ENGINEERING
Guide to Prompt Engineering

Riza Farheen
Developer Advocate
Last updated: June 27, 2024
June 27, 2024
7 min read








Join thousands of developers building the future with Orkes.
This is part one of a series exploring prompt engineering, what it is, its significance in app development, and how to build LLM-powered applications effectively.
The AI landscape underwent a transformative change with the public release of OpenAI’s GPT-3 model in late 2022, opening up a world of possibilities and sparking widespread experimentation.
One of the most critical aspects of leveraging GPT-3 and similar models lies in the art of creating prompts. Crafting precise and well-defined prompts is essential; a sloppy prompt can lead to irrelevant or meaningless outputs, limiting AI applications' potential. As users navigated the early days of GPT-3 experimentation, they quickly recognized that the key to unlocking the full capabilities of these models lies in writing well-crafted prompts.
This blog explores the fundamentals of prompt engineering and its crucial role in application development and provides insights into interacting with and building LLM-based applications.
Prompt engineering is an emerging engineering discipline defined as the practice of writing inputs for AI tools to produce desirable outputs.
Before delving into the fundamentals of prompt engineering, let’s take a look at what prompts are.
A prompt is an input or question you provide to an AI model like ChatGPT. For example, when you initially used ChatGPT, the questions you asked were your prompts. Sometimes, the initial prompt might not yield the desired result, so you refine it by providing clearer instructions and setting specific expectations. This improved prompt might have helped in getting a better response.
In this context, better inputs to a model can produce better results. Therefore, prompts are the inputs provided to AI models, and prompt engineering is the practice of crafting these prompts effectively.
While prompt engineering is relatively new, its origins can be traced back to the history of Natural Language Processing (NLP). NLPs are subcategories of Artificial Intelligence (AI) that specifically address how computers interact with human language. Within NLP, large language models (LLMs) represent a significant advancement in Generative AI (GenAI). These models are trained on millions and trillions of data, enabling them to generate something new based on given inputs.
Effective prompts are vital in prompt engineering. The prompts guide the GenAI models in creating relevant and accurate responses that align with the user's expectations. This helps users interact with GenAI models more intuitively, creating a smoother experience.
AI-based applications are increasingly dominating the market compared to conventional applications as businesses evolve by incorporating AI-powered components into their applications. A critical aspect of these AI-powered applications is their ability to communicate effectively with large language models (LLMs). This communication is facilitated through the creation of effective prompts.
Prompt engineering can be integrated into AI-powered applications for better user interactions:
Next, let's explore how these prompt engineering techniques can be implemented in AI app development.
