SOLUTIONS
Opsgenie Alerting with Orkes Conductor

Riza Farheen
Developer Advocate
Last updated: December 21, 2023
December 21, 2023
6 min read








Join thousands of developers building the future with Orkes.
Providing an Application as a SaaS model based on a Service Level Agreement has become the preferred go-to-market approach these days. SLA brings, therefore, a strong commitment between SaaS providers and clients based on several metrics.
Let’s put ourselves in the position of a SaaS provider where the SLA states a contract of 98% uptime for the application every month. Now, there comes a critical responsibility for us to ensure that our application downtime is reduced at any cost to maintain 98% uptime. Situations like this call for an immediate alerting system to quickly notify our developers and SRE teams of app downtime.
Every second then matters because this downtime can cost significant lost revenue. It’s all about minimizing those precious seconds between “Something went wrong” and “We’re back online,” i.e., knowing there is a problem and deploying its appropriate resolution.
In this blog, we’ll have a walkthrough of how Orkes Conductor and the popular incident & alert management system Opsgenie help minimize an application's downtime by quickly sending alerts to Opsgenie. Pairing Orkes Conductor with an alerting system like Opsgenie provides a dynamic duo that alerts the right people when something goes wrong.
Opsgenie is an incident management platform to keep mission-critical incident checks in place and to ensure that the right team takes action in the shortest possible time. Opsgenie can receive alerts from any monitoring system or your custom applications. You can leverage Opsgenie functionalities such as on-call schedules to ensure the developers are notified through various communication channels such as email, SMS, push notifications, calls, and more.
Orkes Conductor is a powerful orchestration platform built over the popular open-source Conductor OSS (formerly Netflix Conductor). Orkes, the enterprise-grade Conductor platform, simplifies the development and scaling of distributed workflows, microservices, and events.
