ENGINEERING
Compensation Transaction Patterns - The Key to Handling Failures in Distributed Applications

Riza Farheen
Developer Advocate
Last updated: May 22, 2023
May 22, 2023
7 min read








Join thousands of developers building the future with Orkes.
As microservices architecture gains popularity, applications increasingly adopt the microservice approach. This approach involves breaking down the entire business flow into individual microservices that can be scaled and deployed independently.
While microservice architecture provides numerous benefits, it also puts forward unique challenges. One of the critical problems to be addressed with distributed systems is handling transactions that span multiple services, also referred to as distributed transactions.
Implementing a rollback mechanism is an elementary approach to handling such failures. A microservice-based application has different services for each of the business flows. If the application fails at a particular service, then all the previously completed services should be rolled back for the proper functioning of the application. This ensures that the application remains reliable and coherent, minimizing the impact of the failure.
You need a robust and reliable platform like Orkes Conductor to ensure your application has a perfect rollback mechanism. Orkes Conductor, built over the battle-tested Netflix Conductor, is a modern app-building platform that helps in building distributed applications 10x faster.
In this blog post, we will explore how Orkes Conductor facilitates the setup of a rollback mechanism for handling failures in distributed applications.
Unlike in monolithic applications, where all the components typically share a single database, a microservice architecture is designed so that each service has individual databases. So, the developer has the supreme authority to choose the technology over different databases.
For instance, one service can use PostgreSQL while another service uses MySQL. This approach is called "Database per Service" in a microservice architecture.
In a database-per-service pattern, each service is responsible for its own database and executes sequential operations to complete the entire transaction of the application. The whole transaction that happens over the distributed system is referred to as Distributed Transaction.
There are different ways to handle the database transactions, such as local ACID and 2PC.
ACID (Atomicity, Consistency, Isolation, Durability) transaction guarantees that each transaction fulfills the ACID properties.
In a distributed transaction involving multiple databases, the traditional ACID properties of transactions may not be an ideal fit due to several reasons:
Another widely used pattern for distributed transactions is the 2PC protocol.
2PC is a protocol where the transaction is completed in 2 different phases, namely, prepare phase and the commit phase.
To understand the concept, let’s take an example of an e-commerce application:
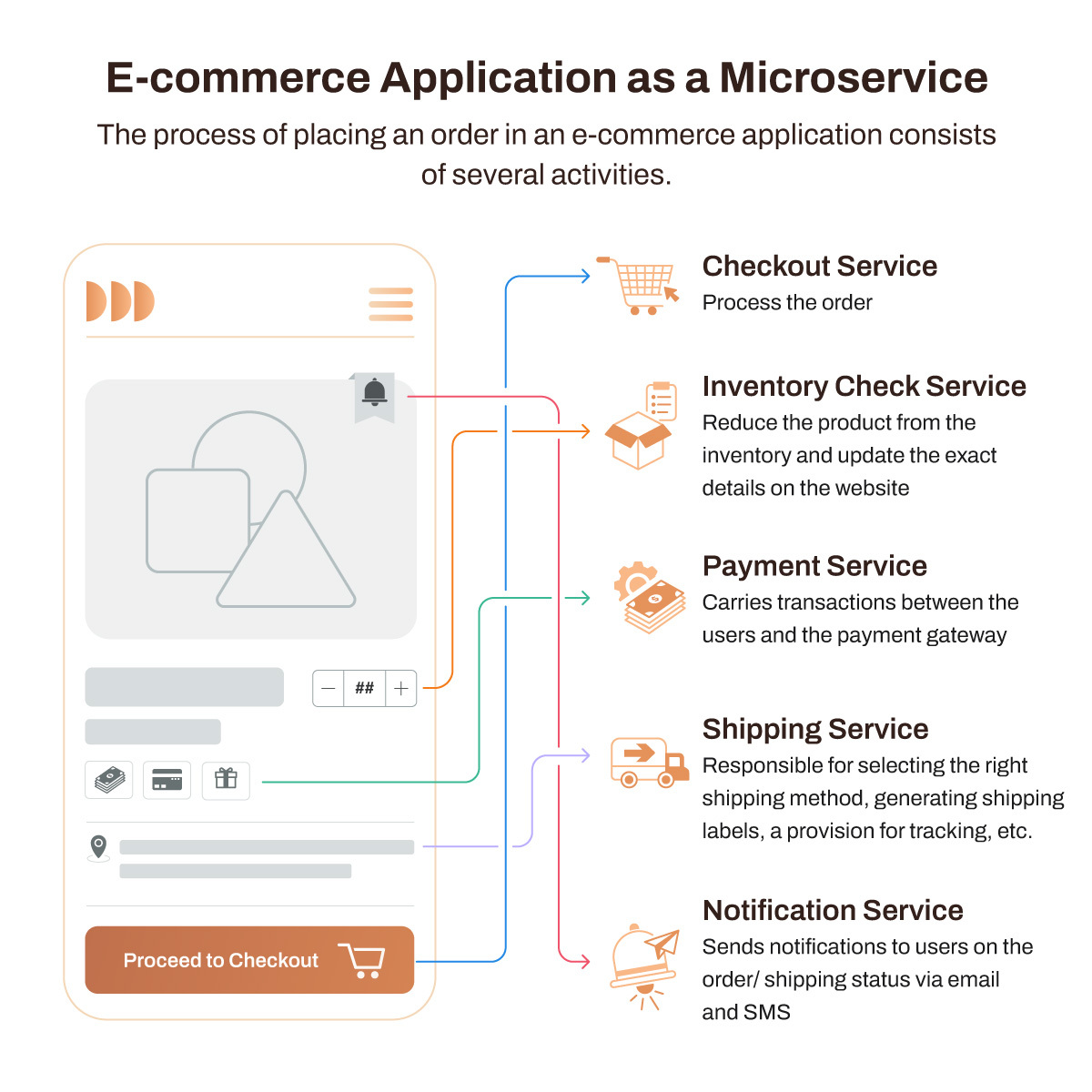
Now let’s see how the transaction between the microservices takes place in the 2PC protocol:
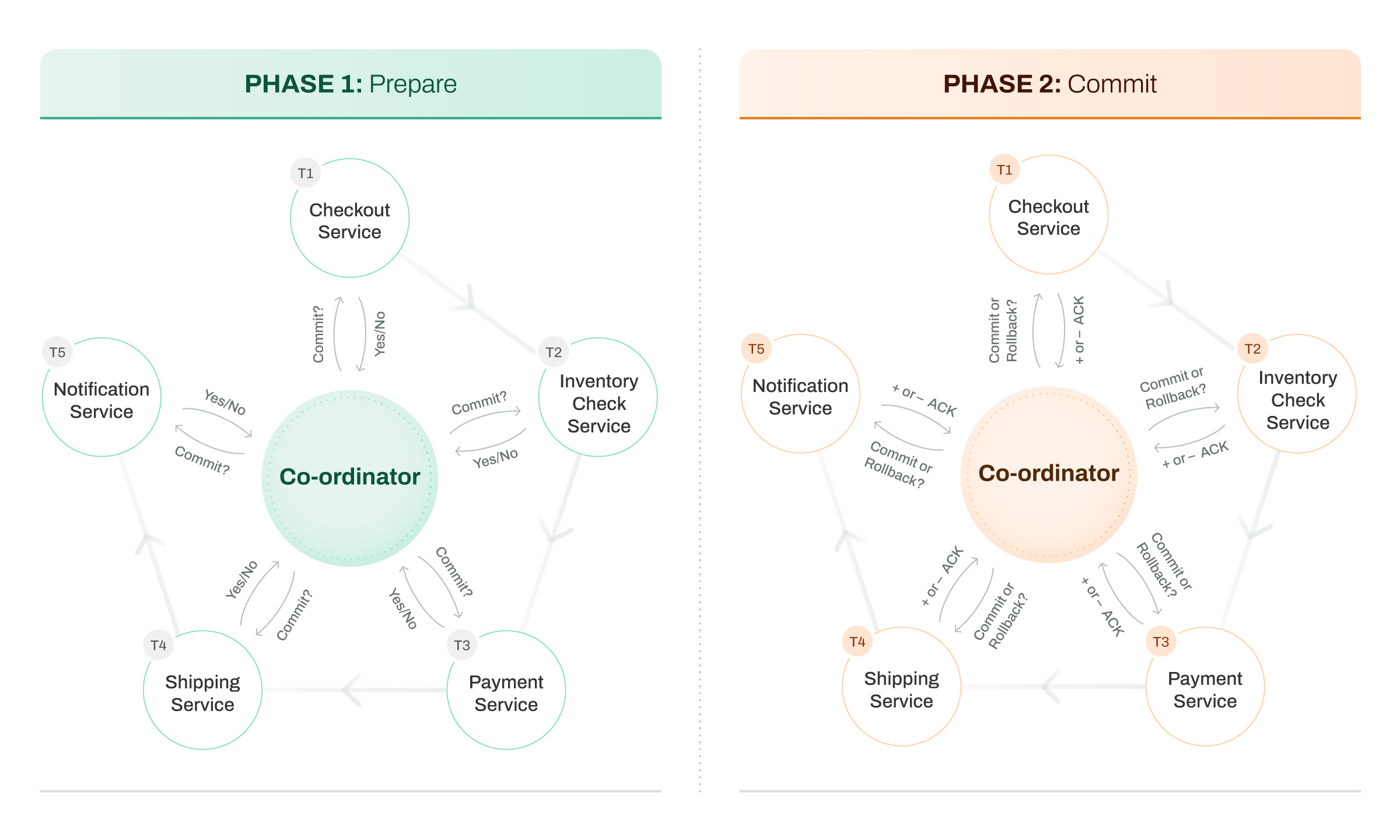
