INSIGHTS
What is Orchestration?

Liv Wong
Technical Writer
Last updated: August 23, 2024
August 23, 2024
8 min read








Join thousands of developers building the future with Orkes.
Orchestration is the process of coordinating distributed software components and systems so that they execute seamlessly as an automated, repeatable process.
In orchestration, a central platform (known as the orchestrator) coordinates the interactions between different components, such as microservices, APIs, databases, algorithms, eventing systems, LLM models, and other third-party systems so that they can work together efficiently toward an end goal. All sorts of processes can be orchestrated, from microservice-based application flows and IT infrastructure automation to data pipelines and digital user journeys.
Through orchestration, individual components and systems need not interact or integrate directly with each other. Instead, the orchestrator ensures each step in the process gets completed by the responsible component, by scheduling tasks, tracking its state, managing data flow and memory, optimizing resource utilization, and handling failure scenarios.
Orchestration and automation are related but different concepts.
Orchestration is about coordinating different systems so that it is easier to manage complex workflows. Automation is about using machines or technology to make a process automatic, reducing or eliminating the need for human intervention. Some examples of automation are smart home devices, adaptive cruise control, or automatic software updates.
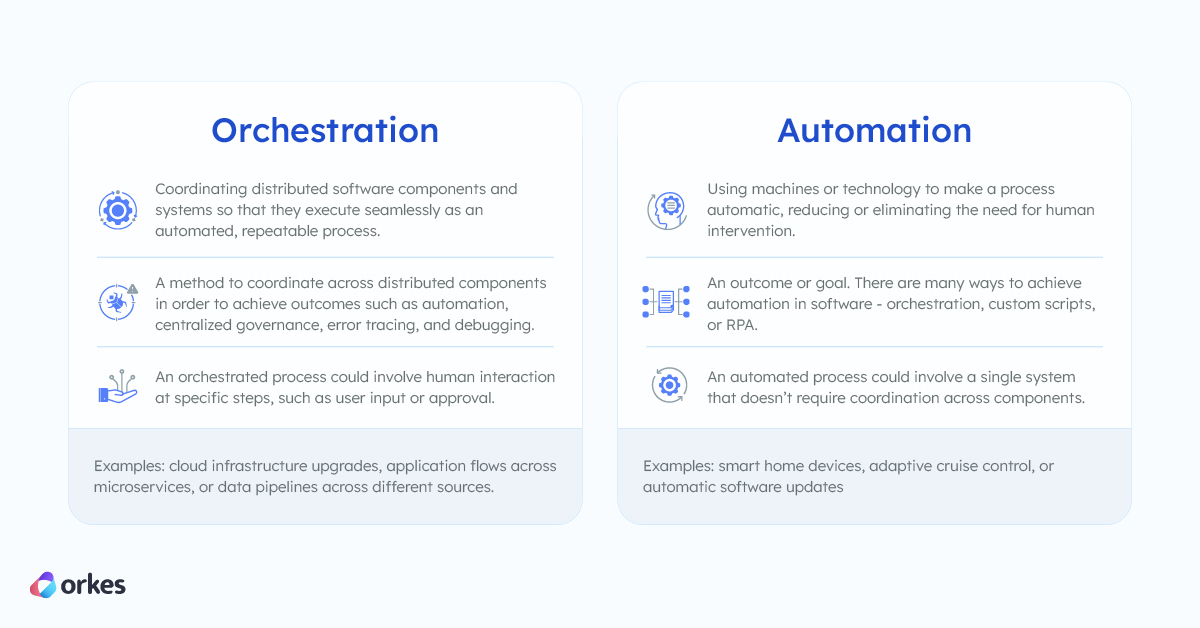
Automation does not entail orchestration and could involve a single system that doesn’t require coordination across components. On the other hand, orchestration often involves automating a particular process across distributed systems, such as cloud infrastructure upgrades, application flows across microservices, or data pipelines across different sources.
Orchestration is not the only way to automate a process. For example, you could write custom scripts or use RPA (robotic process automation) instead of orchestration. However, orchestration may be more suited in many cases, as it offers multiple benefits other than automation, such as in-built error handling and state tracking (explored further below).
Orchestration also need not involve automation at every step. Some processes could involve human-involved tasks, like shipping and logistics flows or digital onboarding across platforms.
In summary, orchestration is the means to achieve an outcome, which is usually the automation of a process.
The orchestration layer is an infrastructure component that coordinates the interactions of different services, databases, and components. It is a central layer that lies beneath and interacts with the user interface or client, so that developers can focus on building each component without worrying about how to integrate them with each other.