Conductor offers a new system task, “Opsgenie,” which helps you integrate easily with Opsgenie to send alerts whenever a failure occurs to applications built with Orkes Conductor.
In this use case, we need to detect whenever your application (the one you are providing as a service) fails.
Let’s take a look at a sample application that detects failed instances of your app between a certain time period in Orkes Conductor and sends alerts to Opsgenie.
The sample application looks like this:
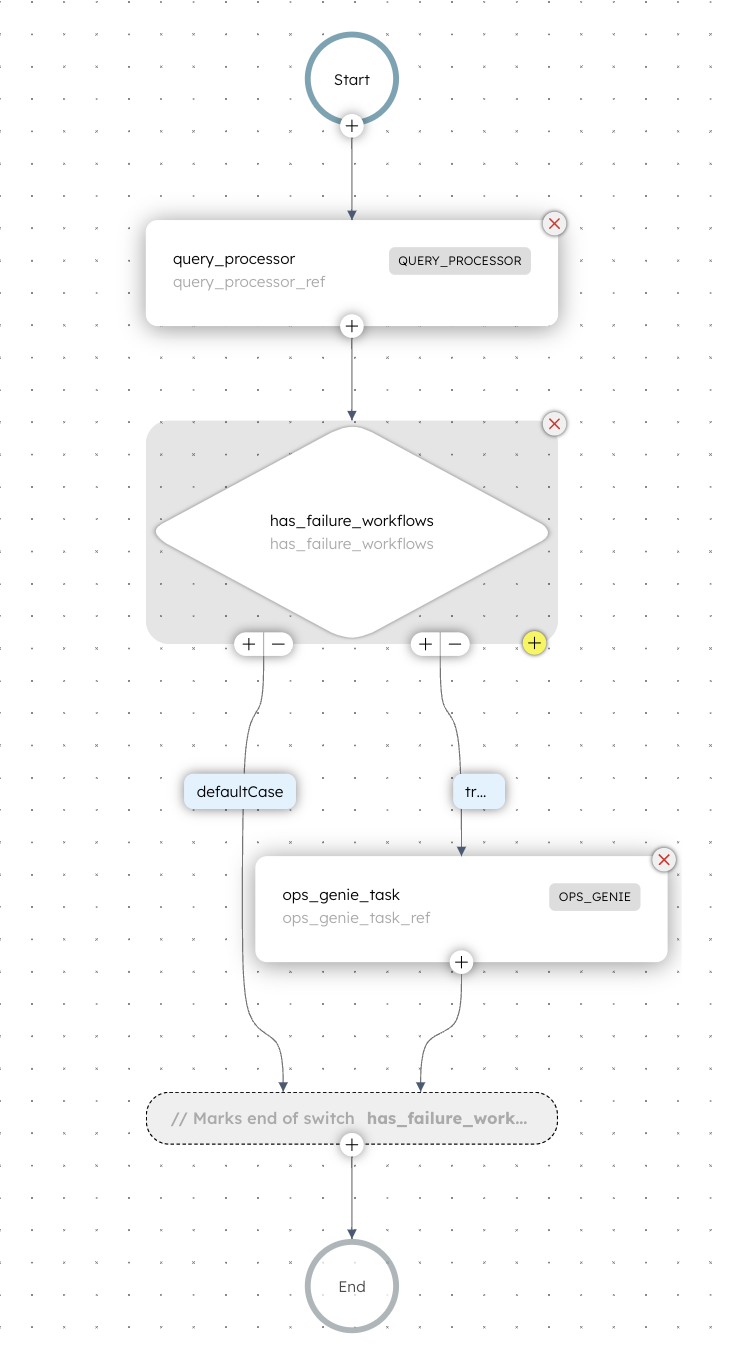
You can get the complete JSON here.
Now, let's quickly take a look at how the app works:
{
"opsGenieEntity": "New entity",
"opsGenieVisibleTo": [
{
"id": "711257a7-7f81-47d7-bebd-ecd03ff5601d/main",
"type": "team"
}
],
"fromStartedMinsFromNow": 3600,
"opsGenieAlias": "riza",
"opsGenieActions": ["Restart"],
"opsGenieTags": ["OverwriteQuietHours", "Critical"],
"opsGenieDetails": {
"Alert Test": "one"
},
"toStartedMinsFromNow": 0,
"statuses": ["FAILED"],
"workflows": ["TestFailedWorkflow"],
"opsGeniePriority": "P1",
"opsGenieResponders": [
{
"type": "user",
"username": "devrel@orkes.io"
}
]
}
{
"name": "query_processor",
"taskReferenceName": "query_processor_ref",
"inputParameters": {
"queryType": "CONDUCTOR_API",
"statuses": "${workflow.input.statuses}",
"workflowNames": "${workflow.input.workflows}",
"startTimeFrom": "${workflow.input.fromStartedMinsFromNow}",
"startTimeTo": "${workflow.input.toStartedMinsFromNow}",
"correlationIds": "${workflow.input.correlationIds}",
"freeText": "${workflow.input.freeText}"
},
"type": "QUERY_PROCESSOR",
Here, we have defined to query the application using variables (passed as workflow input) so that you can use this application to query any failure app data.
Suppose the input details are passed as below:
"workflowNames": [
"TestFailedWorkflow"
],
"startTimeFrom": 15,
"startTimeTo": 0,
"correlationIds": null,
"freeText": null,
"statuses": [
"FAILED"
],
In this example, the app will query for the failed instances of the application, namely “TestFailedWorkflow,” in the last 15 minutes.
