ENGINEERING
Durable Execution Explained — How Conductor Delivers Resilient Systems Out Of The Box

Viren Baraiya
CTO
Last updated: May 9, 2024
May 9, 2024
9 min read








Join thousands of developers building the future with Orkes.
This is part 2 of a two-part series on durable execution, what it is, why it is important, and how to pull it off. Part 2 shows how Conductor, a workflow orchestration engine, seamlessly integrates durable execution into applications. Check out part 1 for more about what durable execution is.
In the ever-evolving landscape of application architecture, durable execution and platform engineering have been gaining traction in recent years, driven by the need for resilient, scalable, and efficient systems.
Durable execution refers to a system’s ability to persist execution even in face of interruption or failure. This characteristic is especially important in distributed and/or long-running systems, where the chances of disruptions or failure increase drastically. While there are several best practices for building durable applications and systems, one of the most effective ways is to leverage stateful platforms like Orkes Conductor.
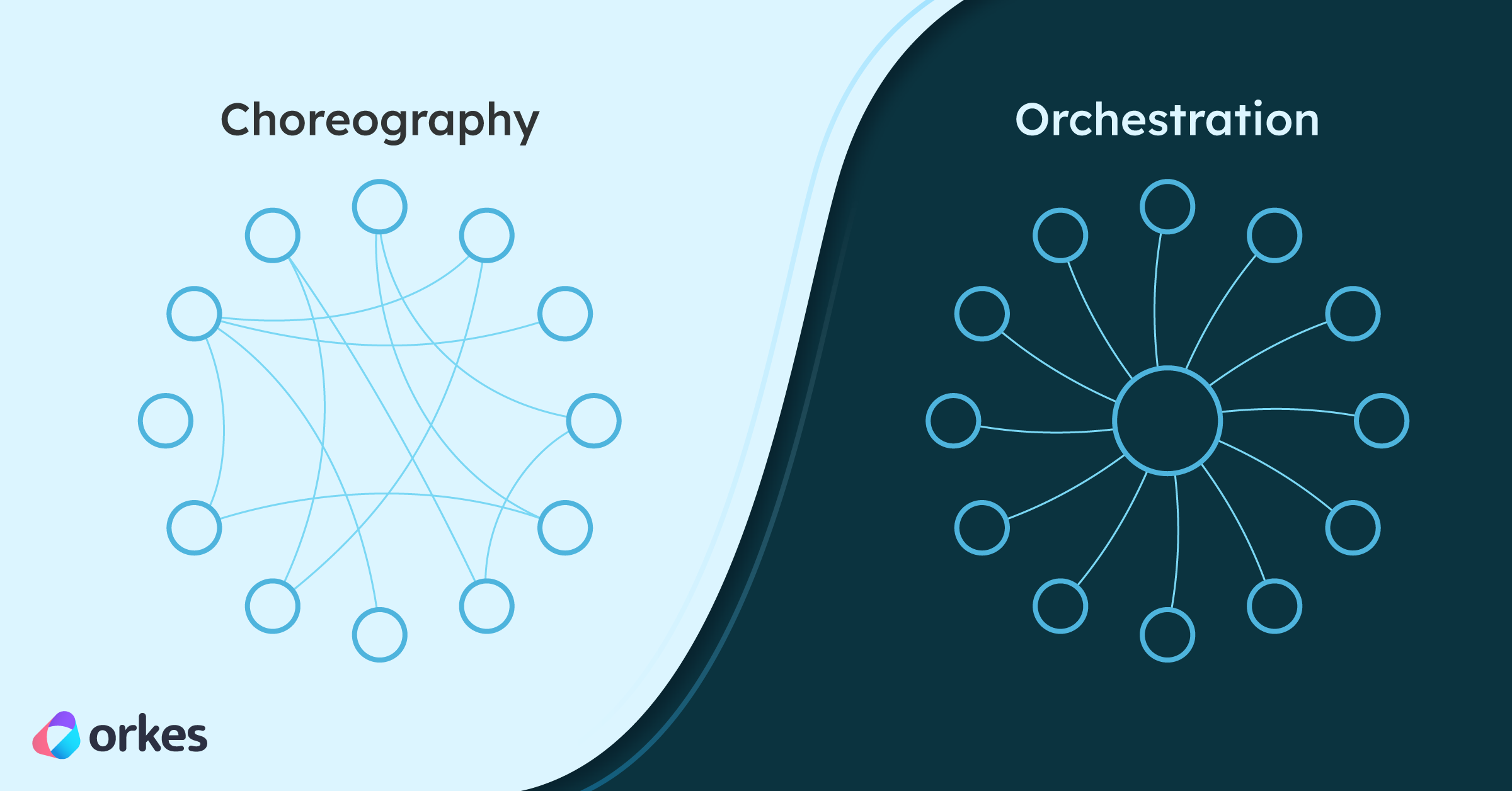
Conductor is a workflow orchestration platform that abstracts away the complexities of underlying infrastructure, enabling developers to focus on building applications. True to its name, Conductor directs and orchestrates the performance of distributed services into a dynamic application flow. Each individual player – or task – does not need to care what the other players are doing, because Conductor keeps track of what is supposed to happen at every juncture.
Its in-built state management allows for reliable recovery in case of failure or interruption. Just like a musical conductor, it empowers applications to adapt to ever-changing conditions without going offline — whether it is automatically retrying tasks, scaling up to meet traffic spikes, or integrating new services.
How does Conductor enable you to build resilient, efficient, and scalable systems? Let’s take a look at what happens in the backend when you build your applications with Conductor as the main orchestration engine.
Conductor’s secret sauce for fortifying systems with durable execution is decoupled infrastructure and redundancy. Let’s set the scene for an example workflow.
Say you have an online shop that makes and ships custom violins worldwide. The order process can take months to fulfill, from pre-ordering the violin to customizing and shipping it.
Enter the four key actors in our order workflow.
