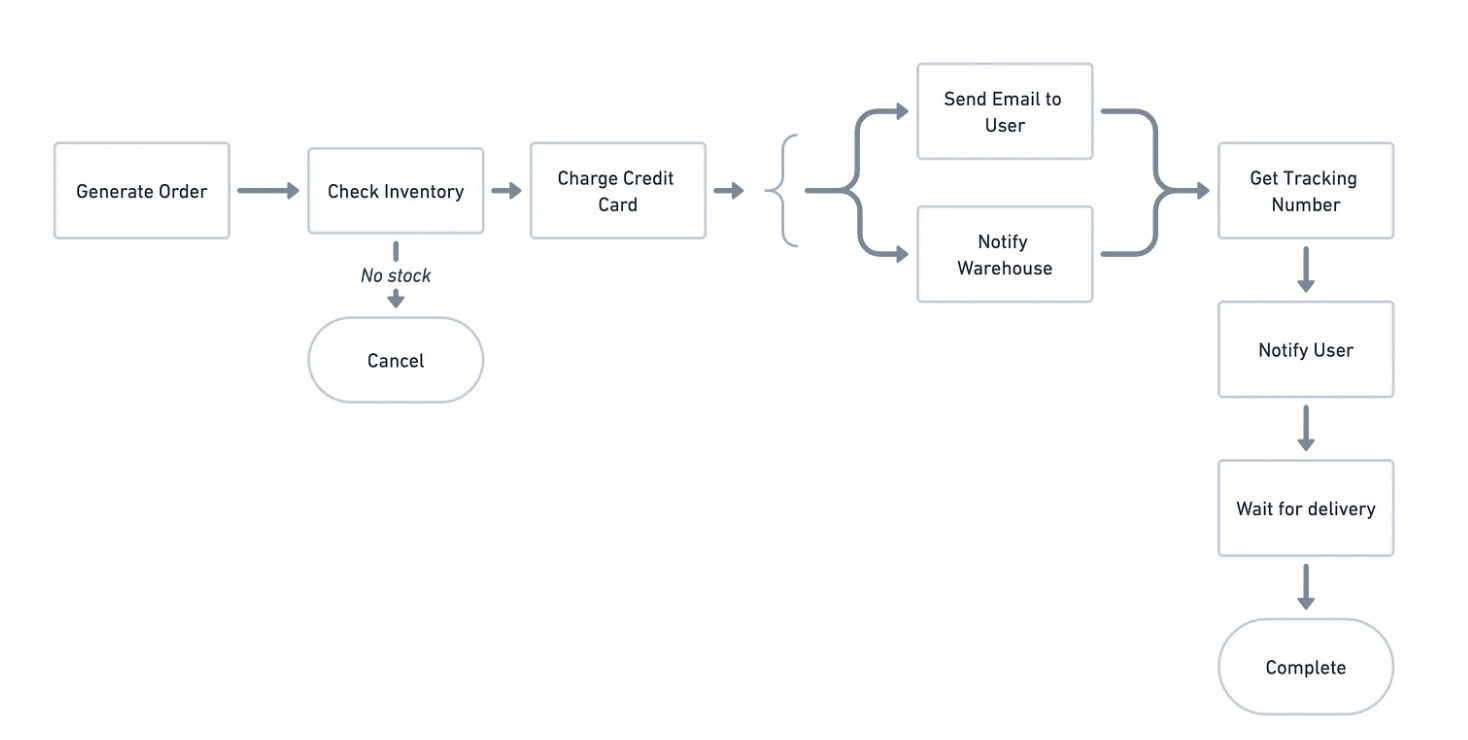
An application with multiple services has two types of transactions:
We want the systems to be consistent in their state of the world. However, this is often harder to achieve in a distributed system, given multiple factors and the need to coordinate a single transaction across them that could be running for days.
In a traditional database oriented system, the database acts as a transaction coordinator providing the level of consistency that is offered by the database. However, that still does not solve the cases of long running and asynchronous flows where the transaction needs to be updated out of band and managed according to the business requirements.