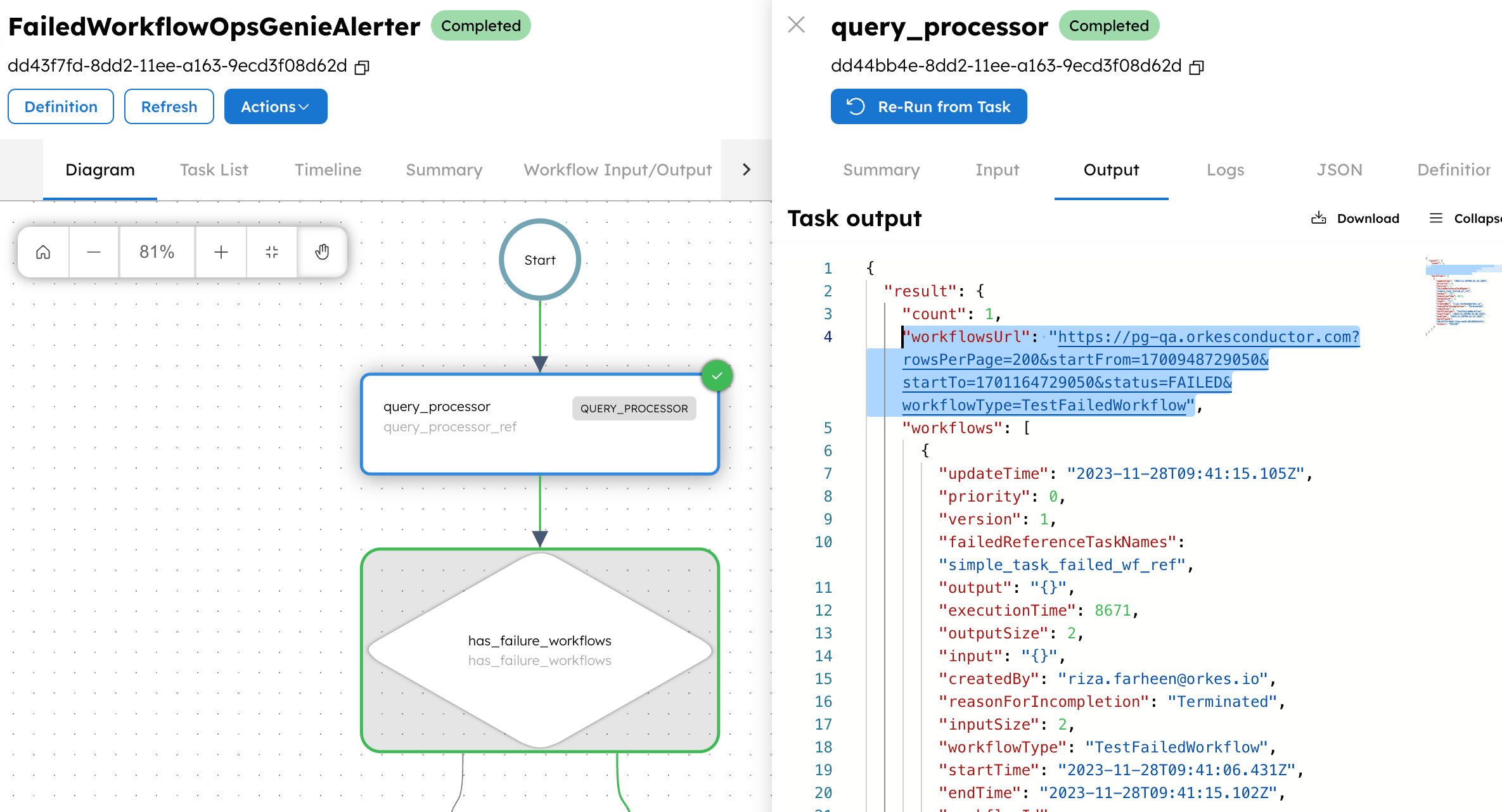
The output of this task will return a URL, which is the deep link of the failed instances within the specified 15 minutes.
"workflowsUrl": "https://developer.orkescloud.com?rowsPerPage=200&startFrom=1696447143843&startTo=1696448043843&status=FAILED&status=TERMINATED&workflowType=TestFailedWorkflow&workflowType=TestTerminatedWorkflow"
If there aren’t any failure instances of this app in the specified minutes, then the output will not return this URL. (This field will be blank.)
This task output is passed on to the next task, which is a switch task in Orkes Conductor. The switch task checks if there are any failed instances reported and then executes the corresponding switch cases. There are two switch cases here: defaultCase and the true case.
If the workflow has failures, then the details are passed on to the Opsgenie task. You need to get the Opsgenie API integration key from your Opsgenie portal and store this as a secret key in the Orkes Conductor console.
"token": "${workflow.secrets.OPS_GENIE_TOKEN}"
Note: Ensure that you update the secret name in the workflow definition with your secret name.