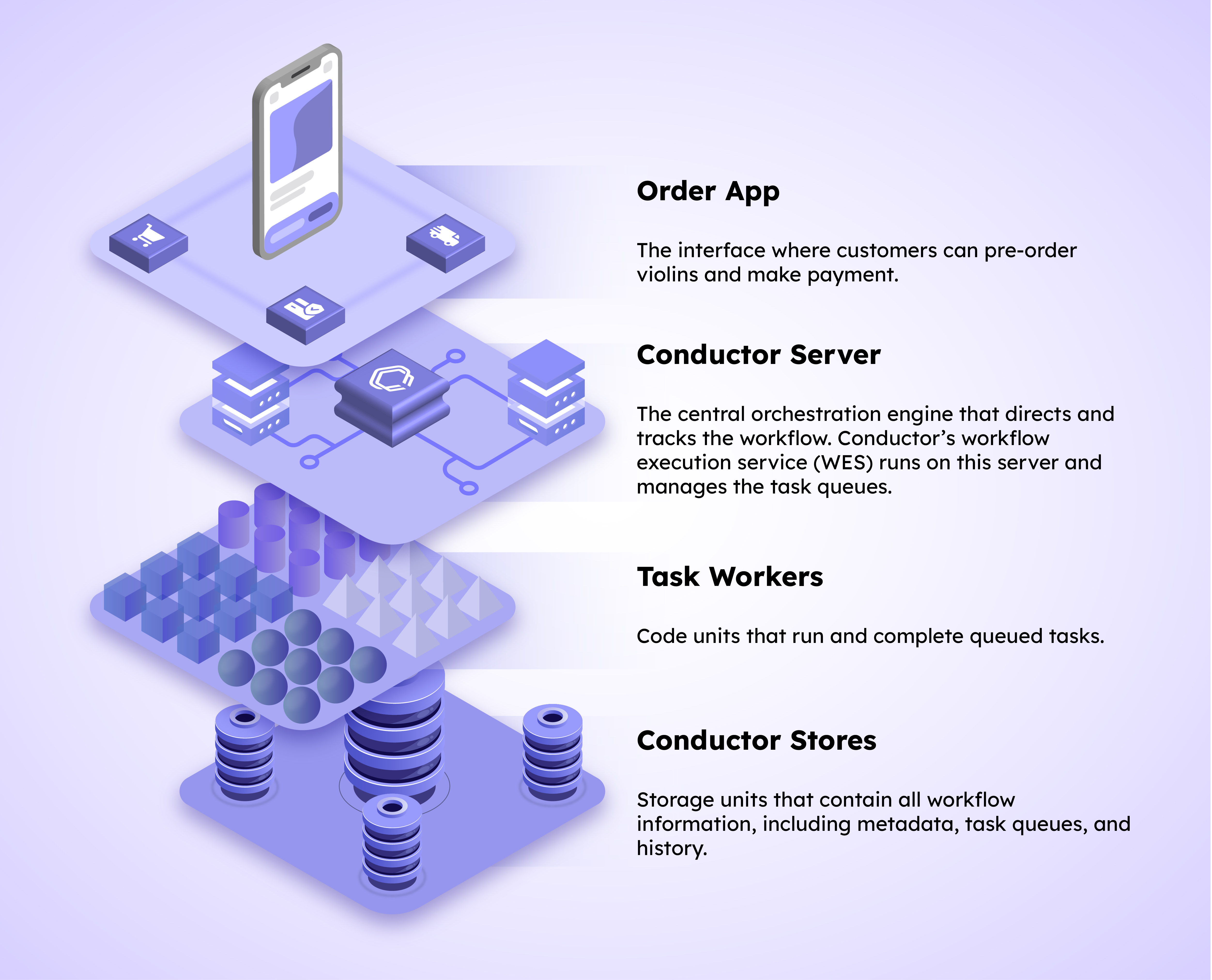
In the Order App, when the user clicks the Order button during the checkout procedure, a Conductor workflow for order_processing is triggered. The Order App passes the workflow input parameters, such as the order details, shipping address, and user email to the Conductor Server. In return, the Server passes back the workflow instance ID, which can be used to track the workflow progress and manage its execution.
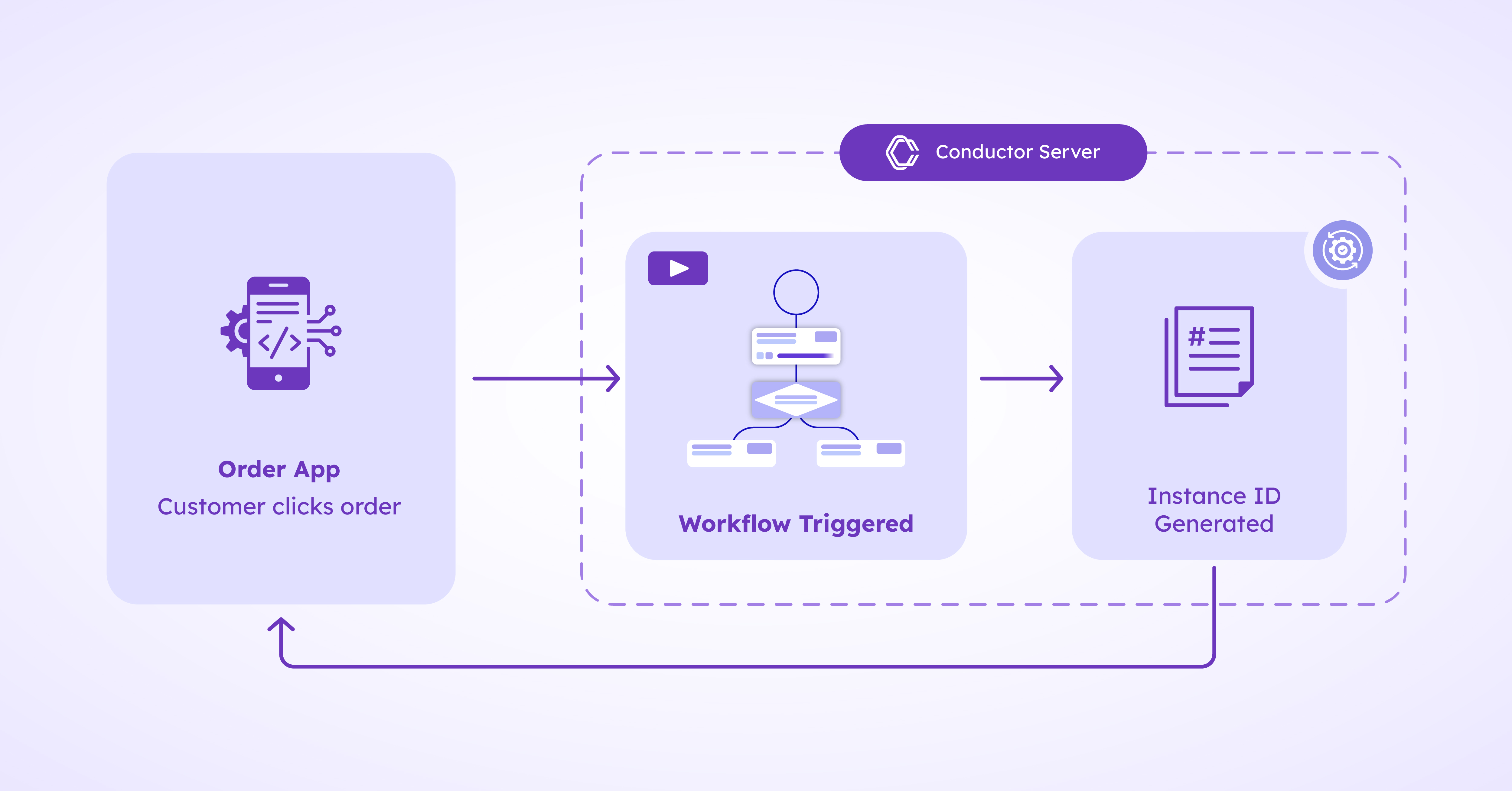
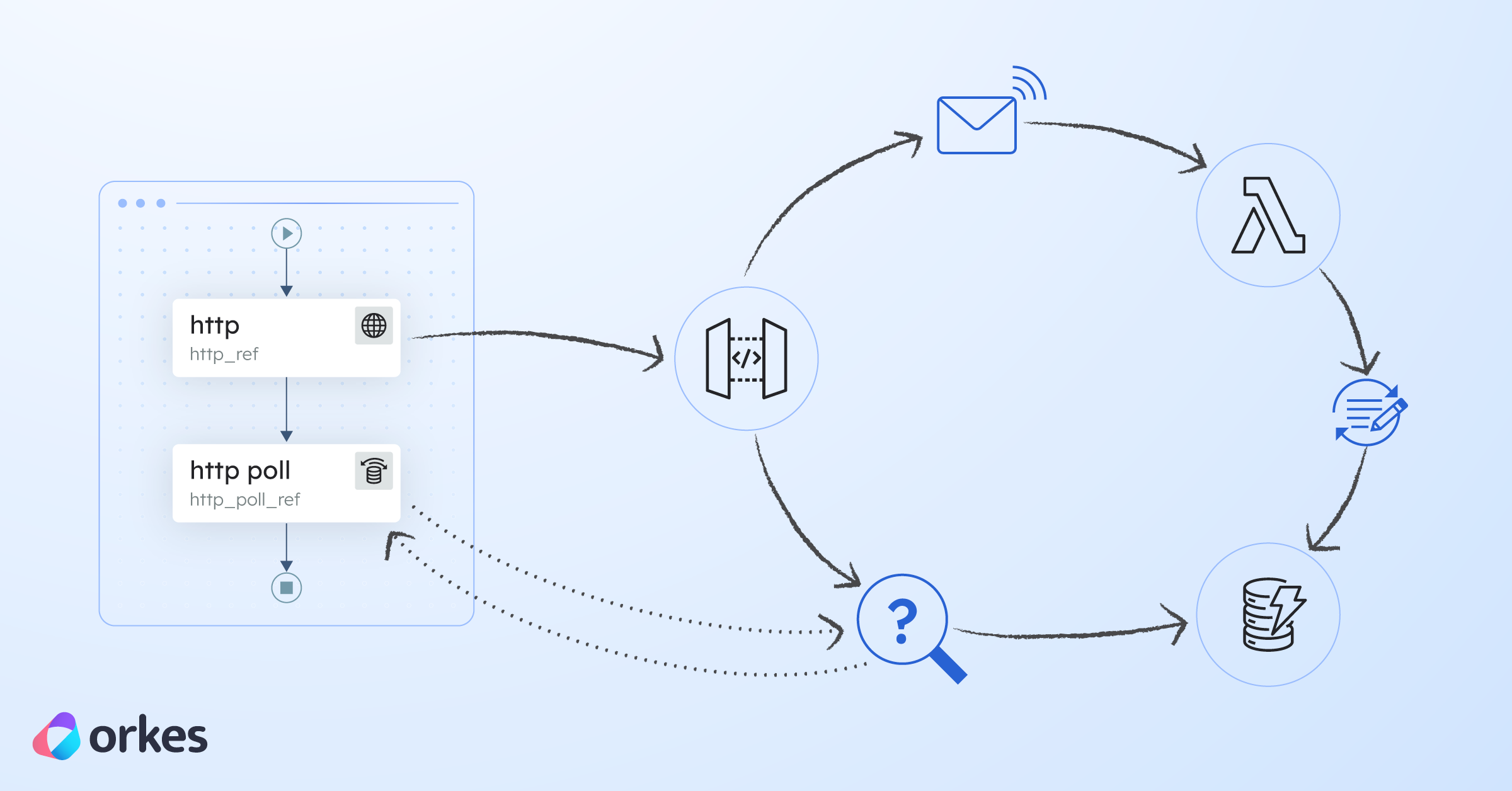
Based on predefined signals and parameters, the order_processing workflow will run through a series of tasks, such as a HTTP call to a payment processor, or a piece of custom functionality for invoice calculation.
In Conductor, workflows are executed on a worker-task queue architecture, where each task type – HTTP call, webhook, and so on – has its own task queue. When the workflow execution for order_processing begins, the workflow execution service (WES) begins to add the workflow’s tasks to the relevant queues. A HTTP task that calls a third-party payment processor, capture_payment, is added to the HTTP task queue. Meanwhile, calculate_invoice, a custom function, is added to a custom task queue, while notify_invoice, another third-party email service, is added to the HTTP task queue.