In the prepare phase, there is a central coordinator and participating nodes. The participating nodes are nothing but microservices. In this phase, the coordinator checks whether the microservices are ready or not to commit. The microservices can respond with a yes/no.
If all the microservices agree to commit, the transaction enters the next phase, the commit phase. In this phase, all the microservices are notified to commit the transactions, and if any of them fails, the coordinator issues a rollback command to all the preceded completed microservices.
However, 2PC has several disadvantages, such as all the services should wait until the slowest service finishes its transaction, which can lead to a further increase in the app deployment time.
So, how do we implement the transactions in a distributed application to overcome all these challenges?
That’s where the Saga pattern comes in.
The Saga pattern, introduced in 1987 by Hector Garcia Molina & Kenneth Salem, defines the saga pattern as a sequence of transactions that can be interleaved with one another. In this pattern, the coordinator ensures that all the individual transactions are completed successfully, and in case of failures, compensating transactions are run on all previously completed transactions. So, every transaction can be rolled back using a compensating transaction.
Let’s look at the e-commerce application example:
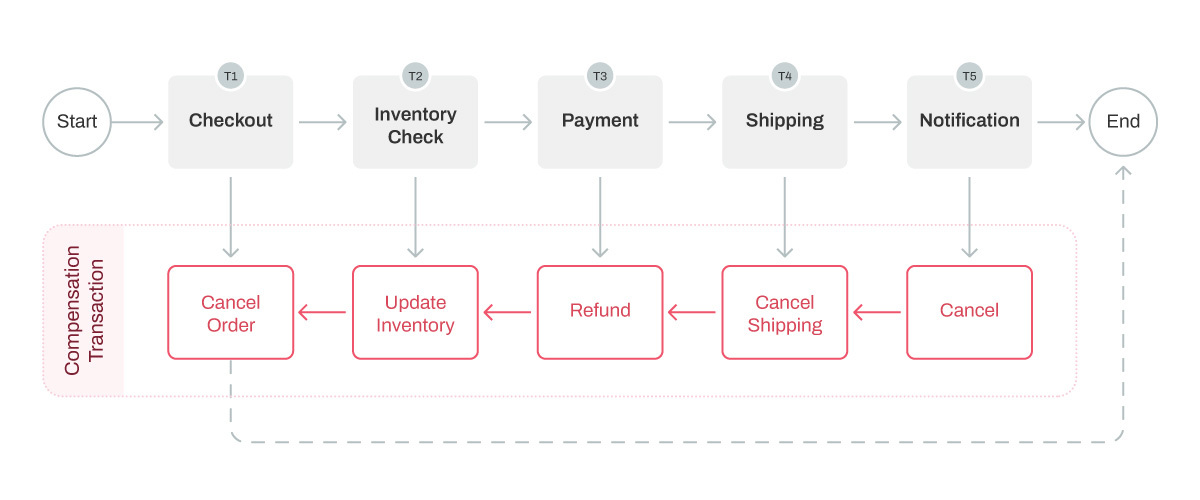
In order to maintain the consistent state of the application, the saga pattern includes a Saga Execution Controller (SEC), which consists of a log that captures the sequences of events in a distributed application.
