PRODUCT
Fail Fast, Recover Smart: Timeouts, Retries, and Recovery in Orkes Conductor

Karl Goeltner
Software Engineer
Last updated: May 12, 2025
May 12, 2025
5 min read








Join thousands of developers building the future with Orkes.
In distributed systems, failure isn’t a possibility—it’s a certainty. APIs hang, workers crash, and networks drop. What matters isn’t avoiding failure, but recovering from it quickly and cleanly.
Orkes Conductor gives you the tools to do exactly that. Timeouts and retries aren’t just configurable—they’re core to how Conductor ensures reliability at scale. In this post, you’ll learn how to use them effectively at both the task and workflow levels, how they interact with failure workflows, and how to design resilient systems that heal themselves without manual intervention.
Let’s dive in.
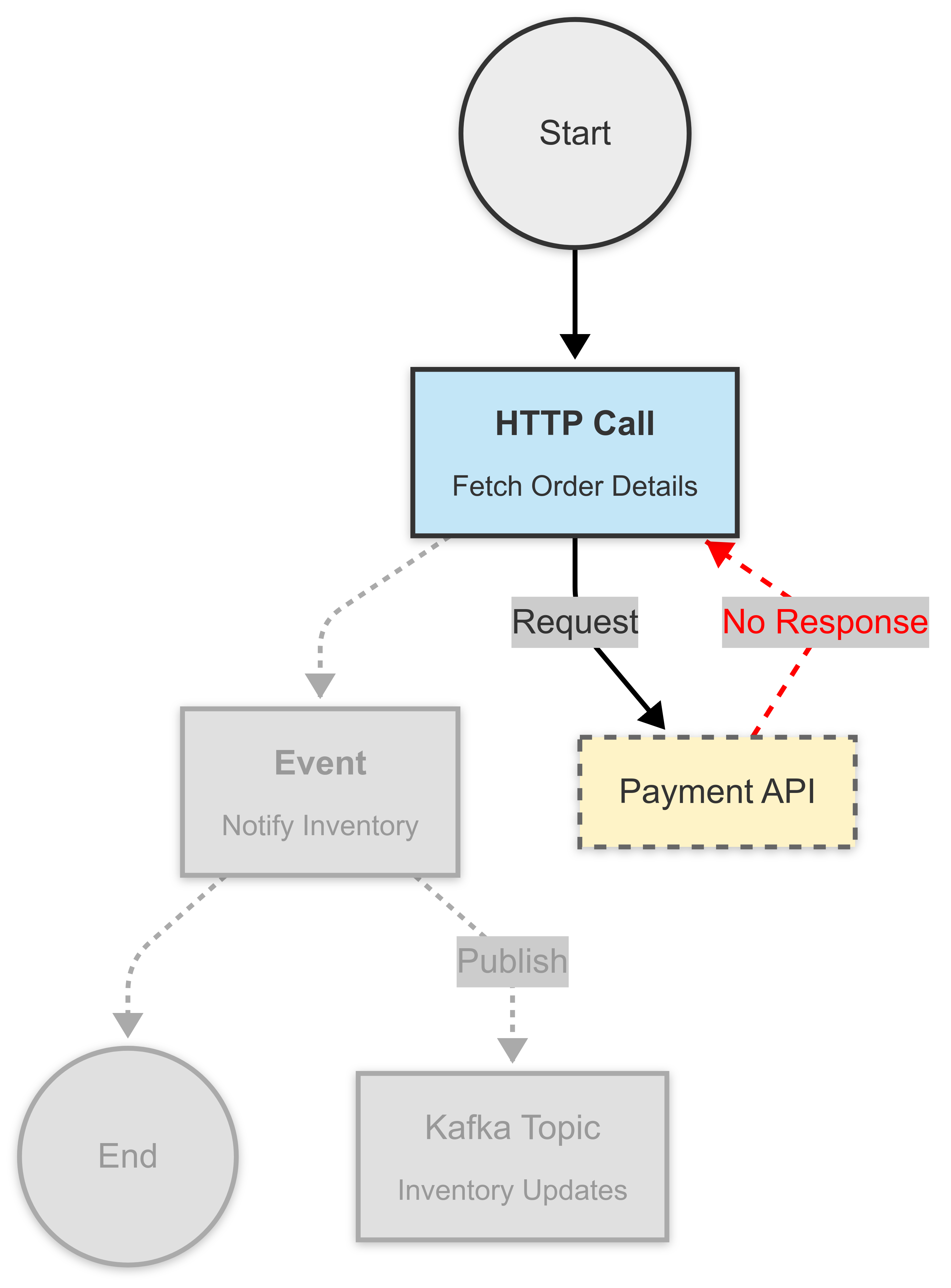
Imagine you're orchestrating a payment flow. After the user places an order, your workflow triggers tasks to charge the card, update inventory, and send a confirmation email.
All good—until the inventory API goes silent.