During prompt design, the outputs generated can vary significantly depending on the specific parameters configured for the LLM.
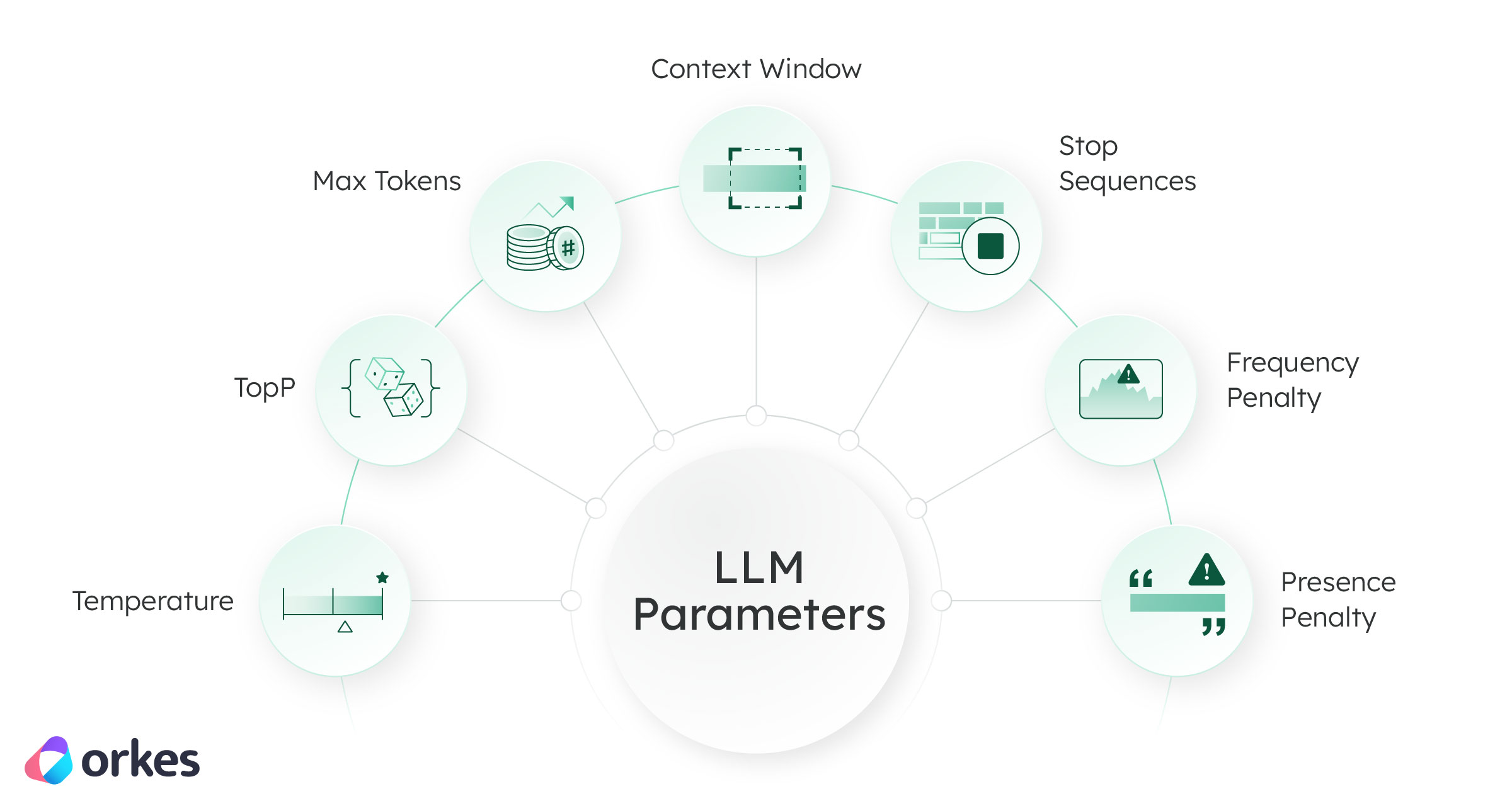
Here are the common LLM parameters you may encounter while using different providers.
Temperature
Temperature indicates the randomness of the model’s output. A higher temperature makes the output more random and creative, whereas a lower temperature makes the output more stable and focused. Higher temperatures can be used for generating creative content, such as social media posts or drafting emails. Lower temperatures are better suited for use cases like text classification, which require a more focused output.
TopP
TopP, also known as nucleus sampling, allows the prompt engineer to control the randomness of the model’s output. It defines a probability threshold and selects tokens whose cumulative probability exceeds this threshold.
Max Tokens
Max token determines the maximum number of tokens to be generated by the LLM and returned as a result. This parameter helps prevent long or irrelevant responses and controls costs. In contrast, the Temperature and TopP parameters help define the output's randomness, while they don’t limit its size.
Context Window
Content window determines the number of tokens the model can process as inputs when generating responses. Increasing the context window size enhances the performance of LLMs. For example, GPT-3 handles up to 2,000 tokens, while GPT-4 Turbo extends this to 128,000 tokens, and Llama manages 32,000 tokens. As of the latest update, Google's Gemini 1.5 Pro ships with a default context window size of 128,000 tokens, with plans to allow a selected group of developers and enterprise customers to experiment with a context window of up to 1 million tokens through AI Studio and Vertex AI in a private preview phase.
Stop Sequences or Stop Words
Stop sequences (also known as stop words) help prevent the model from generating content containing specific sequences, such as profanity or sensitive information.
Frequency Penalty and Presence Penalty
Frequency penalty is a parameter used to discourage LLM models from generating frequent words, thereby helping to prevent repetitive text. On the other hand, the presence penalty encourages LLM models from generating words that have not been recently used.
LLM parameters are crucial in creating effective prompts, which are integral to developing AI-based applications. Adjusting these parameters ensures that the LLMs produce the desired outcomes. Therefore, understanding and carefully configuring these parameters is essential for prompt creation.
We have covered some basic LLM parameters. Now, let's look into key considerations for crafting effective prompts.

Before crafting the prompt, it's crucial to clearly understand its purpose. Are you seeking information, encouraging creativity, or solving a specific problem? Understanding this ensures the prompt aligns with your goals.
Clear and precise instructions are key to eliciting useful responses. When creating a prompt:
Before finalizing, it's important to test the prompt to ensure it effectively guides the models toward the desired outcome. Fine-tuning may be necessary based on initial responses.
