PRODUCT
Running a Billion Workflows a month with Orkes Conductor

Viren Baraiya
CTO
Last updated: January 10, 2023
January 10, 2023
8 min read








Join thousands of developers building the future with Orkes.
Editor’s Note: This post was originally published in Sep 2022 in Medium.
Conductor is a well known platform for service orchestration allowing developers to build stateful applications in the cloud without having to worry about resiliency, fault tolerance and scale. Conductor allows building stateful applications — automation as well as human actor driven flows by composing services that are mostly stateless.
At Orkes, we regularly scale Conductor deployments to handle millions of workflows per day and we often get questions from the community on how to scale the Conductor and if the system can be scaled to handle billions of workflows.
We ran a benchmark to test the limits of Conductor’s scalability using a simple single node setup on a laptop. The results were not so surprising, given our experience with Conductor, — with the right configuration, Conductor can be scaled to handle the demands of really large workloads.
Throughput
Latency

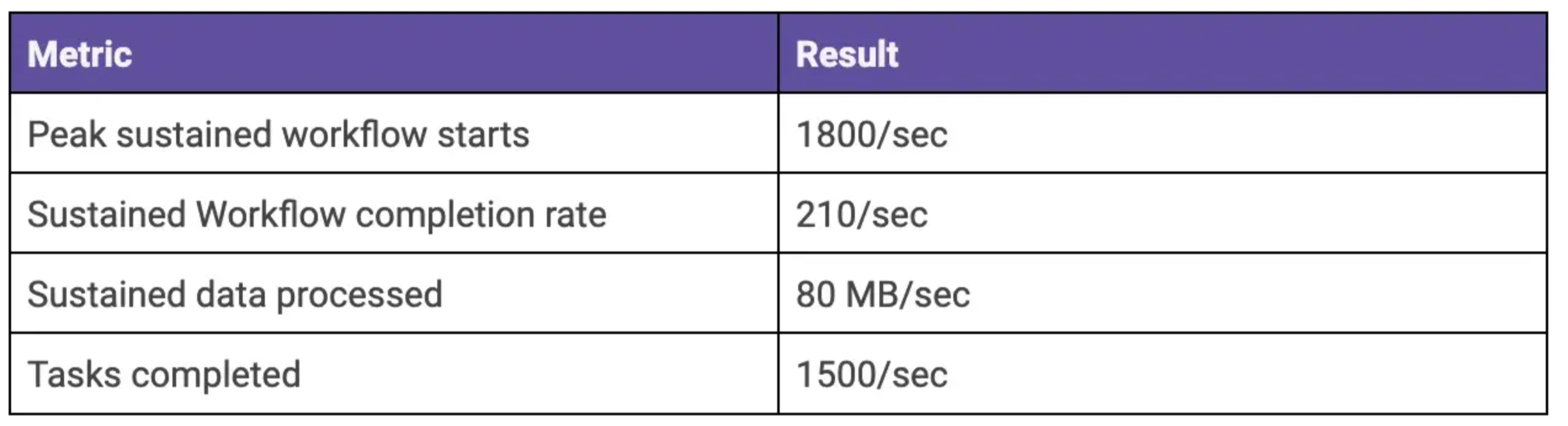
We measured the peak stable throughput Conductor can achieve on the following parameters:
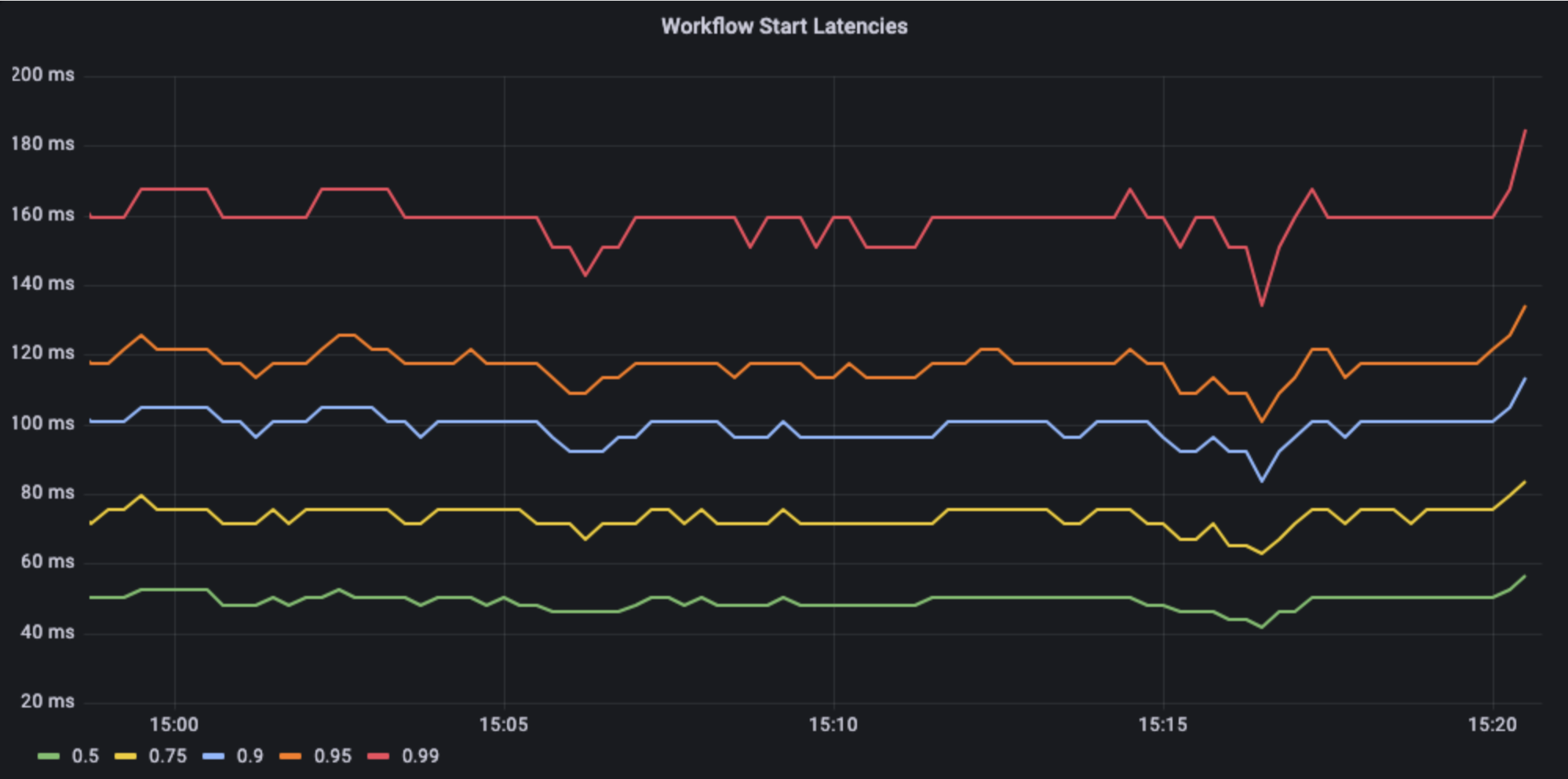
We measured p50, p95 and p99 latencies for the critical APIs in Conductor:
We used wrk2, a fantastic tool to generate stable load on the server. Wrk2 improves on wrk and adds the ability to generate sustained load at a specific rate (-R parameter).
We created a load testing workflow which is complex enough with a total of 13 steps.
For the experiment a set of load testing workers were created that were used to poll for the tasks in the workflow, and produce a dummy output.
Conductor has a pluggable metrics system and we used Prometheus to capture and Grafana to visualize various metrics.