The SEC component plays a crucial role in identifying failures within the event sequence and executing the necessary rollback transactions. The advantage of the Saga pattern over other patterns is that a failure in the SEC component will not affect the functioning of the application. After recovering from the failure, the SEC component can query the saga log to identify the rollback transactions that occurred and to act accordingly.
The saga pattern can be implemented based on the Choreography or Orchestration approach. The choreography pattern has many pitfalls and is more suitable for scenarios with a small number of microservices. On the other hand, the saga orchestration pattern ensures that a single coordinator is responsible for managing the overall transaction status.
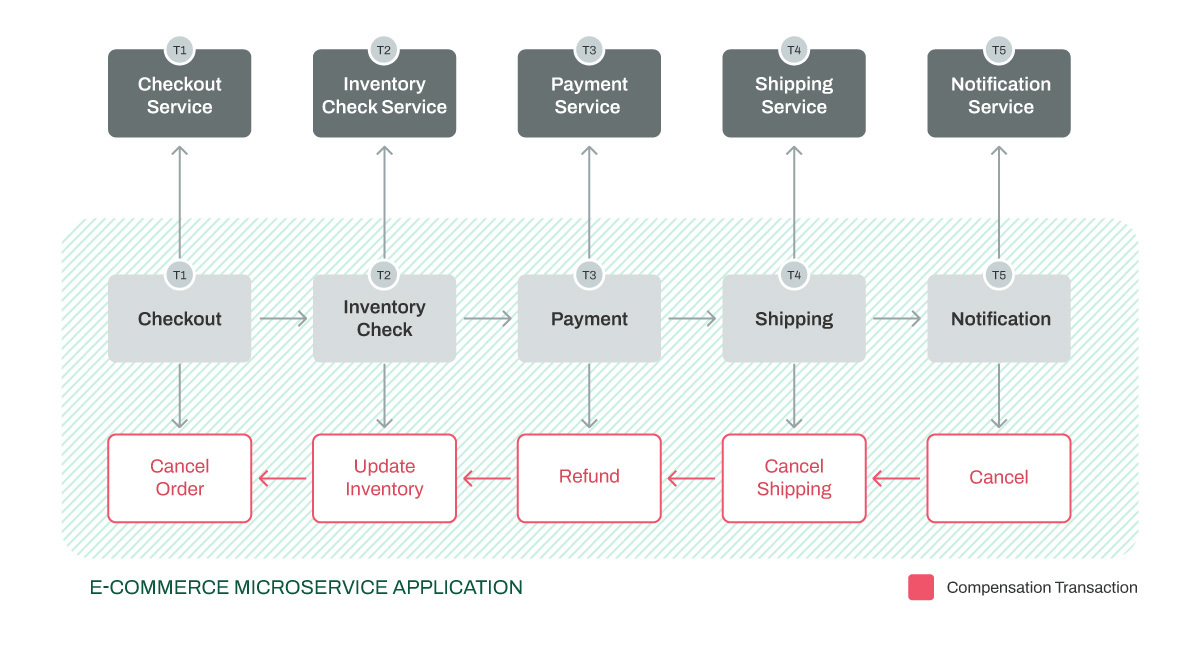
In this example, if the payment fails, the centralized coordinator ensures that the compensation transactions take place to reverse payment, update inventory, and cancel the order. This way, the application is consistent, and no situations arise, like payments failing but orders still being placed.
Therefore, it becomes evident that the saga pattern serves as a solution to address the challenges faced in distributed transactions.
For the smooth functioning of your application, it is essential to implement a compensation mechanism. Orkes Conductor implements the compensation mechanism using the orchestration pattern.
You can achieve this using the failureWorkflow functionality in Conductor. The applications are built as workflows in Conductor. While creating a workflow definition, you can specify a failure workflow, which will be triggered if the main workflow fails. The failure workflow receives the failed workflow’s ID and tasks as input, enabling you to implement compensating logic to handle the failure.