Let’s contrast generic examples of good and bad prompts in real-life scenarios:

The first prompt generated generic breakfast ideas without specific details on ingredients and preparation steps. In contrast, the second prompt included clear instructions, such as preferring Lebanese food, noting an egg allergy, and requesting easy preparation within 30 minutes. As a result, the responses were well crafted to suit these requirements.
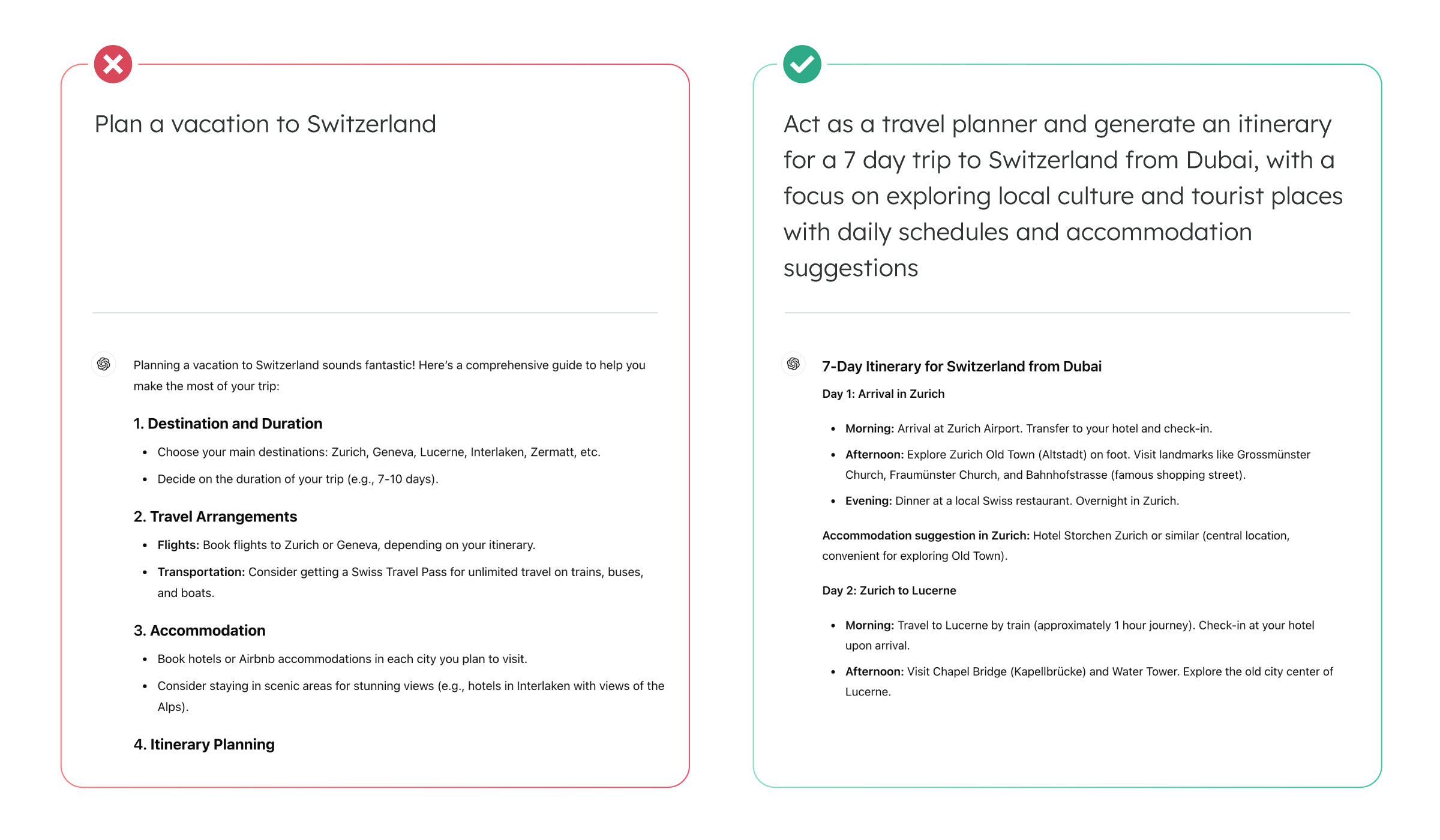
The first prompt provided a generic plan, while the second offered a detailed itinerary tailored to the specific requirements.

The first prompt is a generic request for CSS code to align elements when building an HTML-based website. In contrast, the second prompt provides specific context, outlines the issues encountered, and requests a resolution.