The next set of tasks to address the alert can be configured in Opsgenie as per your business requirements.
Let’s run the application now.
You can quickly run from Conductor UI using the Run Workflow button from the left menu on your console.
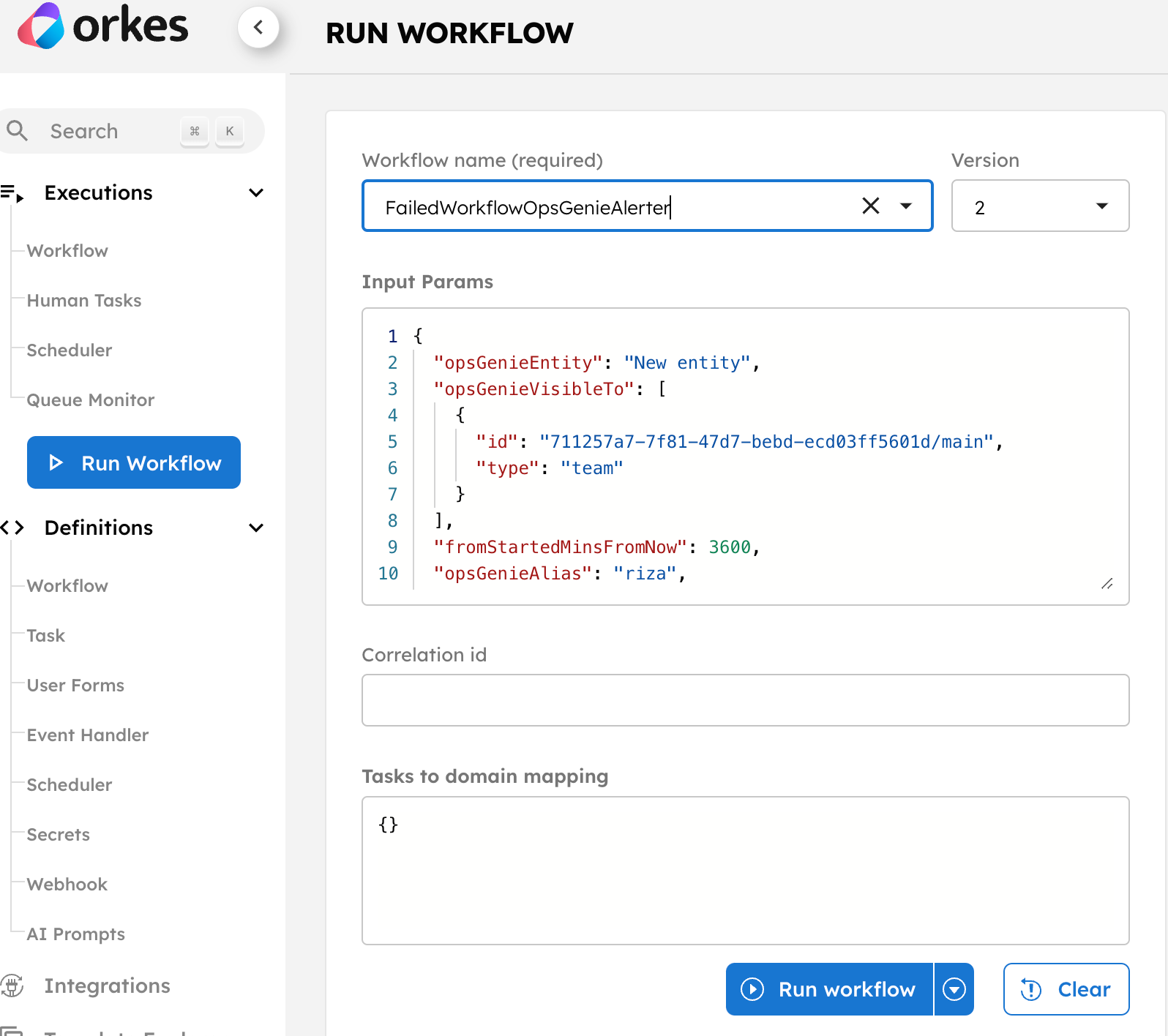
Once executed, a workflow (execution) ID will be generated, clicking on which you can view the execution.