An example would look like this:
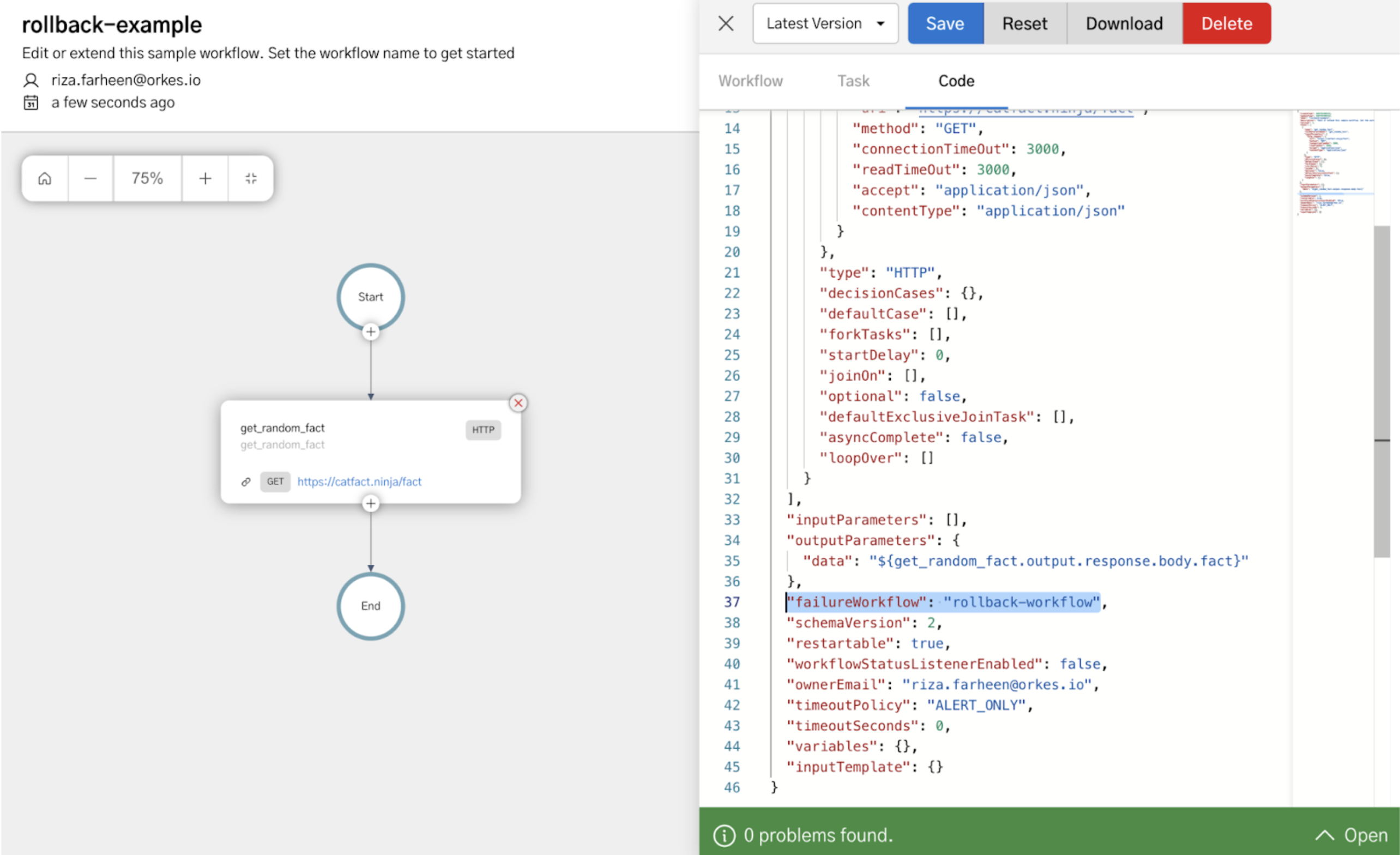
Here, if the workflow “rollback_example” fails, the failure workflow “rollback_workflow” will be triggered.
