ENGINEERING
Time to Finally Understand Orchestration vs. Choreography

Maria Shimkovska
Content Engineer
Last updated: October 3, 2025
October 3, 2025
8 min read








Join thousands of developers building the future with Orkes.
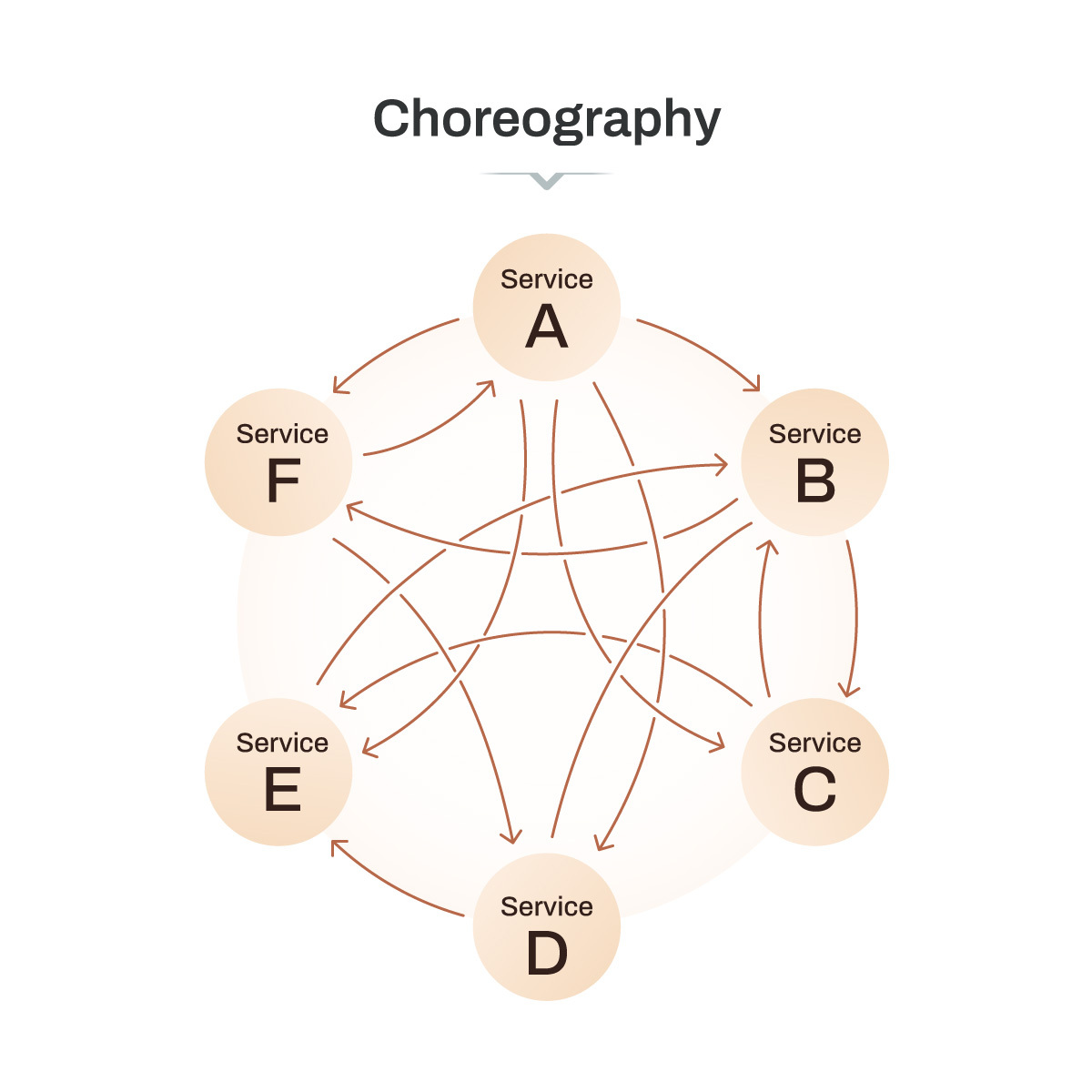
Orchestration has a central boss. Choreography doesn't.