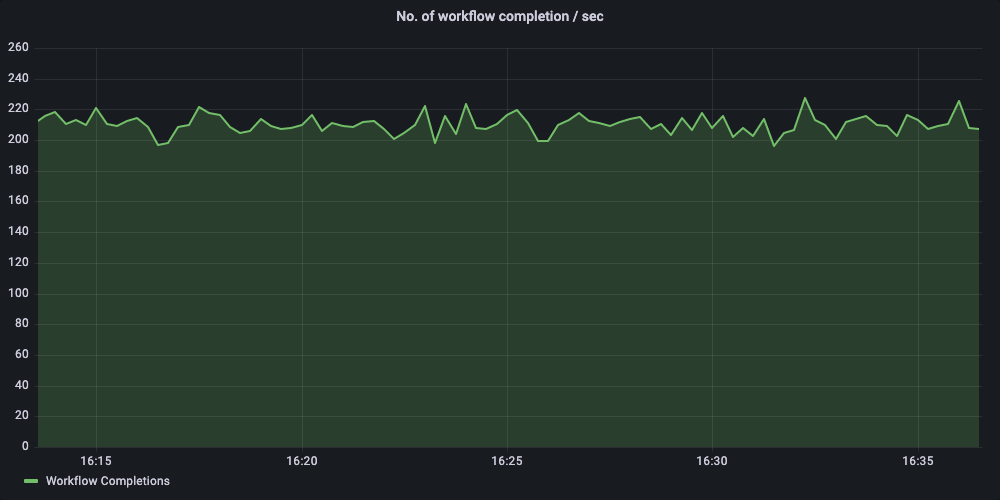
The experiment was designed to send a sustained workload of 200+ workflow executions / sec. The test workflow also embedded a sub-workflow with a single step inside, so during the experiment, we were starting approximately 400+ workflow/sec.
For the Conductor version, we used Orkes’ build of Conductor that is tuned and customized to handle large workflows with minimal latency possible and optimize the operational costs.
We have a version of this available under open source at https://github.com/orkes-io/orkes-conductor-community.
Conductor servers are a horizontally scalable system, for this test we ran a single node server — of course your production setup should have at-least 3 nodes in multiple availability zones / racks for higher availability.
The Conductor server was running on a Macbook Pro with M1 Max CPU and 64GB of RAM. The same machine also ran a single node redis server. Postgres database was running on another Macbook Pro with M1 Max CPU and 32GB of RAM. The same machine also ran task workers. A Core i9 Macbook pro with 32 GB RAM ran Prometheus, Grafana, a load generator docker container and task workers.
The systems communicated over WiFi 6 network — no wired connectivity, which potentially could have improved latencies a bit. The machines were roughly equivalent to a c7g.2xlarge instance type of AWS (memory consumption in the tests was below 16GB offered by this instance type).