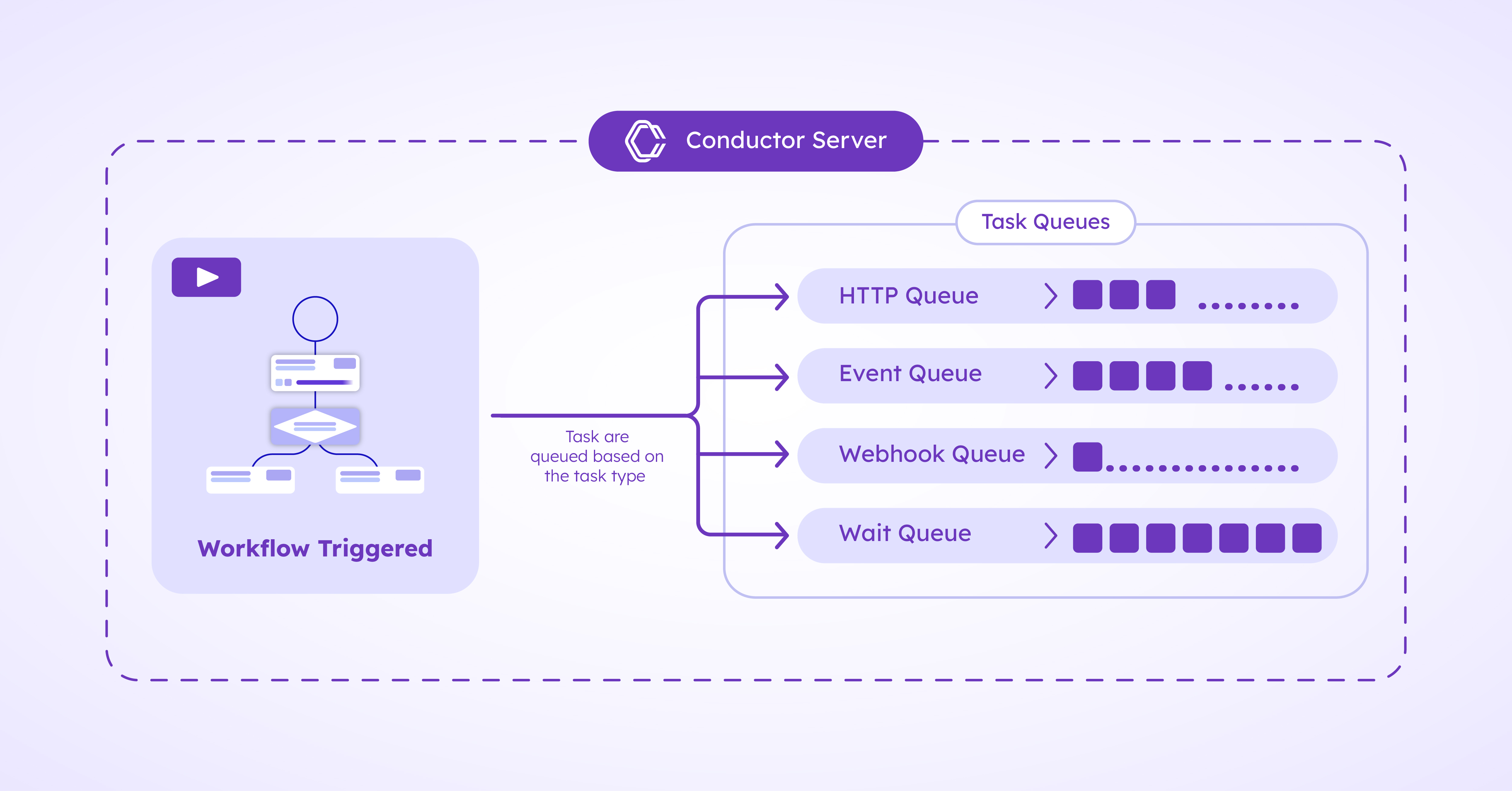
While Conductor’s WES is directing and scheduling tasks to the right queue, the available Task Workers are busy polling for tasks to do. Although there are three tasks queued, the first task, capture_payment, has to be completed first, before the next task can begin. So, when Worker A polls for a task, the Conductor Server sends capture_payment to Worker A for completion. Once Worker A has completed the task, it updates the Server about the task completion status.
The Server registers and keeps track of each task’s status. So when it receives the update from Worker A that capture_payment has been completed, it will send the next scheduled task to the next available worker.
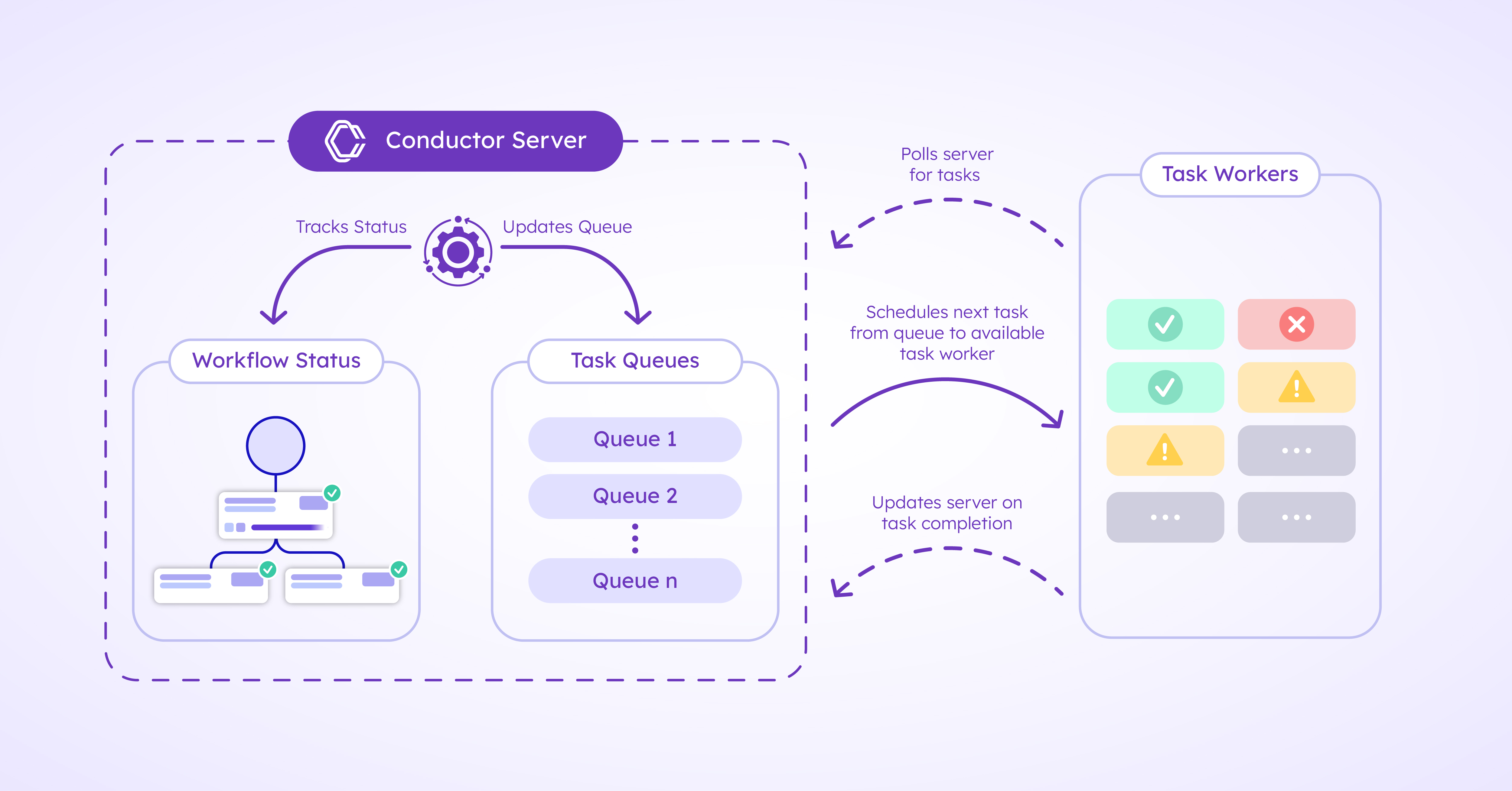
This set-up is how Conductor keeps track of the workflow state as one task gets completed one after another based on the predefined workflow schedule. And voilà, with Conductor’s state management, developers need not spend time building complicated infrastructure for state management. Remember the workflow instance ID that was sent when the workflow was initiated? The Order App can simply use the ID to query the Server about the workflow status at any time.
