SOLUTIONS
Data Processing with Conductor
Orkes Team
Developer Relations
Last updated: May 12, 2022
May 12, 2022
5 min read








Join thousands of developers building the future with Orkes.
Data processing and data workflows are amongst the most critical processes for many companies today. Many hours are spent collecting, parsing and analyzing data sets. There is no need for these to repetitive processes to be manual - we can automate them. In this post, we'll build a Conductor workflow that handles ETL (Extraction, Transformation and Loading) data for a mission critical process here at Orkes.
As a member of the Developer Relations team here at Orkes, we use a tool called Orbit to better understand our users and our community. Orbit has a number of great integrations that allow for easy connections into platforms like Slack, Discord, Twitter and GitHub. By adding API keys from the Orkes implementations of these social media platforms, the integrations automatically update the community data from these platforms into Orbit.
This is great, but it does not solve all of our needs. Orkes Cloud is based on top of Conductor, and we'd like to also understand who is interacting and using that GitHub repository. However, since Conductor is owned by Netflix, our team is unable to leverage the automated Orbit integration.
However, our API keys do allow us to extract the data from GitHub, and our Orbit API key can allow us to upload the extracted data into our data collection. We could do this manually, but why not build a COnductor workflow to do this process for us automatically?
In this post, I'll give a high level view of the automation required for Extraction of the data from GitHub, Transformation the data to a form that Orbit can accept, and then to Load the data into our Orbit collection.
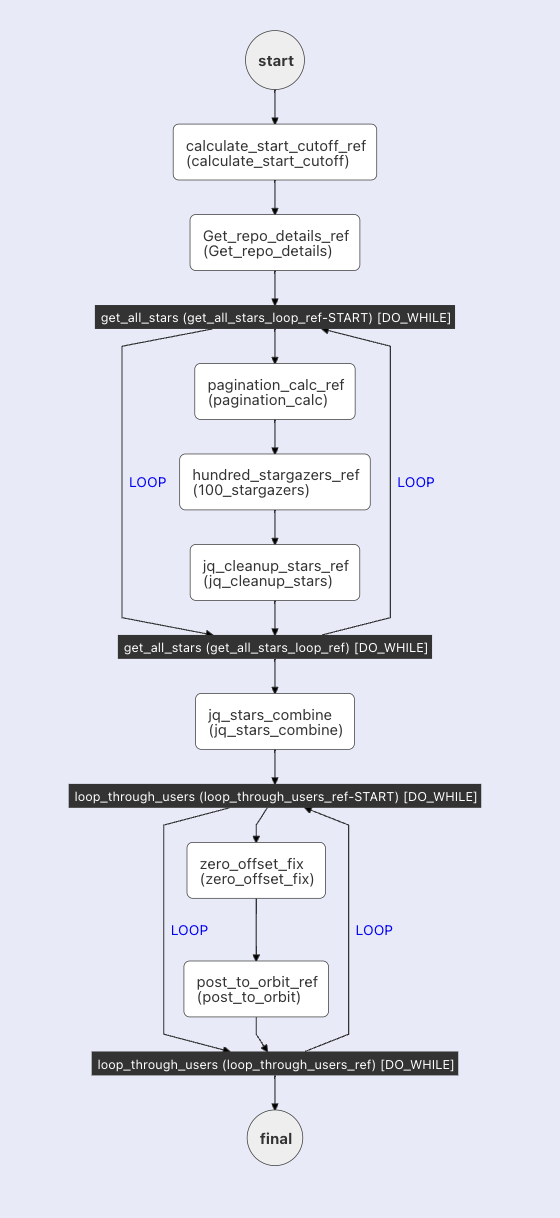
We'll go into the nitty gritty details of all the tasks in our next post, sp let's look at what our Conductor workflow does to Extract, Transform and Load our data from GitHub into Orbit at a high level:
There are APIs from GitHub that allow us to extract the "stargazers" (those who have starred the Conductor repository) and contributors to Netflix Conductor. The API allows us to extract 100 users at a time, so we will leverage the DO/WHILE loop to get as many users as we need. This requires an API key from GitHub.
The data from GitHub is much more information that what we need to upload to Orbit. We can use JQ transform and INLINE JavaScript tasks to transform the data extracted from GitHub into the JSON format required for Orbit.
Upload the data into Orbit. This requires an API key from Orbit.