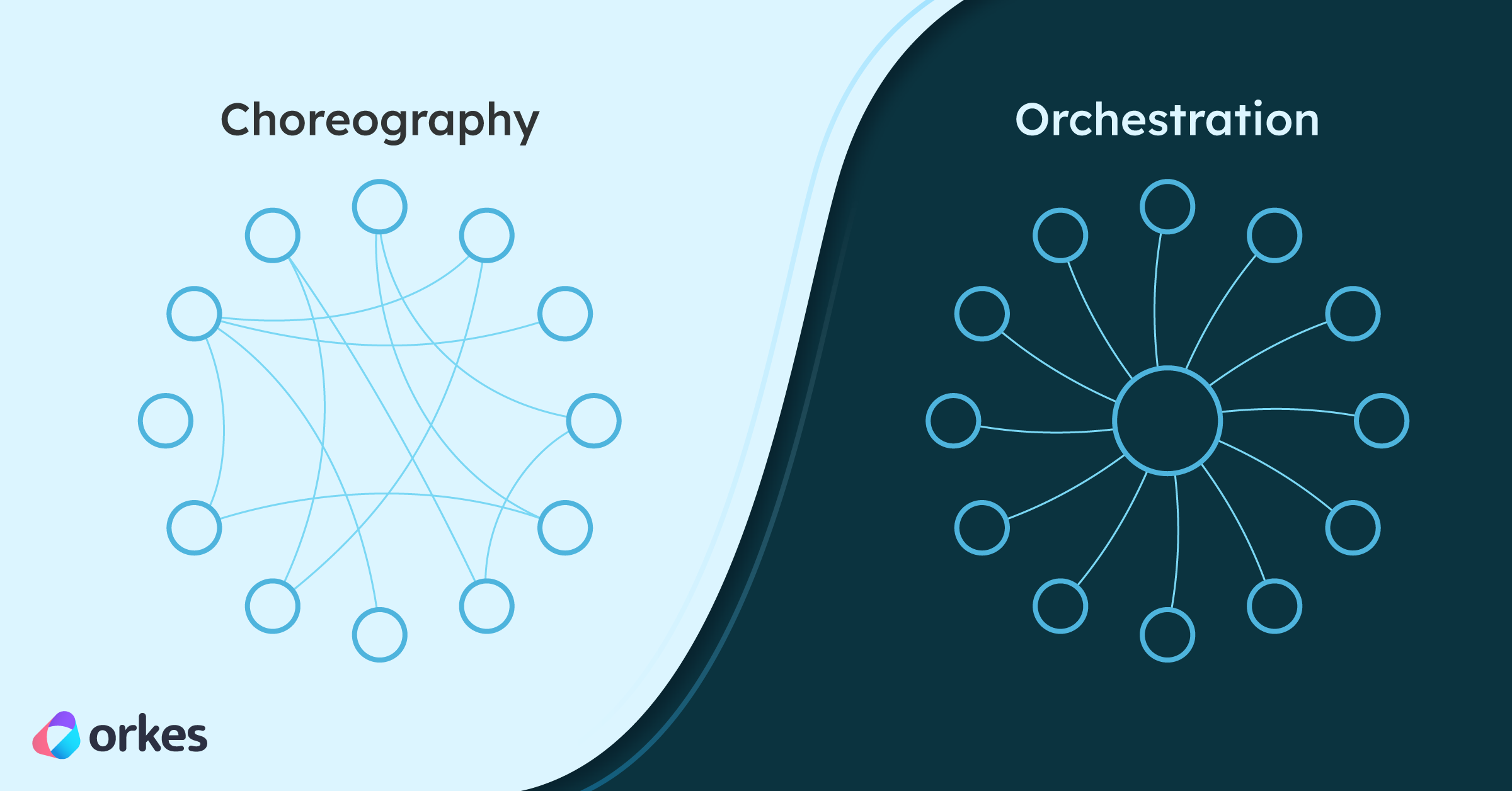
Quick Answer: It’s about who controls the flow.
I’ve been working with microservices for years, but funny enough, the terms orchestration and choreography never really came up in casual conversations or even during planning sessions. The technical jargon was kind of relegated to the background.
When systems move from a monolith to microservices, the hardest part is figuring out how to coordinate the work that needs to be done among them. Orchestration and choreography are the two main patterns for this, but the internet is still full of confusing definitions on both terms (in my mere human opinion).
So I already mentioned that both orchestration and choreography are two ways to set up communication between services. They’re basically how different services in a system talk to each other and get stuff done. In a microservices setup, where everything is split into smaller parts, these approaches explain how those parts work together like a team.