Crucially, Conductor goes beyond just state visibility. It’s built to withstand and recover from failures no matter how long the workflow runs. Cue the Conductor Stores. At every point, data gets stored on distributed, high-availability clusters so that the workflow can always pick up and resume from where it last stopped – whether from a restart in a failed run or from an idle state in a long-running flow.
For example, after capture_payment, the WES reads the next task, wait_customization, and pauses the workflow to wait for the luthier to finish crafting the instrument. The process may take several months, but with the workflow execution history, pending task queues, and predefined flow of tasks, the system can easily recover from this state of idling. Once Conductor receives a signal – perhaps the luthier clicked a confirmation button on the Order App – that the violin has been made, it will send the next scheduled task in the queue to the next available worker.
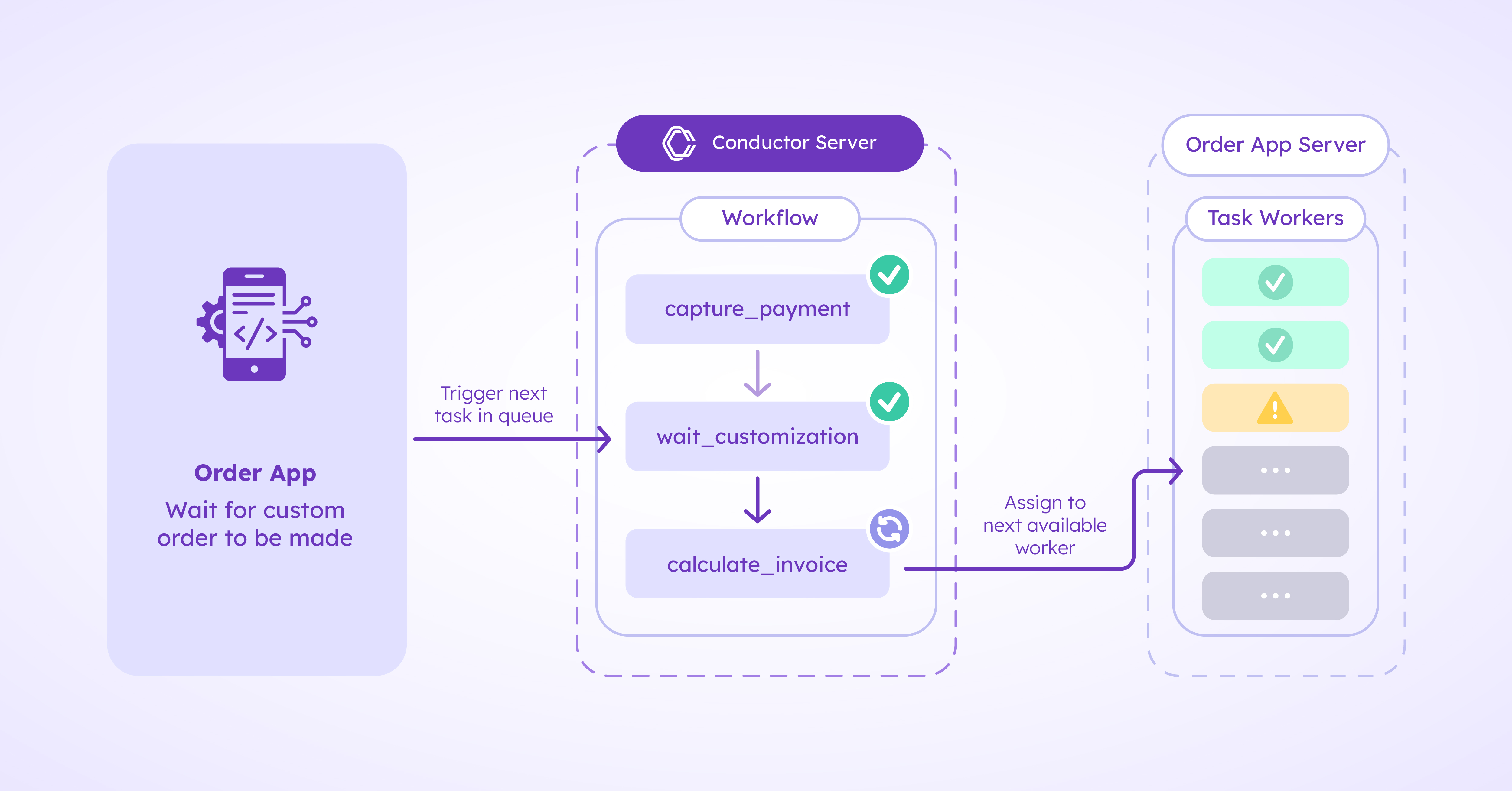
Whether it’s transient failures, like services going offline briefly, or execution failures, like buggy code, or even deliberate termination, like a customer canceling an order, Conductor is equipped to handle it all.
We’ve seen a glimpse of how Conductor’s decoupled infrastructure and redundancy enable applications to run smoothly with guaranteed state visibility and persistence. But failure scenarios are where these characteristics for durability really shine through.
App server goes offline
Let’s continue with the custom violin order processing workflow. With the violin ready, the workflow proceeds to calculate_invoice, a custom functionality on the Order App. Perhaps at this moment, a blackout causes the Order App’s server to go down temporarily, which takes all the Task Workers for the calculate_invoice task offline as well. When the Conductor Server dispatches this task to be completed, there are no Workers available to complete it.