Testing the limits of how many workflows can be started in a burst. For this experiment we wanted to remove any network latencies so we ran the wrk on the same host as the Conductor server running thereby removing any network latencies out of equation. This gives us a theoretical max request/sec assuming the network is limitless (which it isn’t’).
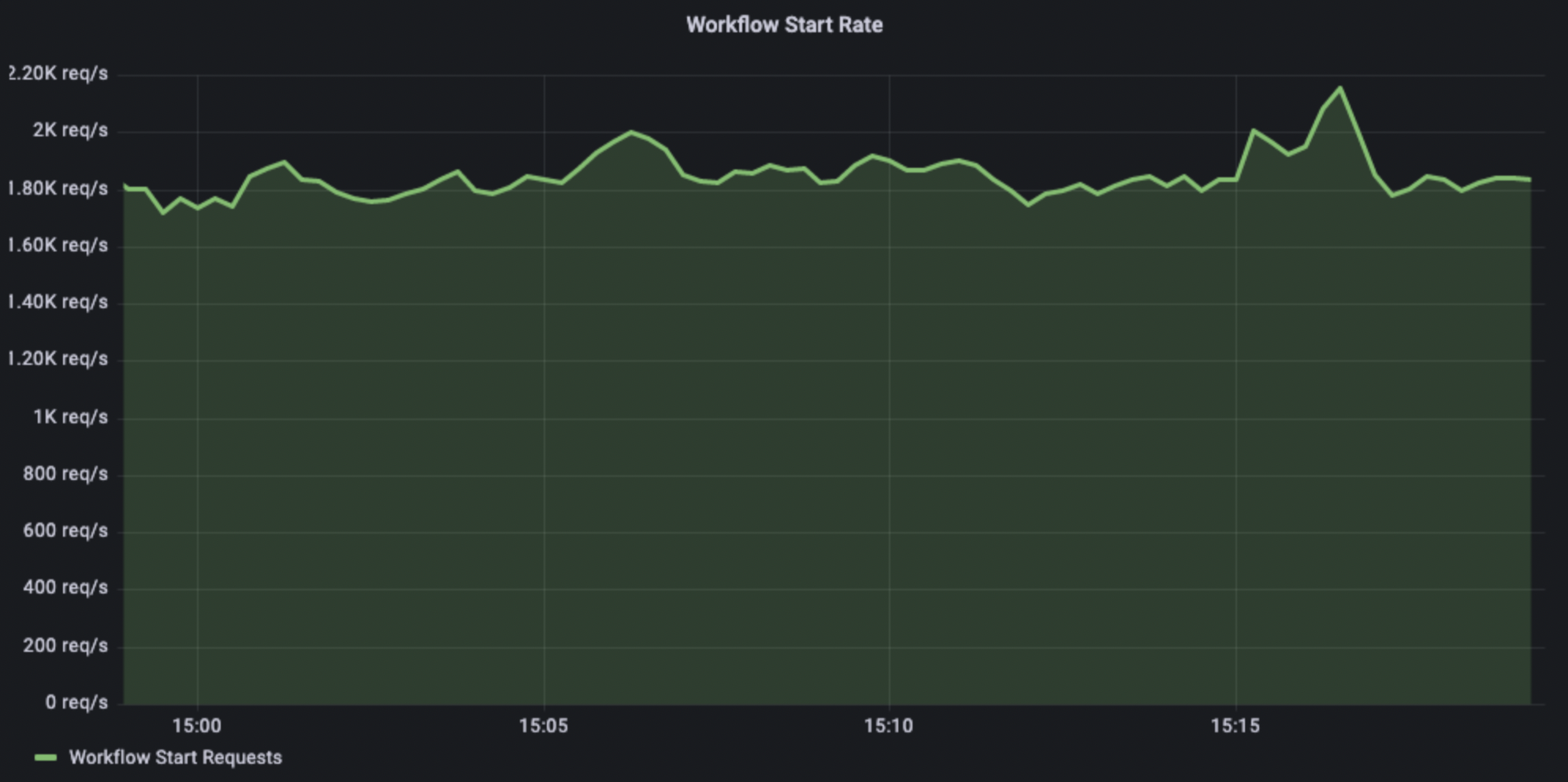
For this experiment, we asked a question:
If all the tasks in a workflow were instantaneous, how many workflows can we start and complete in a second with a sustained load such that there is minimal backlog of the tasks.
To test this, we used wrk2 to send a sustained load of 210 workflow execution requests, where each workflow contains a sub workflow and worker tasks.
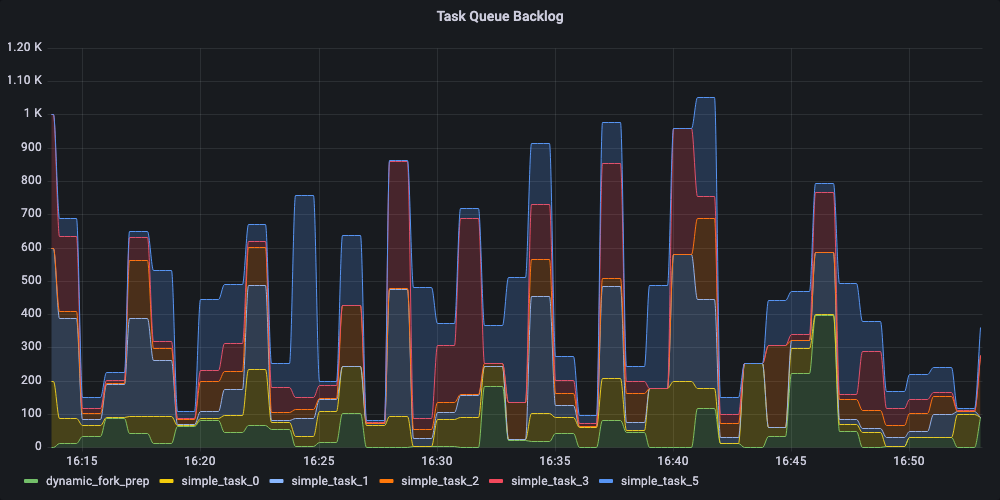
Conductor publishes the depth of the pending task queue, this is useful when deciding when to scale up/down your worker clusters. Here is the snapshot of the worker queue depth. High numbers for a given task indicates the worker resource starvation and need to scale the worker cluster to fulfill the demand.
We achieved a consistent throughput of 1450+ task executions / sec. This included polling for the task, executing the business logic (in our case producing randomized test output) and updating the task status on the server by workers. Each successful task completion initiates the state transition of the workflow.