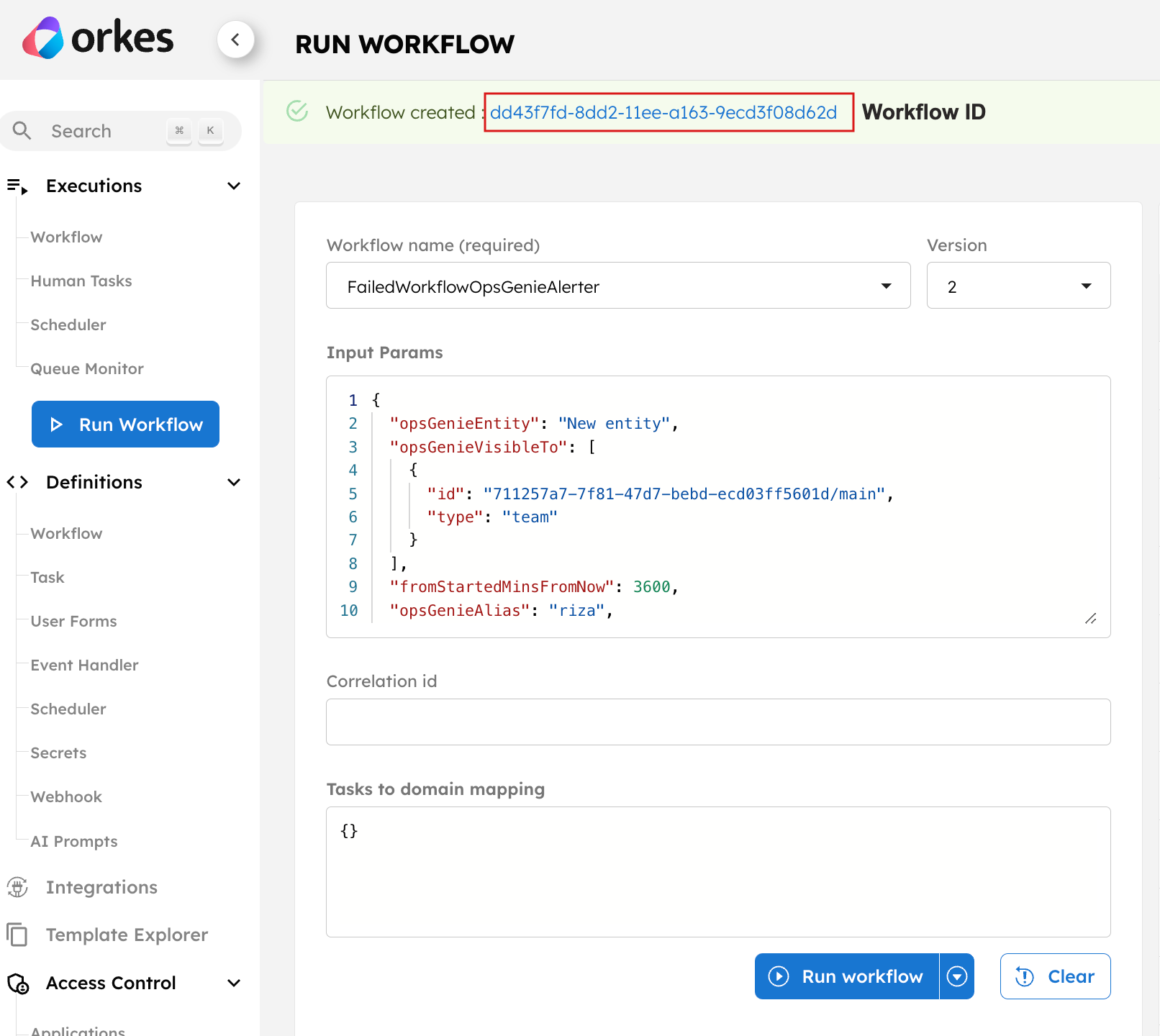
Here’s what the execution looks like:
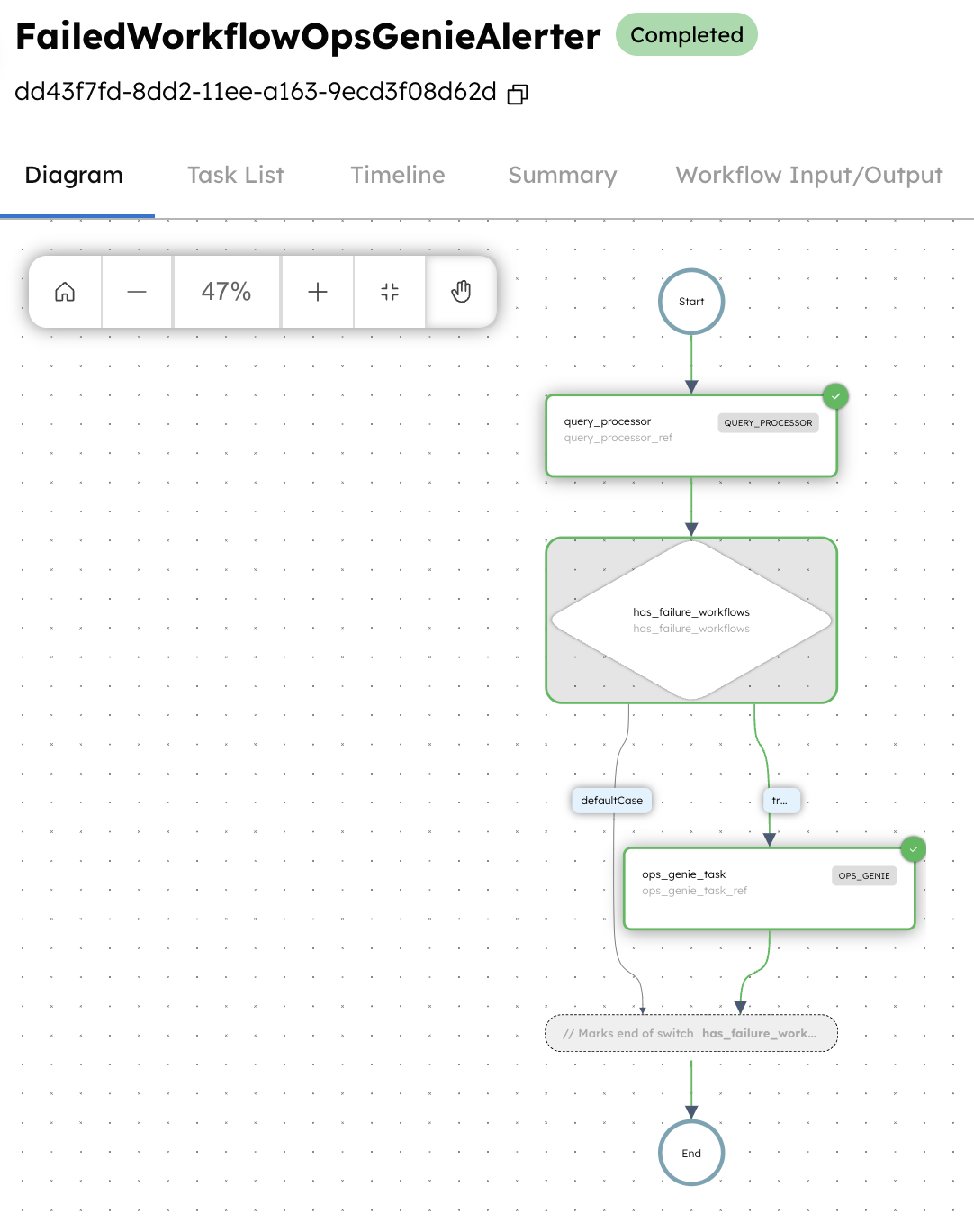
So, it’s clear that the app is executed successfully. If you check the output of the Query Processor task, you can see that the workflowUrl is generated for the failed instance of your specified application.
Now, let’s check the alert on the Opsgenie account.
Open your Opsgenie console and navigate to the Alerts tab. Under the Open alerts, you can find that the alert has been received.