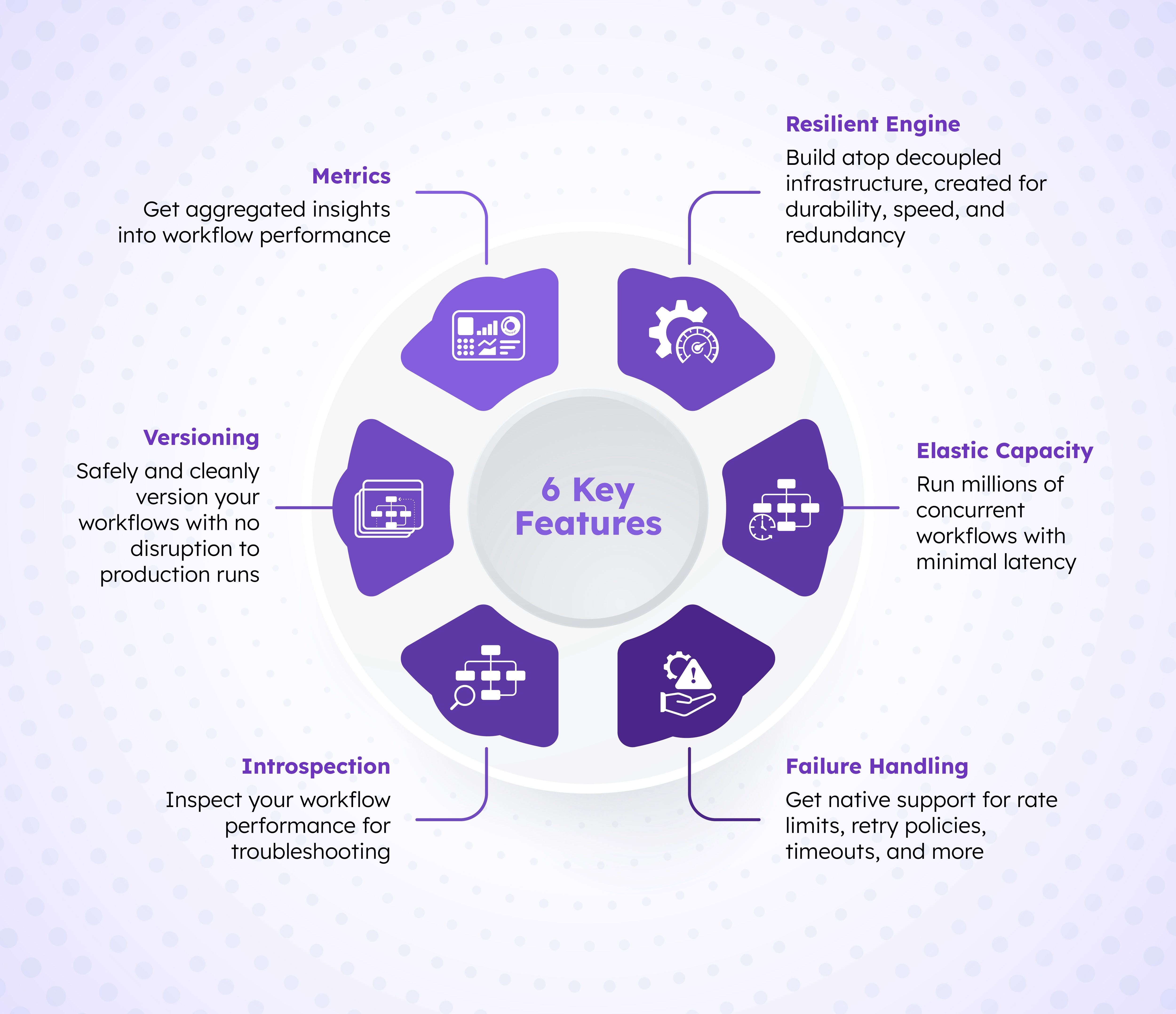
Based on the task’s retry and timeout policies, Conductor will automatically reschedule the task until the Order App’s server comes back online or until timeout occurs.
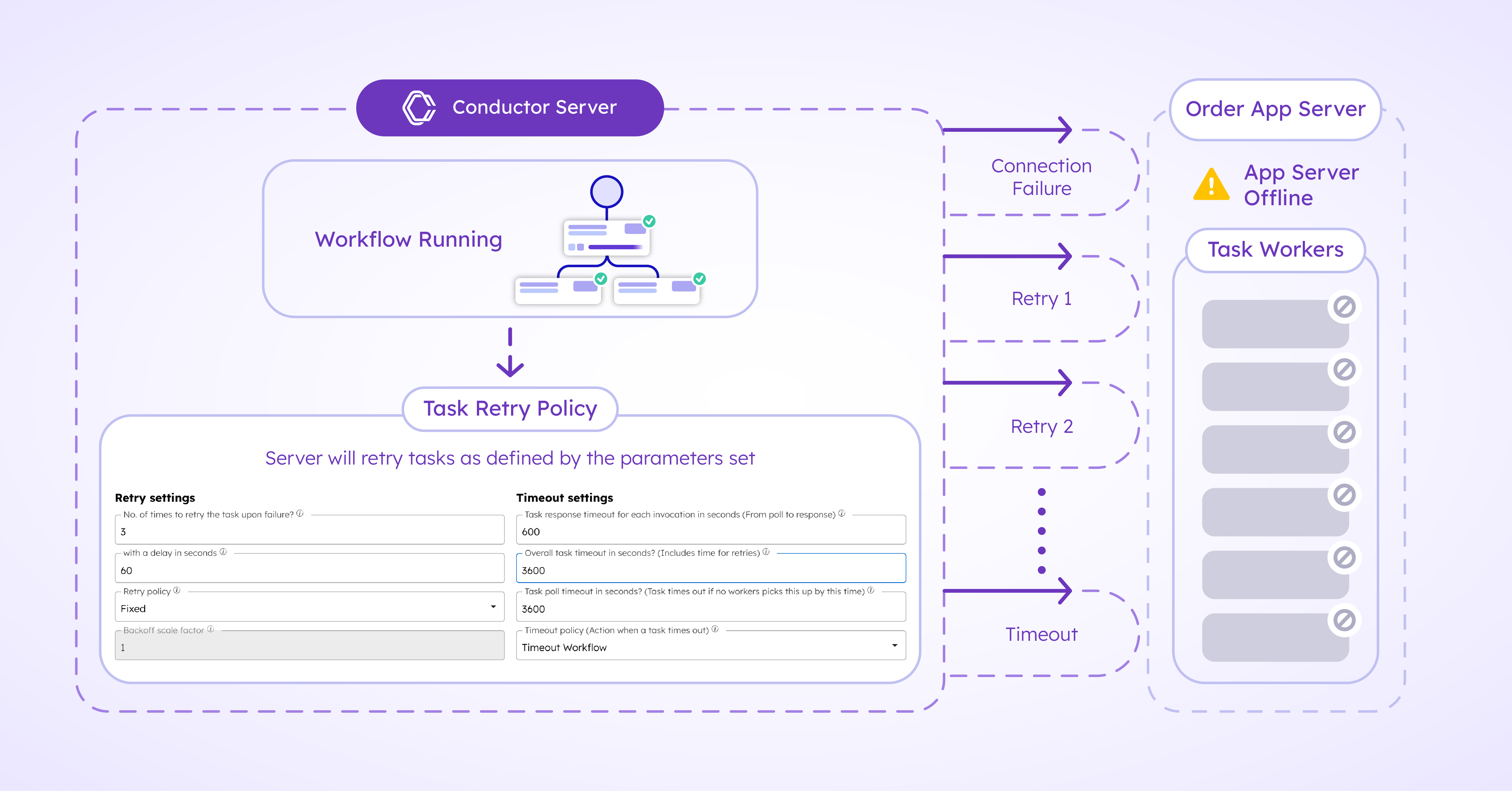
Service hits rate limit
Once the calculate_invoice task has been completed, the next task – a HTTP call for notify_invoice – is invoked. At this point, we hit another roadblock: the HTTP service for this task has reached its rate limit. As before, Conductor automatically retries the task with exponential backoff, so that the task is guaranteed to be completed successfully.