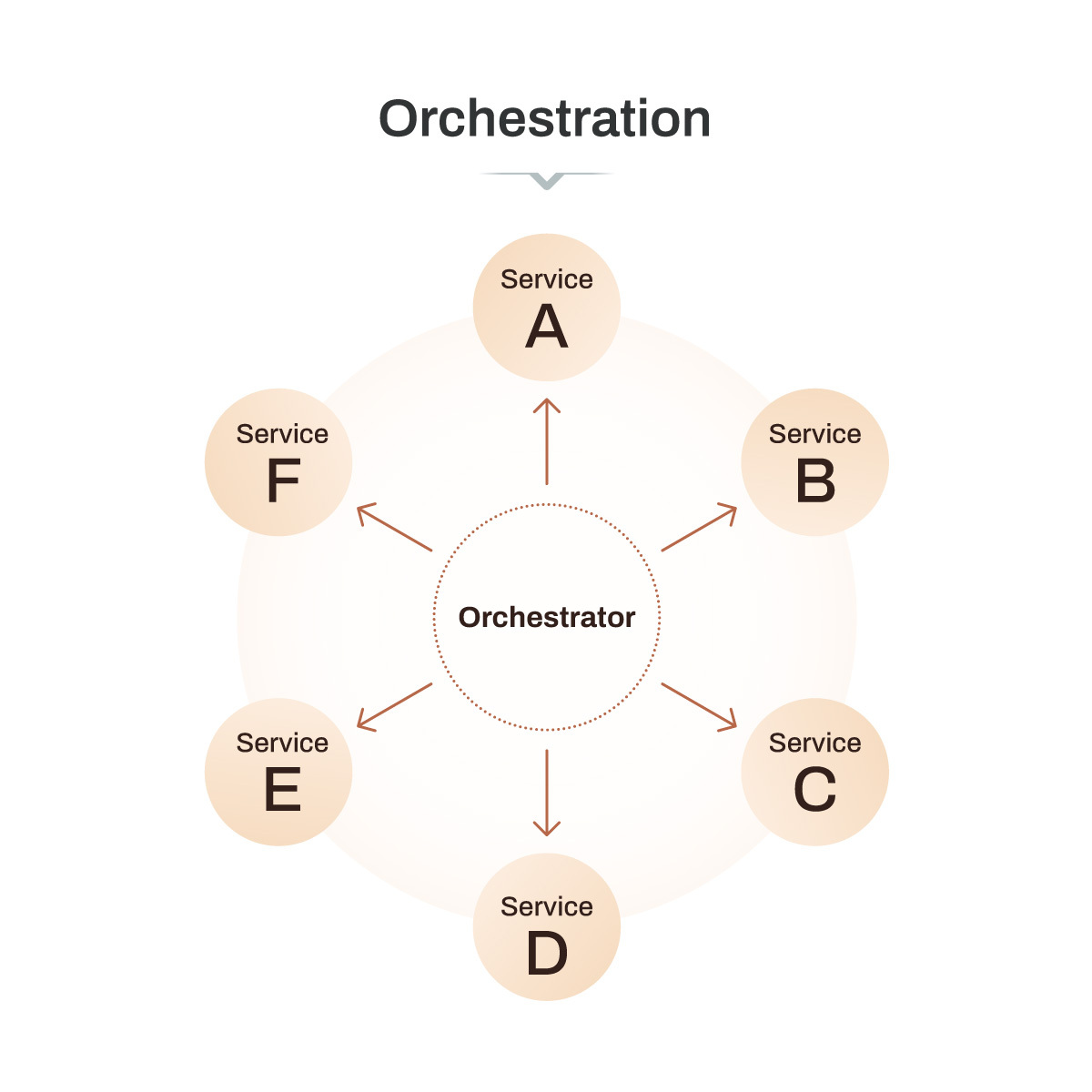
A central orchestrator (like Orkes Conductor) tells services what to do and when, and records what happened. It provides a single view of the workflow, with clear control over sequencing, retries, and error handling.
Services don’t wait for a boss. Instead, they publish and subscribe to events (via Kafka, RabbitMQ, or cloud pub/sub). Each service reacts when relevant, and the overall workflow “emerges” from these reactions.
If you want a less technical way to think about it, a good example is planning a trip with friends:
If you are looking for a more technical example, a good example is an e-commerce store:
That's essentially the difference between them. If you continue adding services and you need better monitoring for how they're each doing, then having an orchestrator makes sense. If you need a few services that handle a lot of real-time data, and don’t rely on each other much or on any sequence/order, you could check out choreography. Keep in mind that you do lose a lot of visibility with choreography, so if that matters to you and you don’t want to set up your own orchestrator, orchestration tools are there to make your life easier.
| Orchestration | Choreography | |
|---|---|---|
| Who’s in charge? | A central boss (orchestrator) controls the flow. | No boss. Services react to events on their own. |
| Scalability | Services scale independently, but the orchestrator must also scale. | Services scale independently; scaling depends on services and the message bus. |
| Communication | Orchestrator tells each service what to do and when. | Services publish and subscribe to events directly. |
| Strengths | Clear visibility, centralized error handling, easier monitoring/debugging. | Flexible, loosely coupled, easy to add/remove services, fits event-driven apps. |
| Limitations | Can feel hard to set up an orchestrator, but tools make it a breeze. | You lose visibility, and errors are harder to trace across services. |
| Tools | Workflow engines like Orkes Conductor. | Messaging systems like Kafka, RabbitMQ, or cloud pub/sub. |
In my experience, orchestration gives you a much clearer picture of what’s going on, especially when you’re troubleshooting or require an audit trail. Especially when you’re troubleshooting, which I highly value. Choreography can feel clean at first and if you have fewer services and you operate with a lot of real-time data it seems to work well, but once your system grows, it’s easy to lose track of what’s triggering what (so there goes any hope of quick debugging).