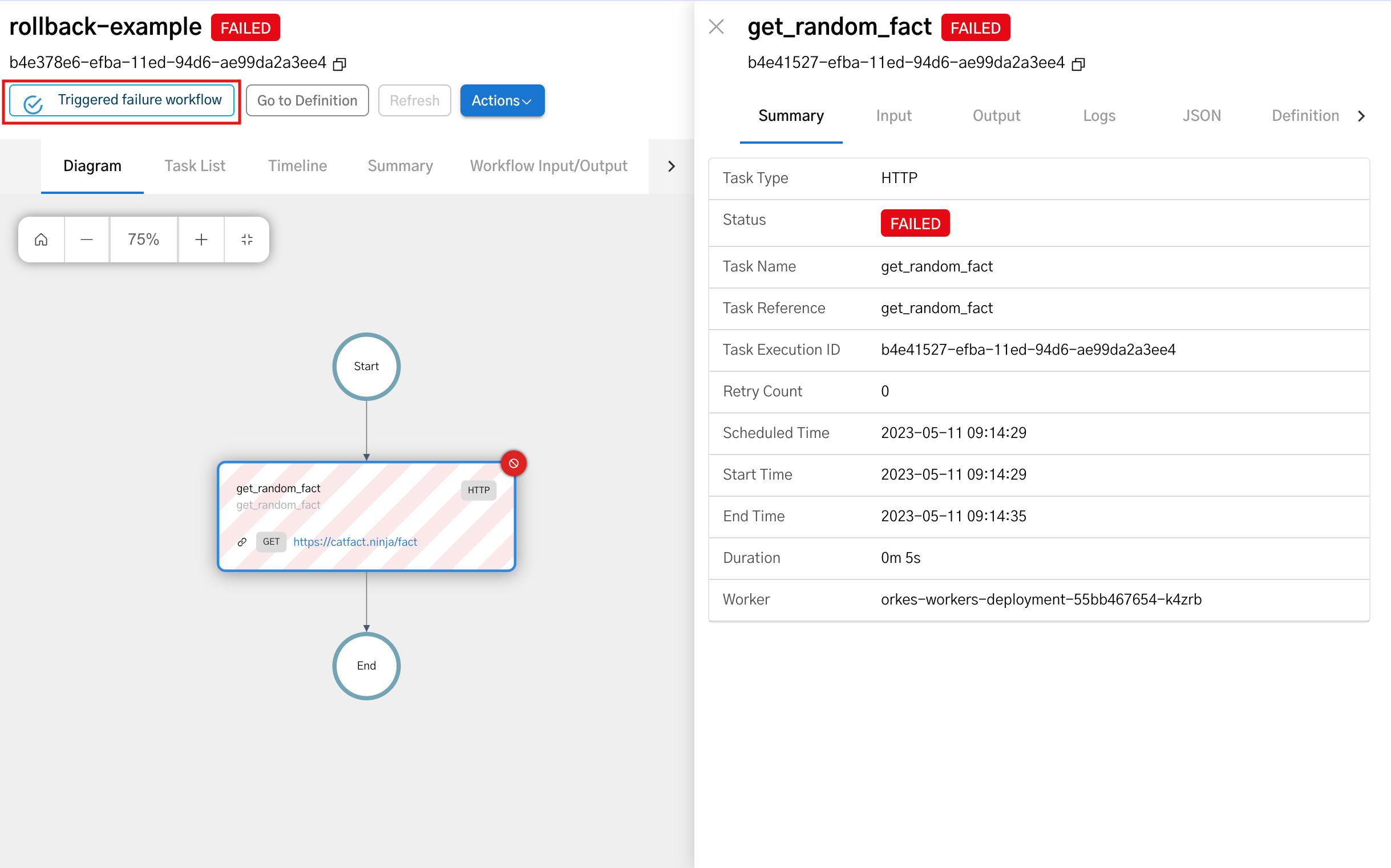
You can see from the UI that the failure workflow has been triggered. This acts as the compensation workflow to restore the changes.
In the e-commerce application example we discussed, we can call each service as individual sub-workflows, where each sub-workflow can have the corresponding failure workflow.
It is imperative that compensation patterns play an integral role in the seamless management of failures in distributed applications. These frameworks are essential for resolving unforeseen circumstances and recovering from failures, guaranteeing applications' integrity and reliability.
Have you considered exploring Orkes Conductor - a powerful solution for building distributed applications, along with the capability of managing compensation patterns?
Feel free to join our vibrant Slack community if you have any queries or require assistance.