The orchestration layer is responsible for scheduling and dispatching calls to the underlying services and databases, based on a predefined sequence of steps and triggers. It manages the flow of data between each component, handles retries and timeouts, and keeps track of the progress at any point in time.
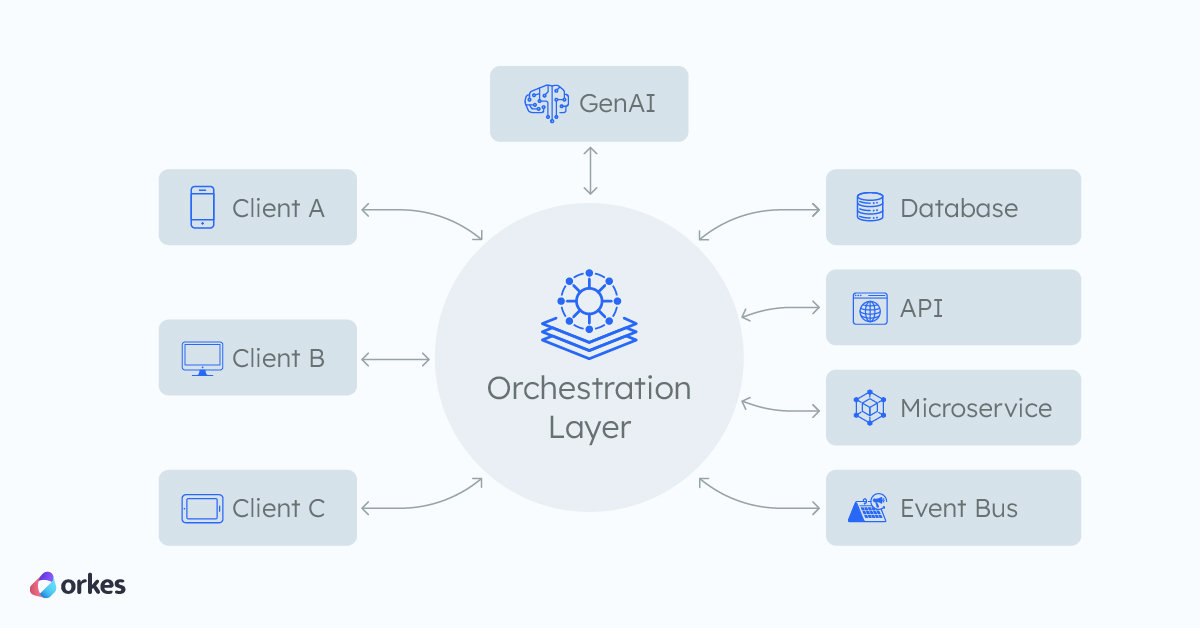
The orchestration layer serves as the headquarters for process delivery and monitoring, with capabilities for service registration, execution logs, failure handling, load balancing, scaling, and versioning. Its primary purpose is to