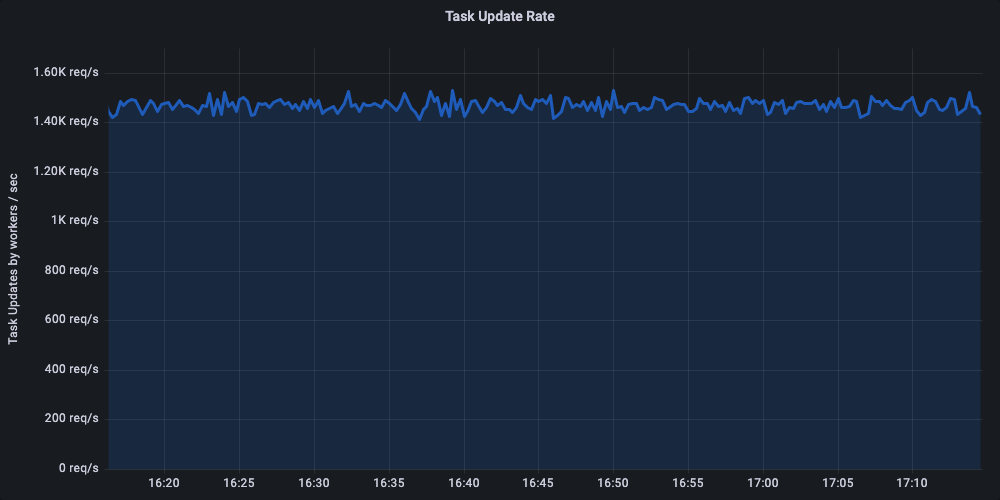
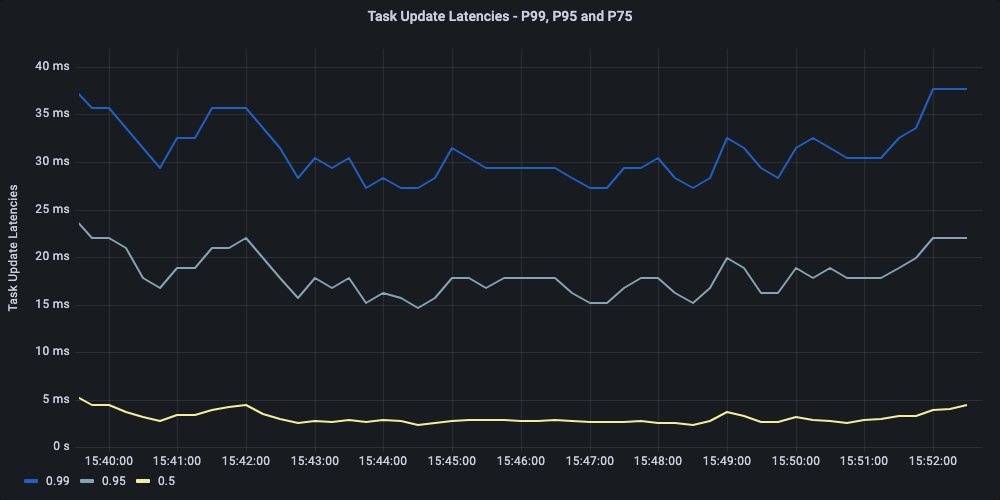
Critical to the throughput is the update of the task execution back to the Conductor server. This is the most critical API operation we found that is directly responsible for the throughput of the server. We optimized the server to limit the tail latencies ensuring p99 stays well under the check.