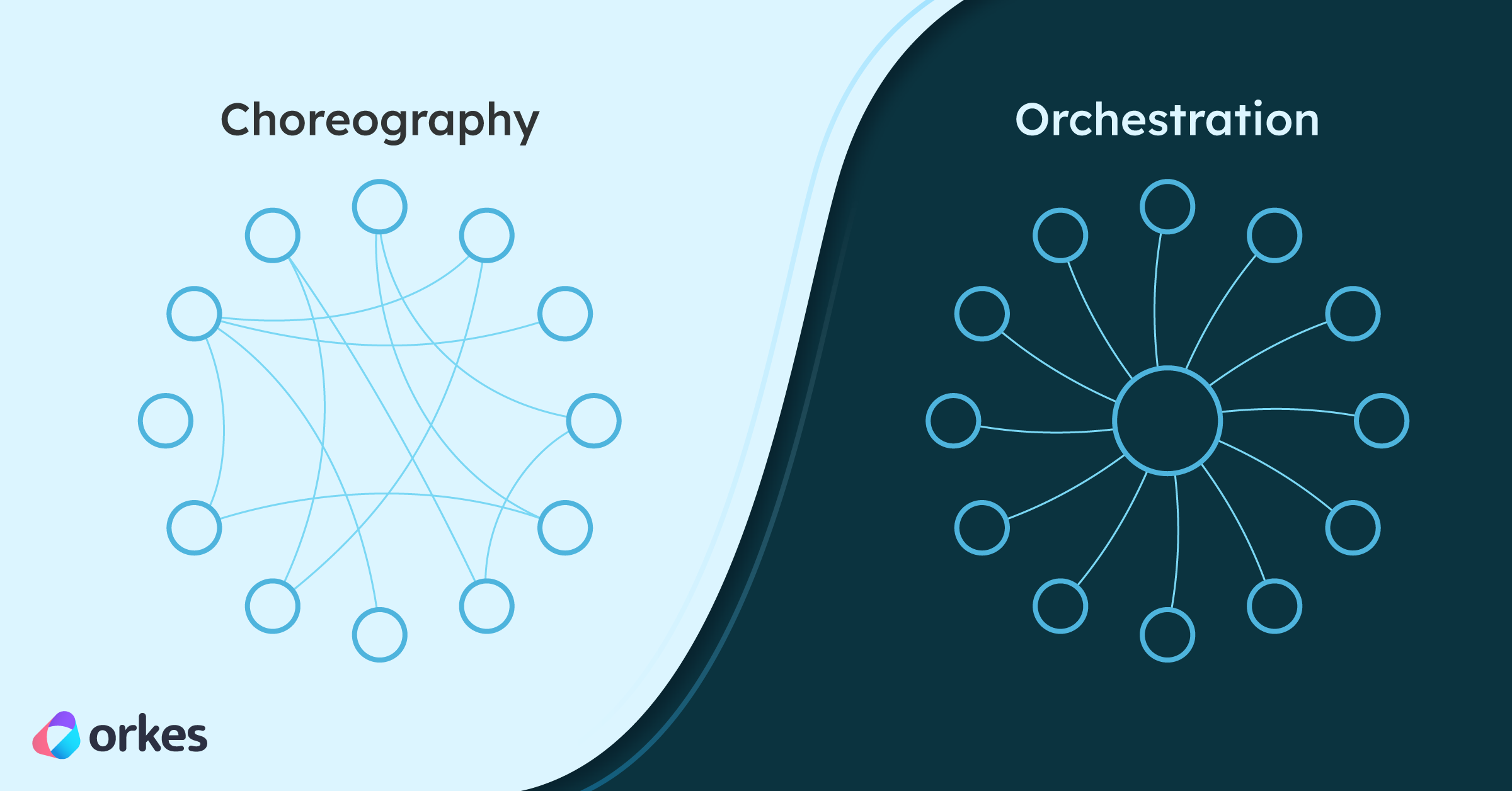
Workflows in distributed event driven applications allow services to communicate with each other via events, making it a source of truth for the application state. An orchestrator such as Orkes Conductor acts as a centralized coordinator that maintains the application state and handles the distributed transactions. This is often referred to as a saga pattern.
The core idea of the Saga pattern is that long transactions are split into short transactions coordinated by a transaction coordinator such as Orkes Conductor. If each short transaction operation successfully completes, then the global transaction completes normally, and if a step fails, the compensating operations are invoked one at a time in reverse order.
This approach massively simplifies the management of long running distributed transactions and the problem of managing application state across multiple services.
Managing long running transactions often require different strategies to handle the patterns of “rollback” or compensation. The rollback is typically done by reversing the local transactions via compensation. What gets rolled back and the associated compensation often depends on the current state of the transaction.
For example, in our order management system, if the delivery fails, the compensation logic could be to issue a refund on the credit card, send an email to the user notifying the situation and update the status of the order in the database.
Failure to process credit card transactions could mean canceling the order and sending an email to the user.
With a platform like Orkes Conductor, this is handled via compensation workflows that are triggered when a workflow fails due to an error in the system or a business case validation failure (insufficient inventory). Workflow engines serve two purposes here:
A typical application will have two kinds of states:
These two states are often decoupled. The business state is often updated by an application flow as a step in its workflow as part of the local transaction.
One approach is to use a database centric stack that allows you to manage application and business state from a database transaction. This approach has its merits in the simplicity as you can write your entire application with the database managing the overall state.
While simple, it breaks down as the application logic starts to get more complex. However, there are several downsides to this approach:
The architecture where the workflow engine works alongside business state management workers is not new, and we leveraged this architecture at Netflix successfully across multiple applications where Conductor maintained the application state and dedicated workers managed the business state in a database. (However, that part was not open sourced).
In this architecture, a set of dedicated workers responsible for maintaining the business state are “listening” to the application workflow state and creating the necessary database transactions to reflect the business state. e.g., when the workflow starts, the onStart event inserts a new order with the order id in the database and when the workflow completes, the onComplete event updates the status. In this case, the status listeners are the source of writes to the database table, which anyone can read outside of the workflow.
Though it might seem complex at first, the approach scales well with business complexity and growth.
Combining the semantics of a database centric approach into the workflow creates a powerful combination that allows building very complex and scalable distributed applications with ease. We believe that this approach provides the best of both worlds and scales much better in terms of handling business complexity as well as application usage growth.
Check us out at orkes.io and the open source Conductor at https://github.com/conductor-oss/conductor.
Conductor is an enterprise-grade orchestration platform for process automation, API and microservices orchestration, agentic workflows, and more. Check out the full set of features, try it yourself using our Developer Edition sandbox, or get a demo of Orkes Cloud, a fully managed and hosted Conductor service.