ensure that the overall process runs to completion without needing to know how the service is carried out. In essence, it abstracts away the complexities of the underlying service implementation from the overarching, high-level business process.
Learn more about how orchestration platforms work under the hood to guarantee durable executions.
An orchestration layer or platform typically consists of the following:
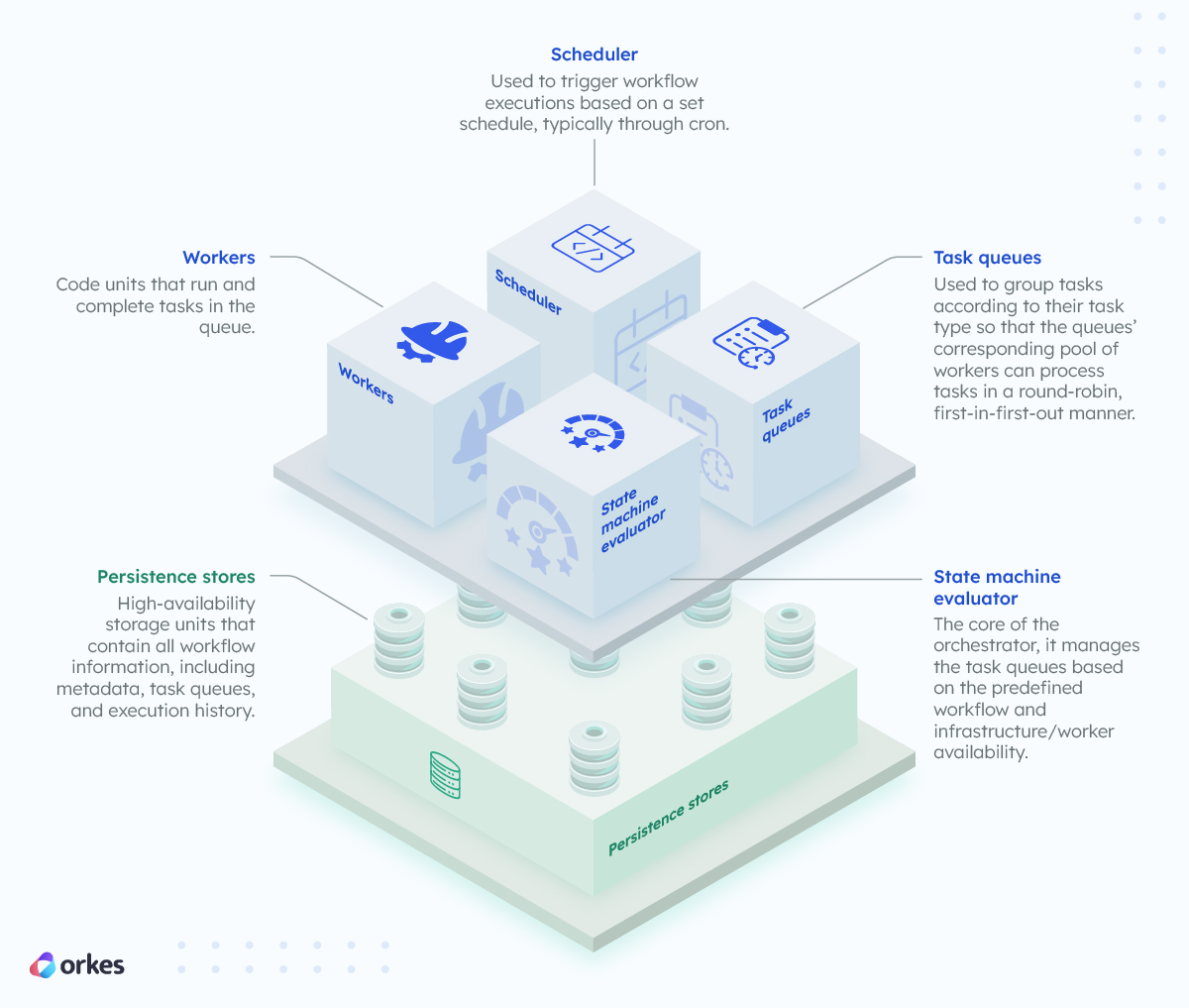
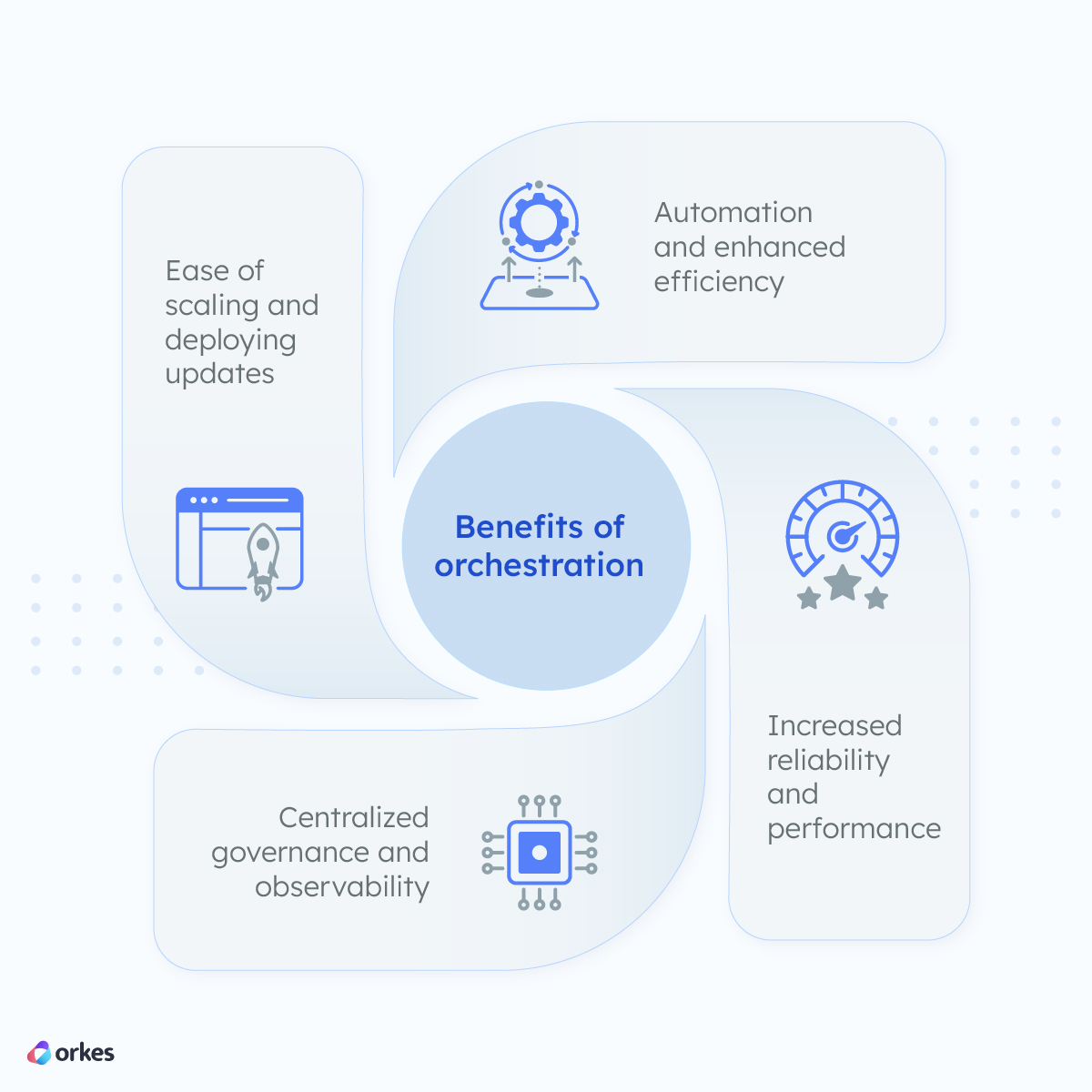
Orchestration arose against the backdrop of distributed computing and increasing complexity