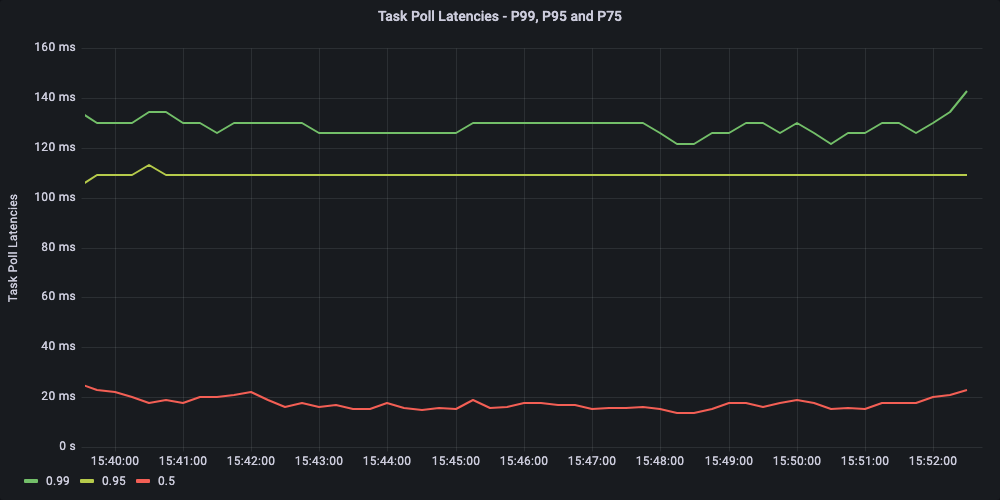
Conductor uses a long-poll for the task polling, and the request waits until there is a task available for the worker or the timeout, with the timeout set to 100 ms in this experiment. Polling implements batching for more efficient use of the network and connection. In the test, the batch size was set to 10 for the tasks by workers.
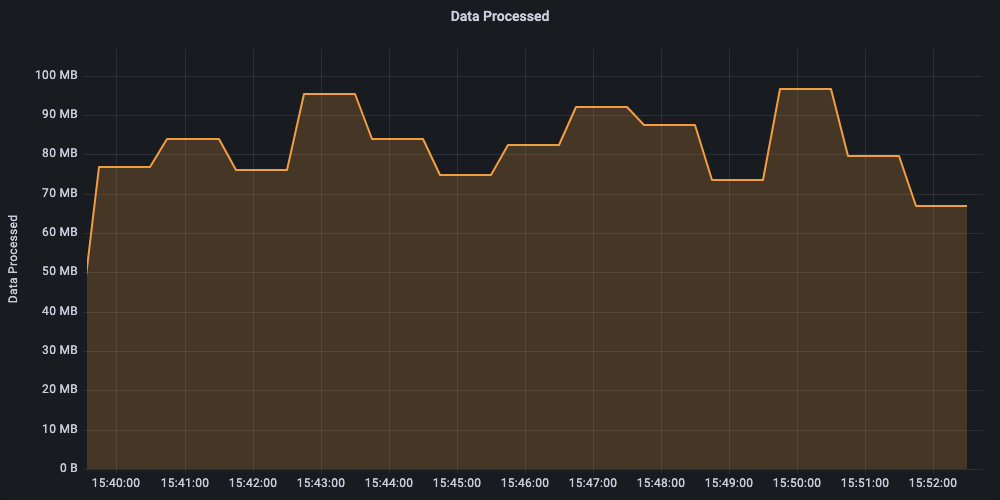
We generated fake data for the test to simulate the real world scenarios in terms of data transfer. The amount of data being processed by workflows impacts the requirements for provisioned IOPS (on cloud environments) and Network throughput requirements.
The experiment averaged a sustained rate of ~80 MB/sec data processed.
The experiment used a total of 3 commodity hardware (roughly equivalent to c7g.2xlarge instance types on AWS). Throughout the experiment JVM heap size consistently remained below the 2GB mark.
The experiment created a workload of 210 moderately complex workflows per second, which if run constantly for a month will generate about 540M workflows.
Conductor servers themselves are stateless and can be scaled out to handle larger workload demands. Each of the server nodes can handle the workload based on the available CPU and Network and can be scaled out to handle larger workloads.
Redis serves as the backbone for state management and queues used by servers to communicate. Scaling higher workload requires either scaling up redis or using redis cluster to better distribute workload.
Postgres is used for indexing of workflow data. Beyond the disk storage requirements, scaling postgres requires two factors 1) adequate CPU and 2) IOPS required (especially on cloud environment) to handle the writes under heavy workloads. Writes to postgres are asynchronous done using durable queues (check out orkes-queues) but longer delays means completed workflows remain in Redis for longer periods of time, requiring larger Redis memory.
We often get asked, can Conductor be scaled to handle billions of workflows per month? The answer is a resounding YES it can. If you would like to give it a try, check out our Developer Edition at https://developer.orkescloud.com/.
Orkes, founded by the founding engineers of Netflix Conductor, is a fully managed service offering Conductor as a hosted service in the cloud and on-prem.
Don’t forget to give us a ⭐️ https://github.com/conductor-oss/conductor