A lot of folks seem concerned about orchestration because they would need to build their own orchestrator. The cool thing is that you don’t have to do that, which is often the dealbreaker for teams that don’t want to reinvent the wheel.
Well, definitions only help so much. Use cases help a lot more. Like when do you use orchestration or choreography? It's not helpful to know about them, without knowing when they are useful. And I am not here to dump some jargon in your head for no reason.
Orchestration shines when you need a clear step-by-step plan and someone (the orchestrator) to make sure it happens. Great for processes where order, visibility, and error handling matter a lot.
Order Processing
A customer places an order in an e-commerce store. The orchestrator coordinates the flow step by step: first the Payment Service charges the card, then the Inventory Service reserves stock, then the Shipping Service creates a delivery, and finally the Notification Service confirms with the customer. Each service is called in sequence, and if one fails, the orchestrator knows how to retry or roll back.
Loan or Insurance Applications
When someone applies for a loan, multiple checks need to happen in the right order: credit check, identity verification, fraud detection, and document validation. An orchestrator manages this pipeline, ensuring each step completes successfully before the next begins. If a step fails, it can pause the process, retry, or notify the user, giving the entire flow structure and reliability.
Video Processing Pipelines
When a user uploads a video, the system must process it in a strict sequence: transcode the file, generate thumbnails, extract metadata, and notify the user when the video is ready. An orchestrator ensures each stage runs only after the previous one finishes, and it provides visibility into progress so the user experience stays smooth.
Travel Booking
Booking a trip often involves several dependent services: flights, hotels, car rentals, and payment. An orchestrator manages the process so that if one booking fails (e.g., a hotel is unavailable), the workflow can either retry with alternatives or cancel the trip and roll back prior reservations. This guarantees consistency across multiple dependent systems.
Healthcare Workflows
In a hospital system, an orchestrator coordinates patient intake: registering the patient, ordering lab tests, scheduling imaging, and updating the electronic health record. Each step must follow in order and succeed before the next begins. Orchestration ensures accuracy, visibility, and compliance with regulatory requirements.
Choreography fits well when your system is naturally more event-driven and you want your services to be loosely coupled (meaning each service can evolve, scale, or fail without directly impacting the others, since they only communicate through events). I can see it being used when you have fewer services that deal with a lot of real-time data, and you don’t need them to happen in any order.
Clickstream Analytics
A web app emits streams of user interaction events such as page views, button clicks, and search queries. Different services subscribe to those events. An Analytics Service updates dashboards, a Recommendation Service feeds data into machine learning models, and a Logging Service archives activity for compliance. These events can be consumed in any order, and each service processes them independently as soon as they arrive. You also don’t have a ton of services here.
IoT Sensor Data Processing
In a smart home setup, a Thermostat Service publishes temperature readings. From there, a Climate Control Service adjusts HVAC, a Logging Service records the data to the cloud, and an Alert Service sends notifications if thresholds are exceeded. None of these need to happen in strict order. The services just react whenever new data becomes available.
Stock Market Data Feeds
A Market Data Service streams ticker updates in real time. Subscriber services act on those events in parallel. A Trading Algorithm executes buy/sell strategies, a Monitoring Service checks for anomalies, and a Storage Service writes history for analysis. Each one acts as soon as data arrives, without any central process dictating the sequence.
Sports or Event Live Updates
When a Game Feed Service publishes score updates, multiple subscribers respond independently. A Live Dashboard Service refreshes the UI, a Betting Service recalculates odds, and a Social Media Service pushes notifications to fans. The order doesn’t matter here either. And each service just reacts to score events as they happen.
Yes, they can.
These flows could also be handled with orchestration (and often are when visibility, retries, or sequencing matter to you). But they’re good illustrations of choreography because the services don't depend on a specific order/sequence.
In my experience, orchestration gives you a much clearer picture of what’s going on. Especially when you’re troubleshooting. Choreography can feel clean at first, but once your system grows, it’s easy to lose track of what’s triggering what. If you're just getting started, don't be afraid to use orchestration early. It can save you a lot of guesswork later.
You don’t have to choose just one. Most real-world systems use a bit of both. Orchestration for structure and visibility, and choreography for a bit more flexibility and certain kind of autonomy of services. The trick is knowing when each one makes sense, and designing with that in mind.
It’s one thing to understand orchestration vs choreography in theory, but trying them with real services makes the differences click.
You can sign up here and spin up a quick Order → Payment → Shipping flow.
Seeing the steps run with retries, error handling, and monitoring makes the differences much clearer than theory alone.