in the technology stack. Beyond simplifying the development effort of architecting complex processes, orchestration offers a multitude of benefits:
There are many processes across industries that can benefit from orchestration:
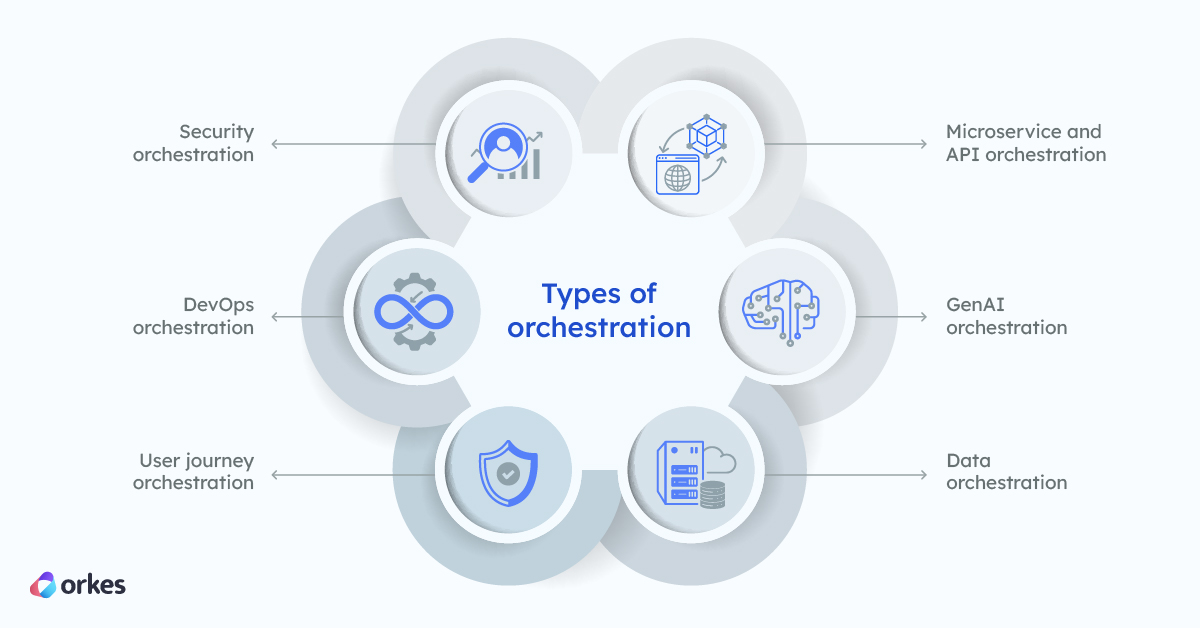
Orkes Conductor is a powerful orchestration platform for any use case involving microservices, APIs, event handling, LLM chaining, and human-involved journeys. Orkes Conductor empowers teams to swiftly and easily build resilient, scalable systems.
Developer-first
Build quickly and slash development lifecycles.