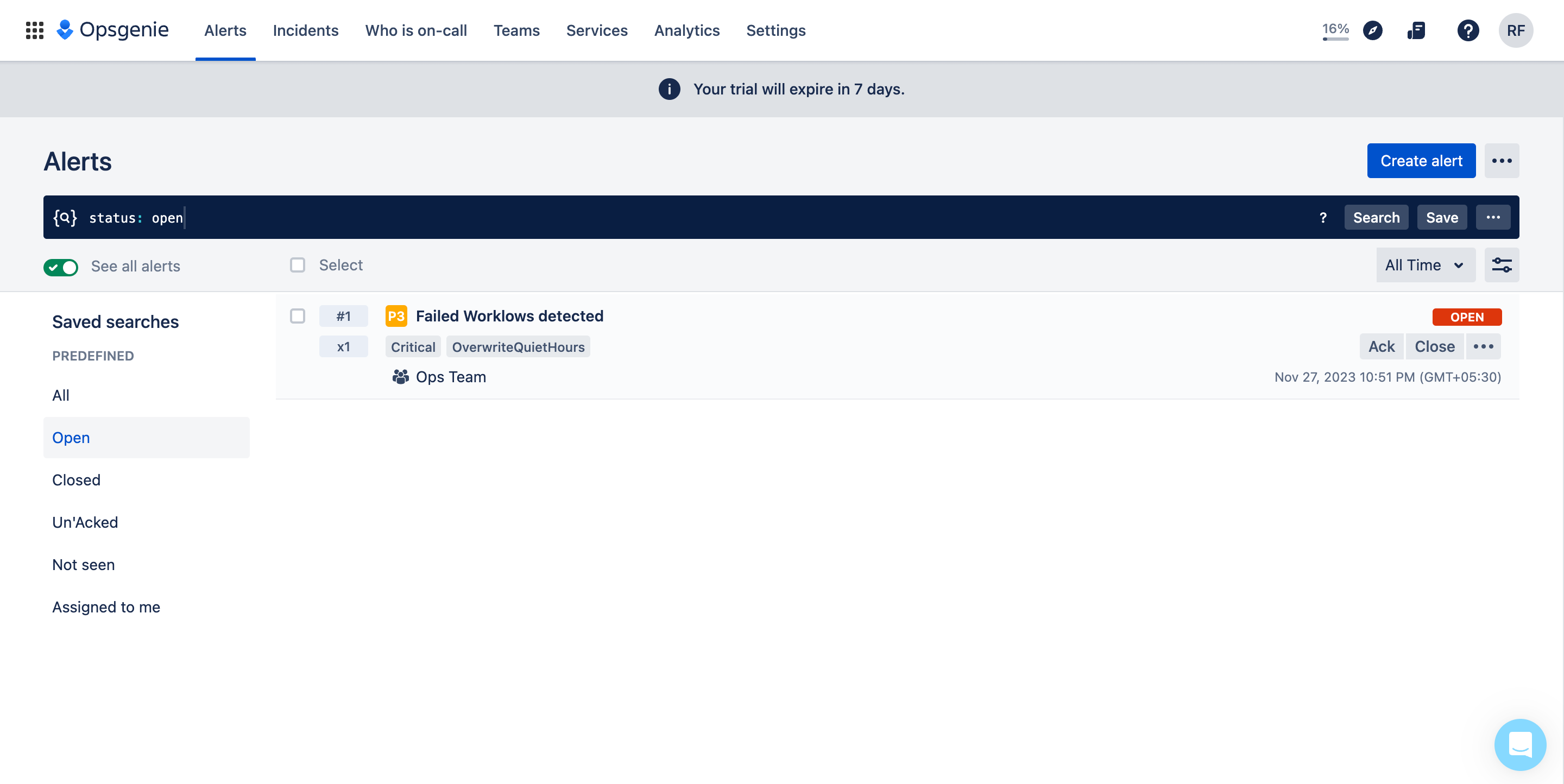
This alert is to be picked up by the people assigned as per Opsgenie parameters specified while defining/running the app in Orkes Conductor.