There are a bunch of additional steps to make it all work, and the resulting workflow looks like:
The workflow input has a number of parameters that are required for the workflow to run:
{
"gh_account": "netflix",
"gh_repo": "conductor",
"star_offset": 3800,
"gh_token": "<github_api_key>",
"orbit_workspace": "oss-stats",
"activity_name": "starredConductor",
"orbit_apikey": "<orbit_api_key>"
}
gh_account and gh_repo are the account and repository to extract the data from - in this case netflix/conductor.gh_token GitHub limits the number of API calls without a token, so I created a token to allow more frequent requests.orbit_workspace This is the workspace in orbit where the data will be uploaded.activity_name We are creating an activity in Orbit for the action taken. Since this is a list of people who have starred Conductor, starredConductor seems a good name,orbit_apikey we also need an api key to upload into our Orbit account.This workflow is amazing and saves loads of time, but the workflow must be run in order for the data to appear in our Orbit data set.
This is where the new Orkes workflow scheduler comes in. By scheduling this workflow to run every 24 hours, we can ensure that every new Star and GitHub fork for the Conductor repository is being accounted for, and that the data in Orbit is accurate and up to date (within 24 hours). There is an additional task to filter the GH data to only stars that occurred in the last 24 hours.
The new Scheduler tool makes it easy to set up a recurring schedule for a workflow. In this case, it is run daily at midnight GMT.
There are several other open source workflow orchestration platforms, and we wanted to do some analysis on who has starred more that one of these competing platforms. Using this workflow as a Sub workflow we can query multiple repositories at once:
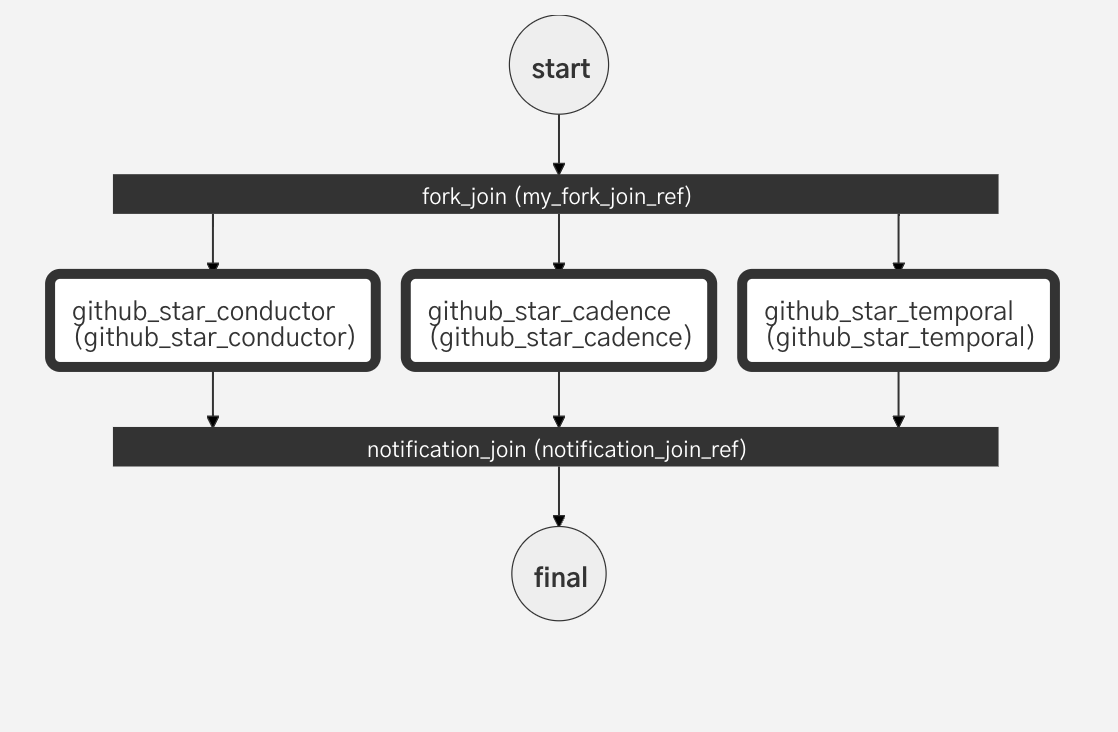
By adding additional terms to the input, we can aggregate all of the stars from all three repos, and collect them in another orbit instance. Scheduling this workflow ensures that this additional dataset is regularly updated and data from all three repositories are in sync.
With a Conductor workflow we are able securely perform an ETL process: Extracting data from GitHub, Transforming the data via JQ transforms and then Loading the data into Orbit.
Conductor is an enterprise-grade orchestration platform for process automation, API and microservices orchestration, agentic workflows, and more. Check out the full set of features, try it yourself using our Developer Edition sandbox, or get a demo of Orkes Cloud, a fully managed and hosted Conductor service.