With Orkes, developers get to implement each component using specific languages or frameworks without worrying about how to integrate and trace them throughout the workflow.
Scalable and durable
Conductor provides a highly decoupled infrastructure created for durability, speed, and redundancy.
Try it out
Get started with orchestration in a few steps:
Taking an order processing flow as an example, let’s explore how orchestration works in practice. In this order processing workflow, the order is first validated. If successful, the workflow proceeds with tax calculation, invoice generation, and an order confirmation notification.
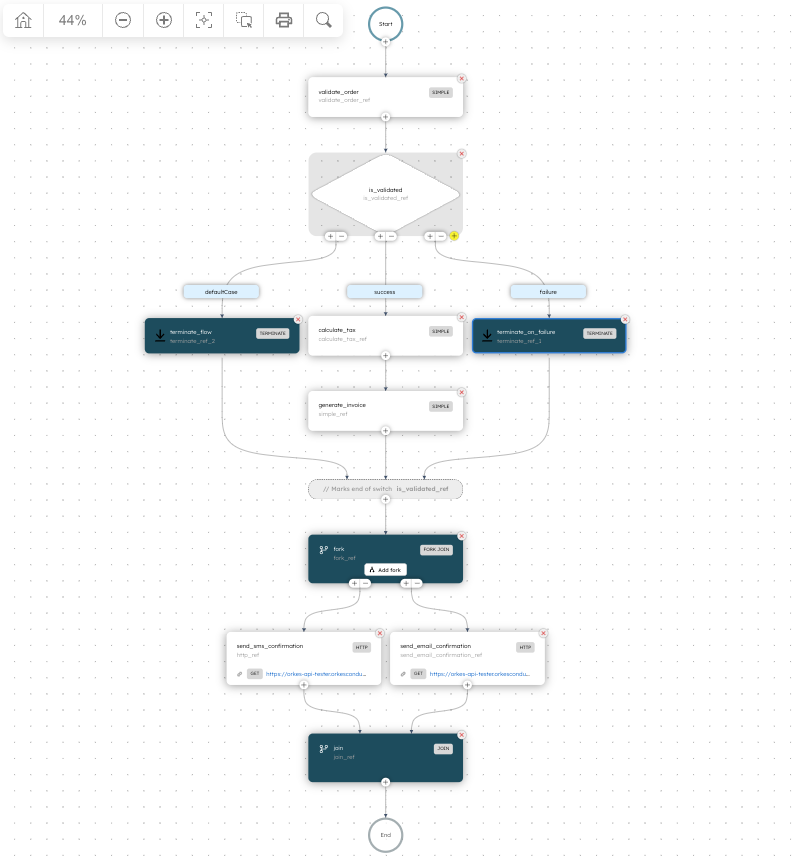