A good prompt provides clear context, issues, and expectations:

Having explored the fundamentals of prompts and best practices for creating them, it's time to dig deeper into how orchestration tools like Orkes Conductor streamline the process of building LLM-powered applications by orchestrating the interaction between distributed components.
Let’s say we have an existing application and want to plug in AI features. This can be achieved using Orkes Conductor through the following steps:
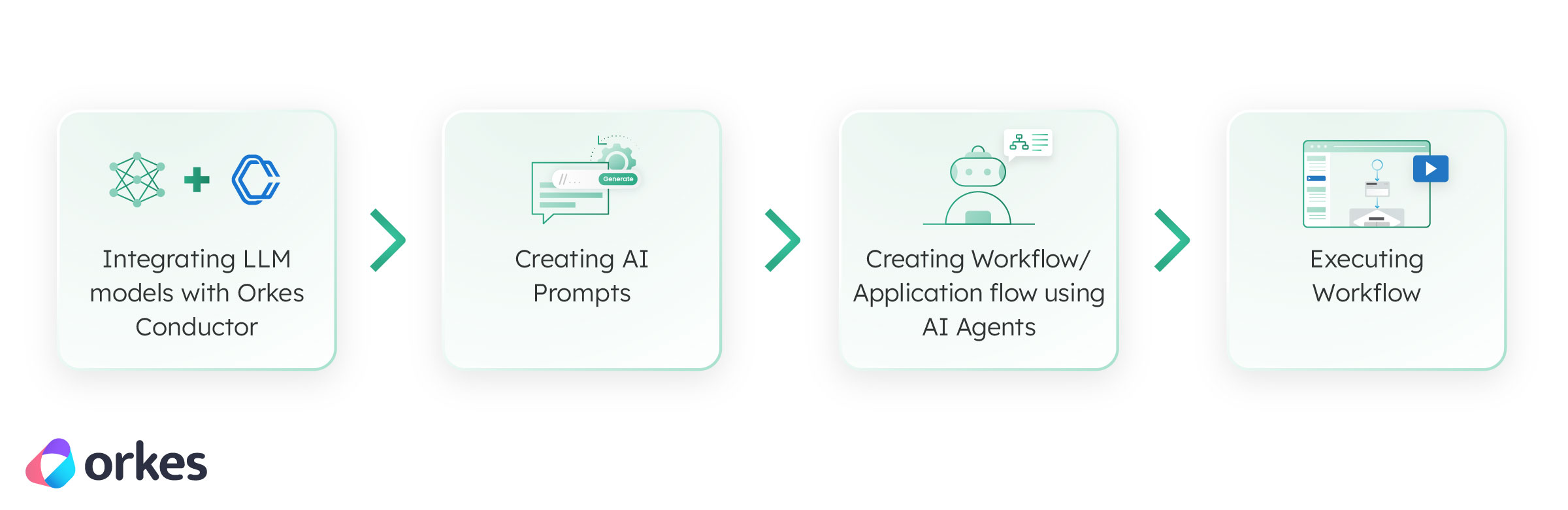
The initial step involves integrating LLM models with Orkes Conductor. Orkes Conductor facilitates integration with various LLM providers and their hosted models, such as OpenAI, Azure Open AI, Vertex AI, Gemini AI, AWS Bedrock, etc. Furthermore, the integration also includes Vector Databases such as Pinecone, Weaviate, MongoDB, etc.

The subsequent step involves creating AI prompts within Orkes Conductor. These prompts can be created and stored directly within the Conductor console. They include an interface for real-time testing, allowing for iterative refinement of prompts before integrating into workflows.