And ta-da! You have successfully sent the alerts on the failed instances of your application to Opsenie.
So, in this example, this application fetches the failed instances of your service app in the last 15 mins. Now, let’s automate it a bit more.
With the scheduler functionality in Orkes Conductor, you can create a schedule that runs your failure detection application every 30 minutes so that you get notified if there is any app downtime.
Let’s quickly create the Schedule from the execution you ran just now.
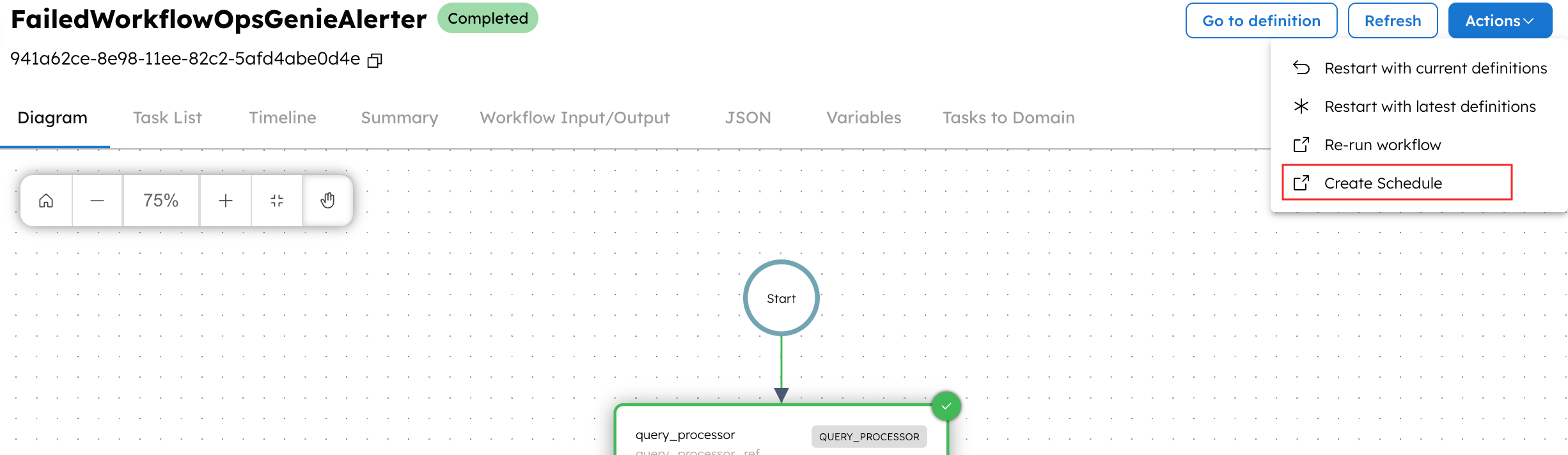
From the Actions drop-down, choose Create Schedule. This creates a scheduler with your failure detection application, and you can set the following cron expression so that it runs every 30 minutes:
0 */30 * ? * *
That’s the flexibility of the Conductor. You can leverage Orkes Conductor to find the instances of failed applications within apps built on Orkes Conductor itself.
Check out this video guide summarizing the sample execution:
You can send quick alerts to Opsgenie on any app downtime every 30 minutes through this sample alerting application we created. This can be assigned to respective developers/SRE teams for quick resolution, and hereby, you can ensure that you stick with the app uptime of 98% in your SLA.
That’s just a simple use case that can be implemented with Orkes Conductor. The flexibility of the Conductor is that you can modify these as per your requirements.
Should you require assistance setting up your Conductor, please don’t hesitate to reach out to our team via the Slack community.
In a nutshell, this powerful combination of Opsgenie and Orkes Conductor can create a robust system that identifies and addresses issues promptly and lays the foundation for continuous improvement.
To experience the firsthand benefits of this powerful duo, consider leveraging Orkes Cloud. Orkes Cloud is offered in all major cloud platforms, including AWS, Azure & GCP. Try it out with our free developer sandbox, Orkes Developer Edition here.
Meanwhile, don’t forget to ⭐ our Conductor OSS repo here!