To route the workflow based on the outcome of the order validation task, a Switch task is used. As shown below, the switch evaluation is based on the output returned by the preceding validate_order task.
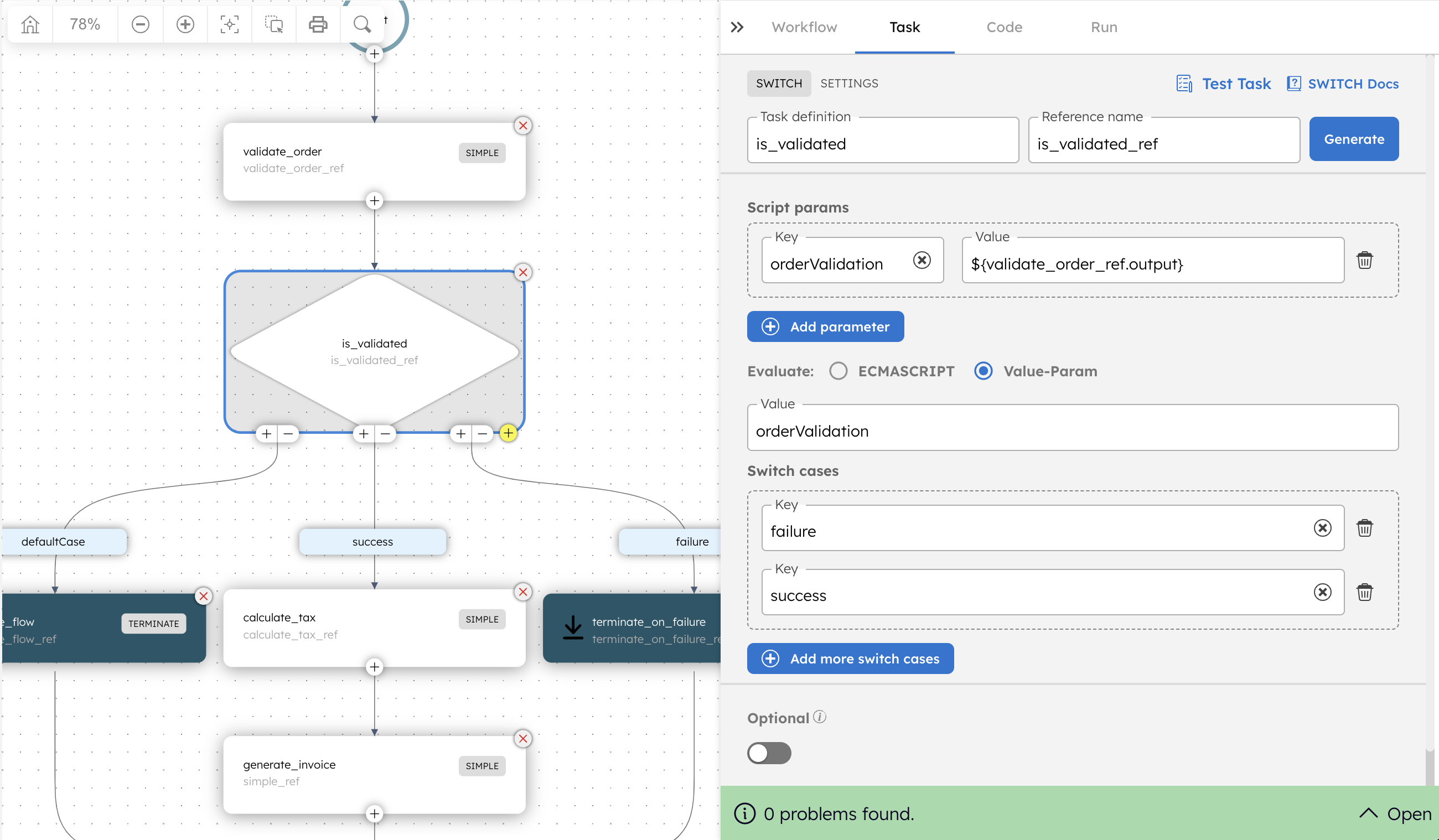
Each task can be defined in the orchestration layer. The definition enables developers to configure its execution capabilities, such as number of retries, timeouts, rate limits, and the expected inputs/outputs, which allows for reuse across multiple workflows.
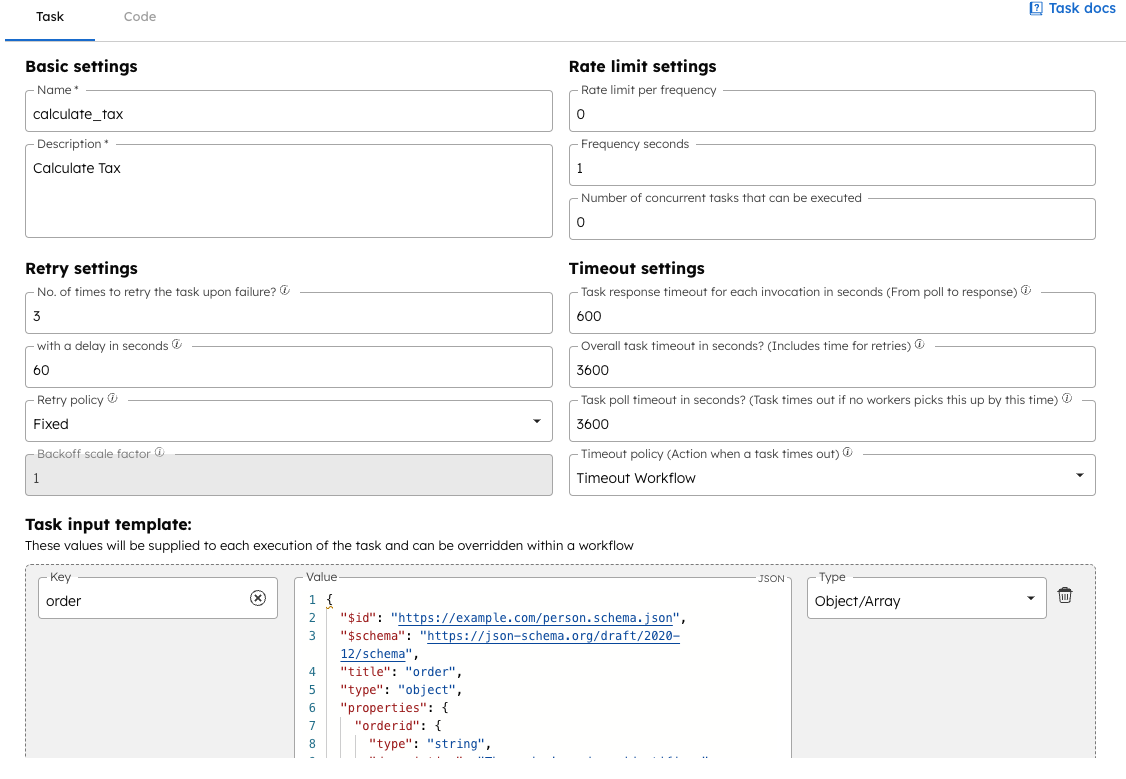
When a task is used in a workflow, it inherits the task’s base definition while the task inputs are wired from the workflow’s current state. In our order processing example, the tax calculation task is configured to take the initial workflow input, containing the order information, as its task input.