Conductor goes offline
Conductor can be deployed in high-availability clusters to guarantee maximum uptime. Even so, in the off-chance where its workflow execution service (WES) goes down, Conductor’s decoupled infrastructure ensures that task runs are not affected. Since the task queues reside on high-availability clusters, separate from the WES, workers can continue running the tasks until completion and update the Conductor Server once it comes back online.
Introspecting workflows for debugging
Once in a while, workflows may still fail despite these automated safeguards and policies for guaranteed execution. However, Conductor makes it easy to remedy these situations. With Conductor Stores that preserve all execution history, developers can inspect what happened under the hood to troubleshoot and rectify errors before restarting the failed workflows.
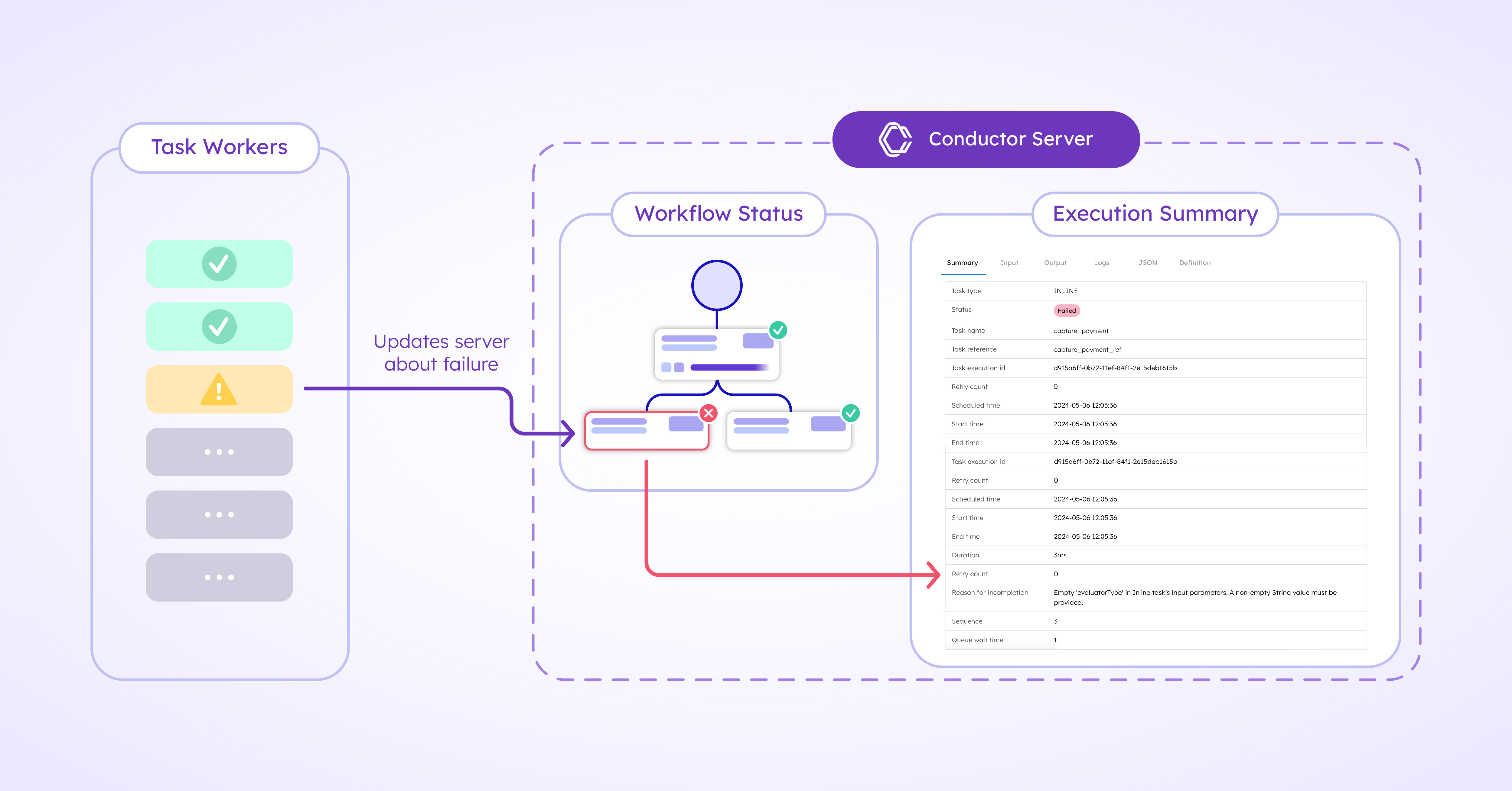
For example, say the number of custom violin orders have increased over time, and a number of order_processing workflow executions are taking too long or have timed out. With the ability to introspect, we can quickly pinpoint the problem. Perhaps the HTTP URL is outdated, or there are insufficient workers servicing a task. Armed with these logs, application developers can quickly troubleshoot and resolve these issues so that the workflows can restart without any roadblocks.