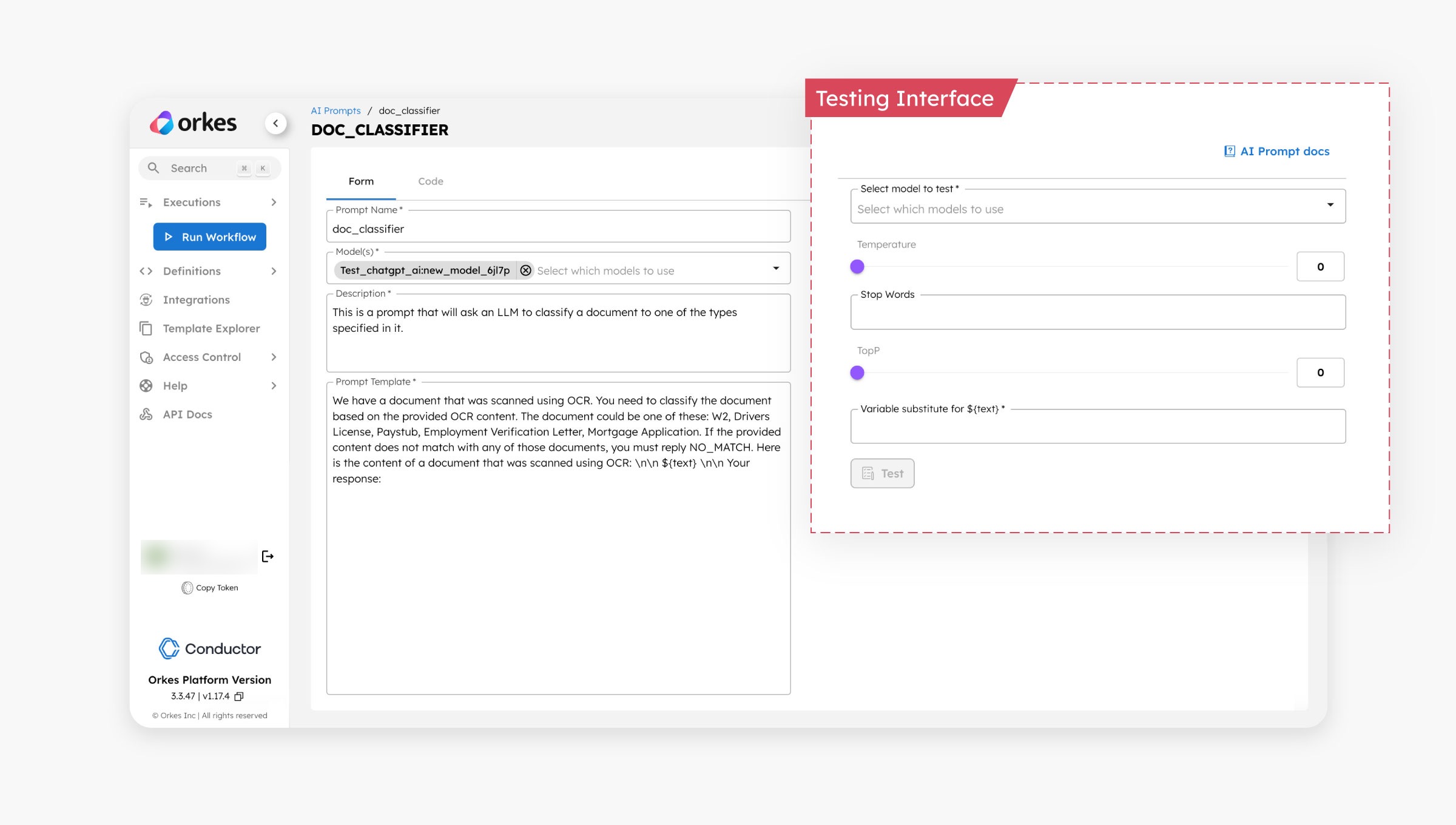
The AI prompts can also be stored as a prompt library in Orkes Conductor, which developers can later leverage when building AI-powered applications.
Once the LLM model integration and prompts are set up, the subsequent step involves creating a workflow using AI agents in Orkes Conductor. These AI agents currently support tasks like text or chat completion, generating embeddings, retrieving embeddings, indexing text/documents, conducting searches within indexes, etc. Depending on the application's specific needs, LLM tasks can be incorporated into the workflow.
The final step is to execute the workflow. This can be initiated through various methods such as code execution, APIs, Conductor UI, schedulers, or Webhook events. Additionally, workflows can be triggered in response to events from external systems like Kafka, SQS, and others.
In this guide, we've explored the essentials of prompt engineering and its significance in app development. Prompt engineering, as an emerging discipline, plays a critical role in ensuring effective communication between users and AI models. By understanding the basics of prompts, their parameters, and best practices for crafting them, developers can easily create more intuitive and responsive AI-driven applications with Orkes Conductor.
As AI continues to evolve, mastering prompt engineering will become increasingly vital for developers aiming to integrate AI capabilities into their applications. Check out Part 2 of this series, where we dive into experimenting and putting prompt engineering tactics into practice.
–
Conductor is an enterprise-grade orchestration platform for process automation, API and microservices orchestration, agentic workflows, and more. Check out the full set of features, try it yourself using our Developer Edition sandbox, or get a demo of Orkes Cloud, a fully managed and hosted Conductor service.