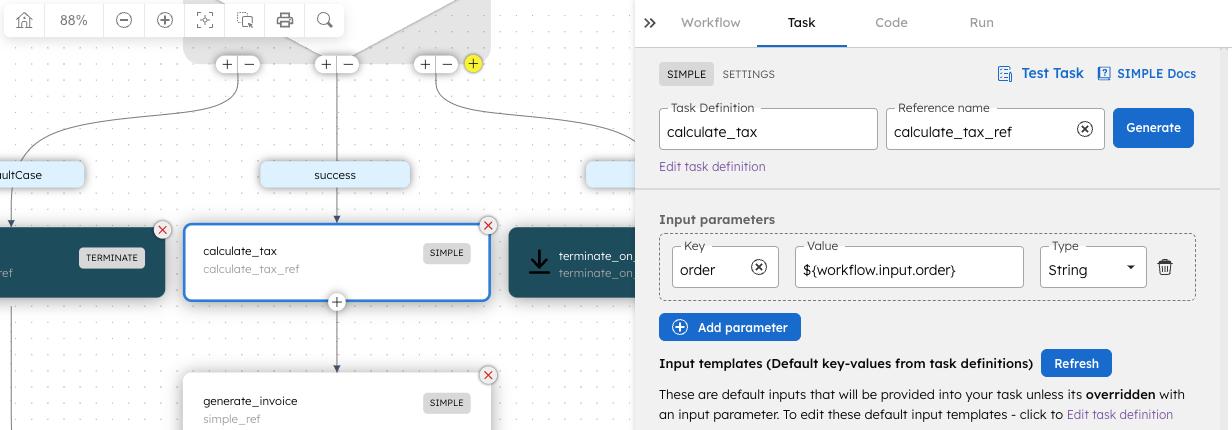
The workflow tasks can be any unit of logic, such as a microservice or API coded in any language, which get called by the orchestration layer when the execution reaches it. For example, when the orchestration layer calls the tax calculation task, the Python code below gets executed.
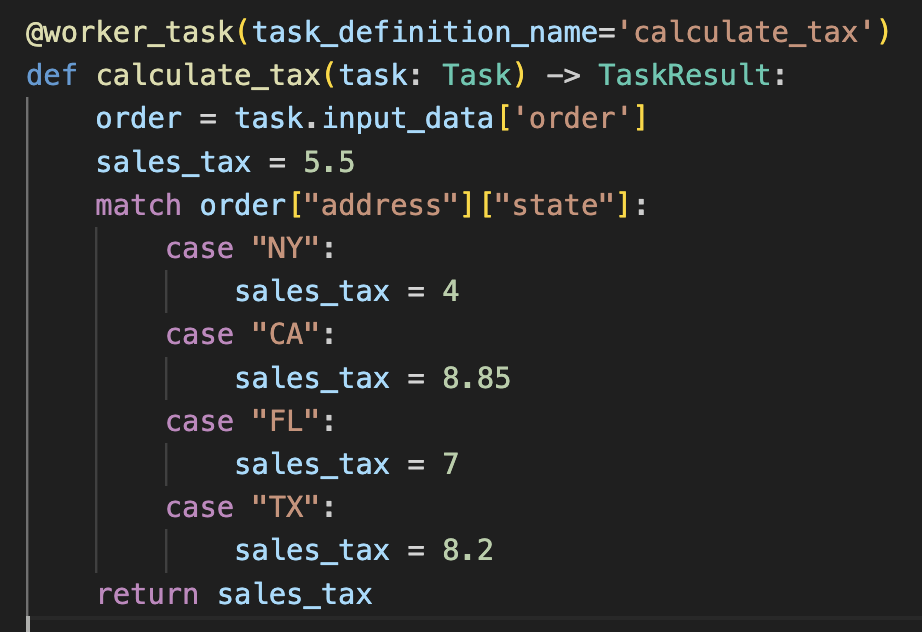
In Conductor, any existing function can easily become a task worker, facilitating the shift to using an orchestration layer in existing applications. For example, the Python task worker is defined by adding a @worker_task decorator and specifying a task object that contains all the task metadata such as the input values.