Importantly, because Conductor keeps state management and infrastructure separate from the Order App’s business logic, the developers can easily scale or upgrade the underlying infrastructure without any downtime.
Analyzing metrics to optimize performance
Over time, sufficient data will be collected to analyze the workflow performance in aggregate. Conductor comes equipped with a metrics dashboard that showcases key insights about latency, completion rate, failure rate, number of concurrent workflows, and so on.
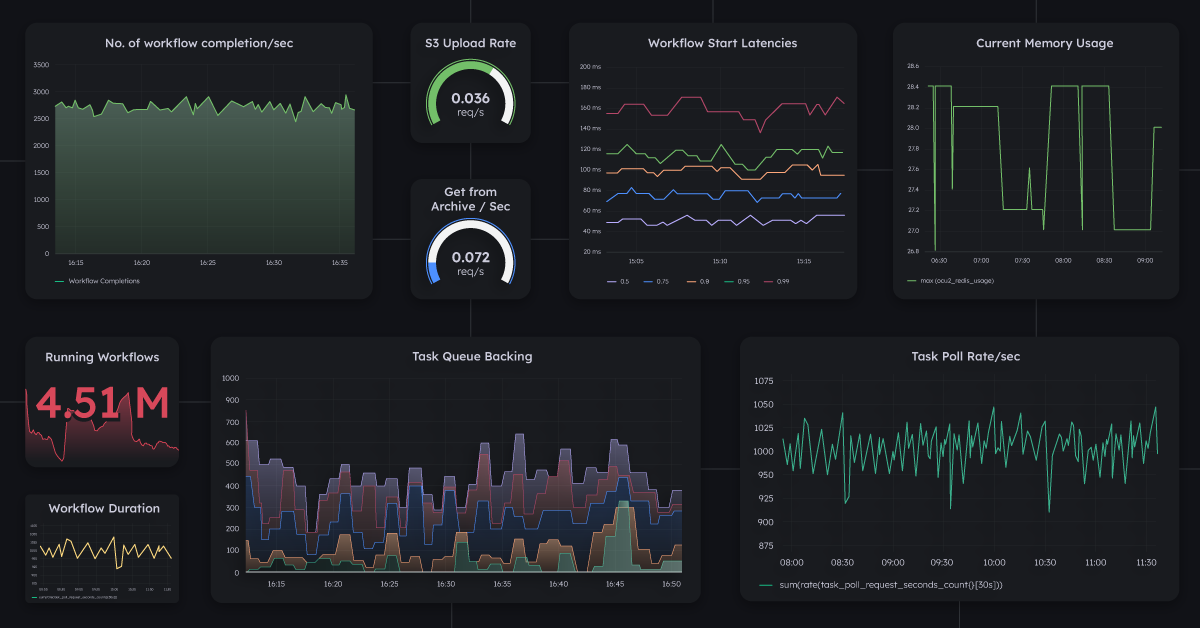
These metrics can further inform decisions to optimize Conductor workflows for better performance, such as refactoring code or scaling up the infrastructure.
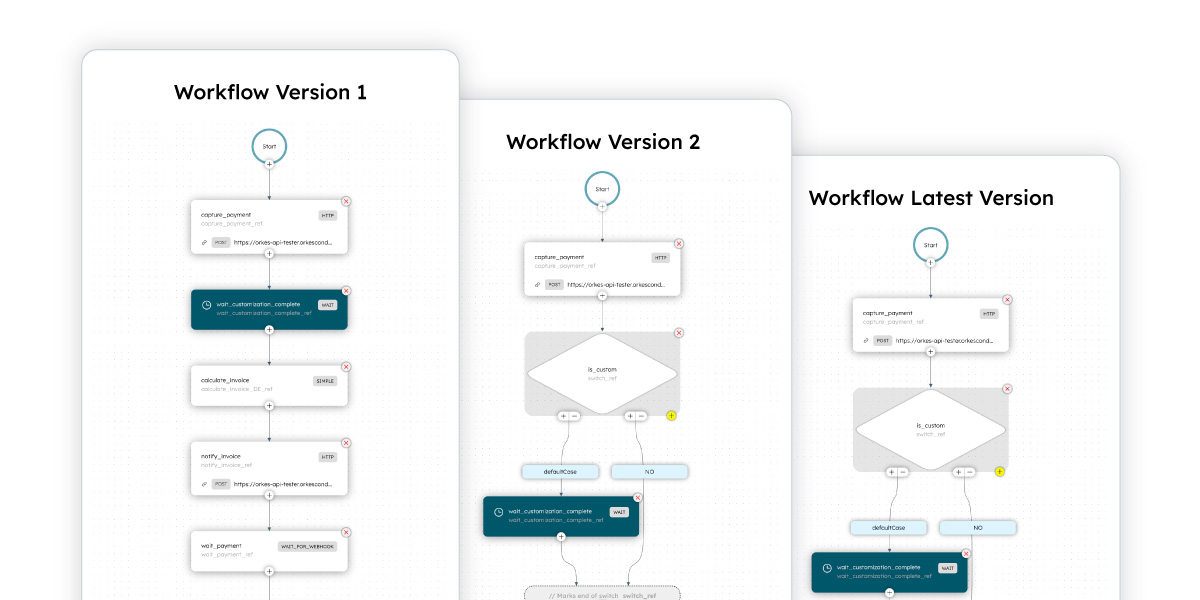
Refactoring workflows with no downtime
With in-built support for workflow versioning, application developers can refactor the workflow code anytime without impacting existing workflows. Once the workflow definition has been updated, new executions will run based on the latest definitions while existing workflows can be restarted to run the latest definitions. All of this, made possible with Conductor’s decoupled architecture.
In summary, Conductor bolsters your application durability with these key features:
As a general-purpose orchestration engine, Conductor is versatile enough for any possible use case — compliance checks in banking and finance, media encoding in entertainment, or shipping automation in logistics. Check out our case studies to discover how organizations across industries use Conductor or the following tutorials:
Conductor is an enterprise-grade orchestration platform for process automation, API and microservices orchestration, agentic workflows, and more. Check out the full set of features, try it yourself using our Developer Edition sandbox, or get a demo of Orkes Cloud, a fully managed and hosted Conductor service.