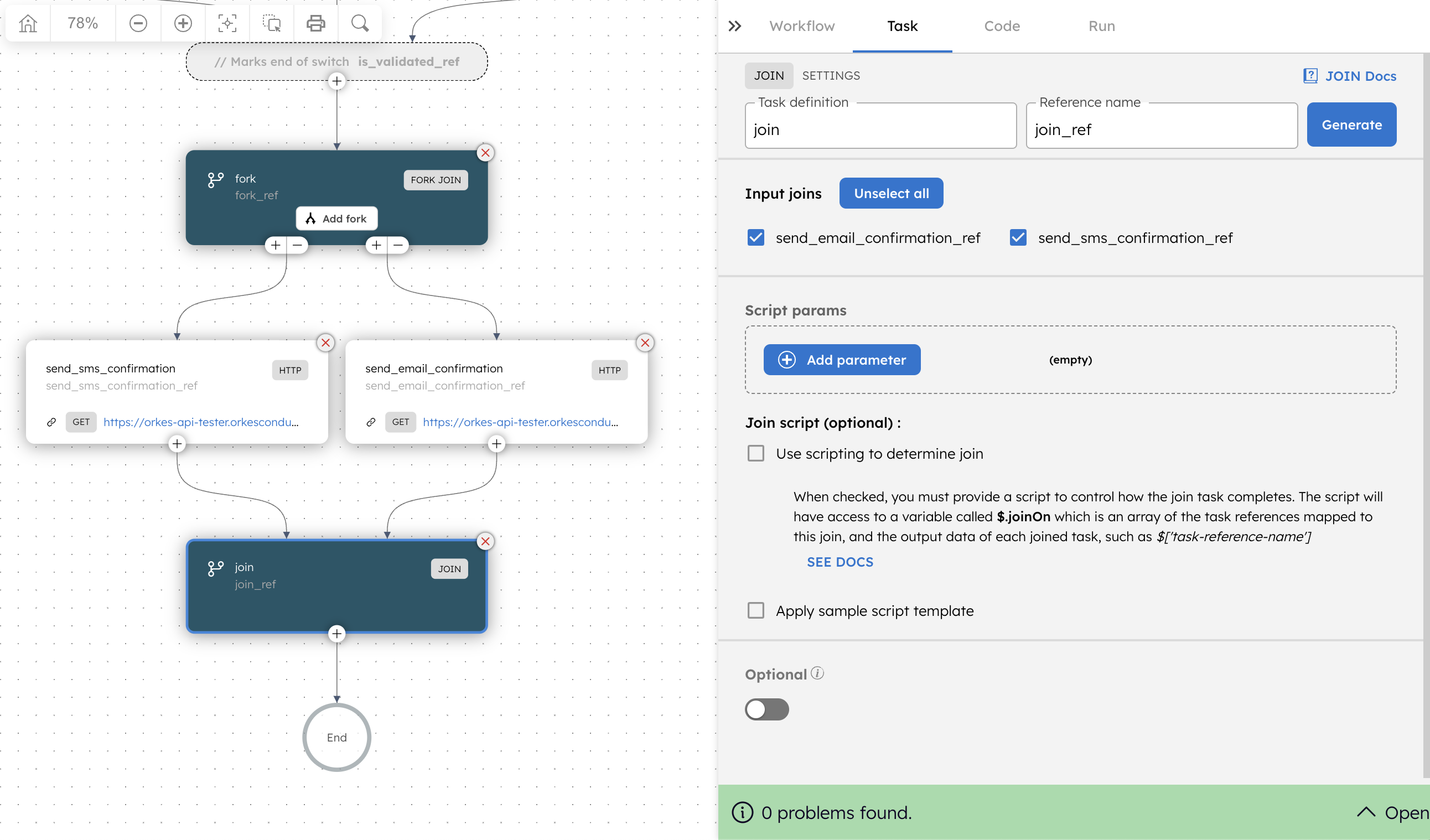
Lastly, all the order processing workflow runs two notification tasks in parallel using a Fork/Join task.
—
Conductor is an enterprise-grade orchestration platform for process automation, API and microservices orchestration, agentic workflows, and more. Check out the full set of features, try it yourself using our Developer Edition sandbox, or get a demo of Orkes Cloud, a fully managed and hosted Conductor service.