Now you're in a mess: the card is charged, but inventory isn’t updated, and the user doesn’t get a confirmation. This is exactly the kind of situation timeouts and retries are designed to avoid.
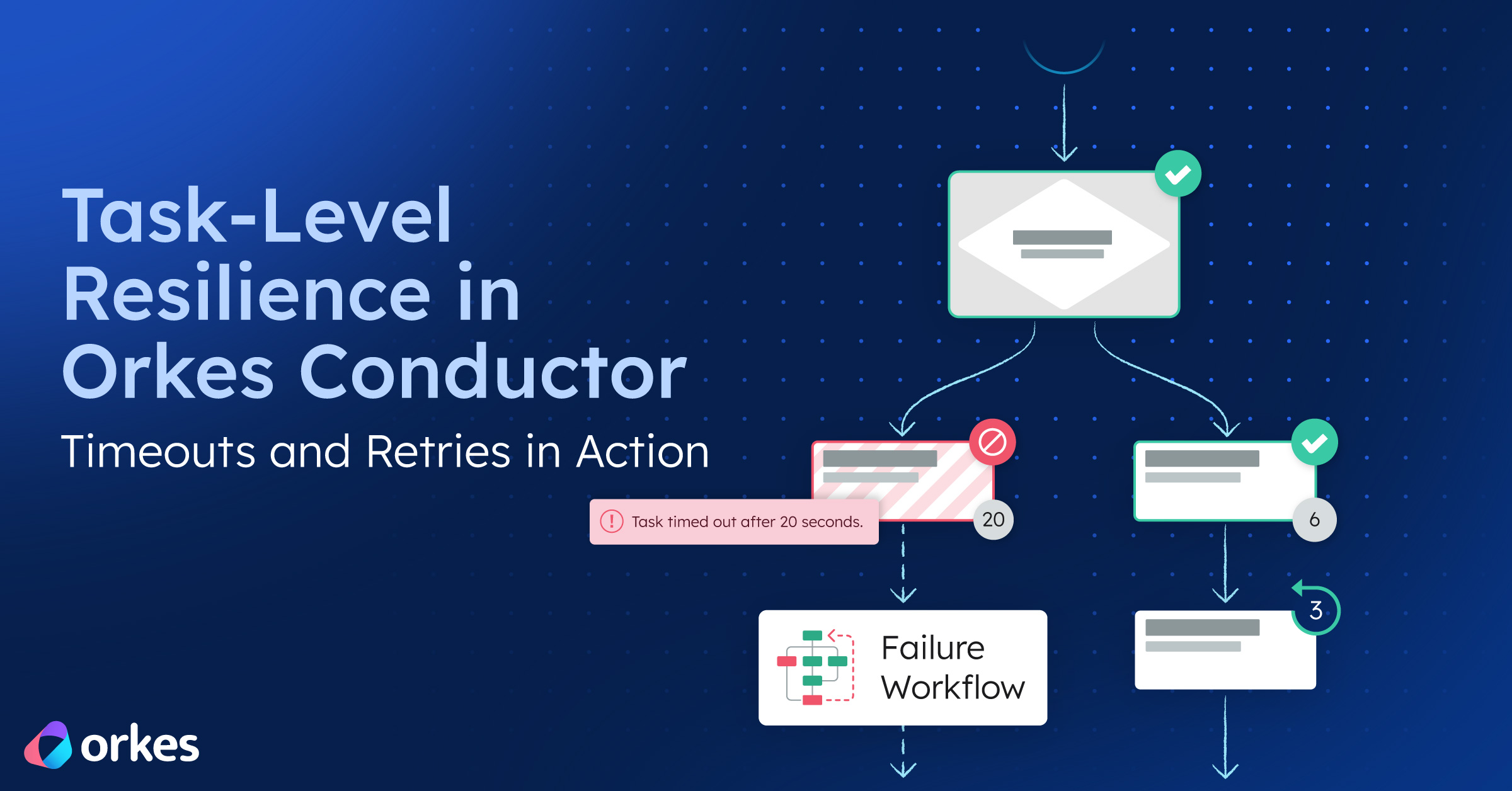
In Orkes Conductor, timeouts and retries work together to provide resilience and control:
Together, they help you gracefully handle:
This is more than resilience—it’s control. Instead of writing custom error-handling logic for every edge case, you get:
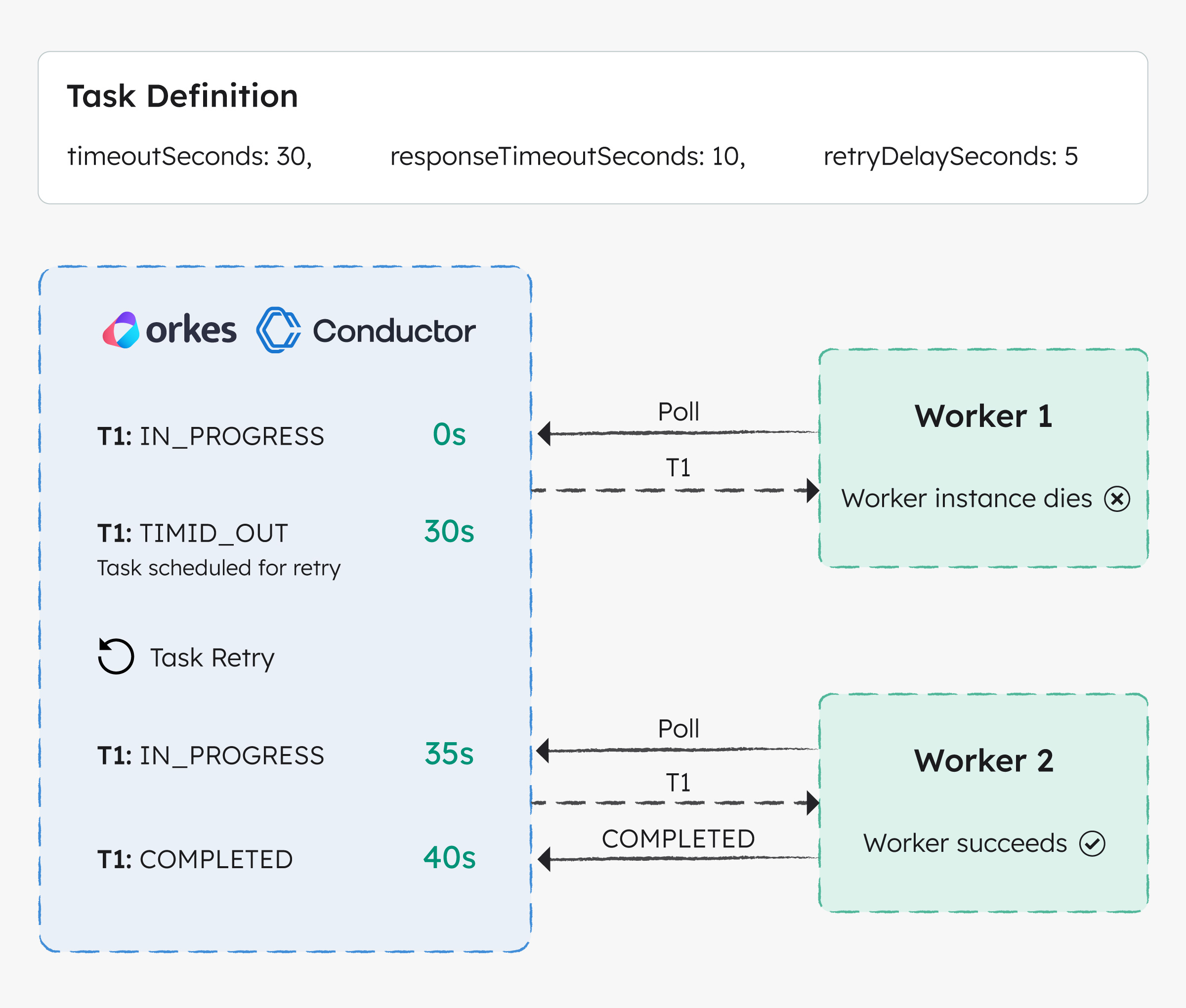
As you design resilient workflows, it’s important to understand the difference between timeouts and retries for individual tasks—they solve different problems:
| Aspect | Retry | Timeout |
|---|---|---|
| What it is | A second (or third, etc.) attempt to run the same task after it fails. | A time limit for how long a task is allowed to run (or how long you wait for it to start/progress). |
| Trigger | Happens after a task fails (e.g., returns FAILED). | Happens if the task takes too long to respond to or complete. |
| Example | API call fails with 500 Internal Server Error → Retry it after a delay. | API call hangs with no response after 30 seconds → Timeout triggers a recovery action. |
| Configured via | retryCount, retryLogic, retryDelaySeconds, backoffScaleFactor | timeoutSeconds, pollTimeoutSeconds, responseTimeoutSeconds, timeoutPolicy |
In short:
Both are essential for robust, fault-tolerant tasks.
Just like tasks, entire workflows can time out or fail, and Conductor gives you powerful tools to handle those cases gracefully.
| Aspect | Workflow Timeout | Failure Workflow |
|---|---|---|
| What it is | A maximum time limit for the whole workflow to complete. | A backup workflow that runs automatically when the original workflow fails. |
| Trigger | Happens when the workflow exceeds its configured timeout. | Happens when the workflow ends in FAILED or TERMINATED status. |
| Example | A data pipeline takes too long (e.g., > 2 hours) → Workflow is marked TIMED_OUT. | A workflow fails due to repeated task failures → A failure workflow sends alerts and logs diagnostics. |
| Configured via | timeoutSeconds, timeoutPolicy | failureWorkflow |
In short:
Together, they make workflows self-aware and recoverable.
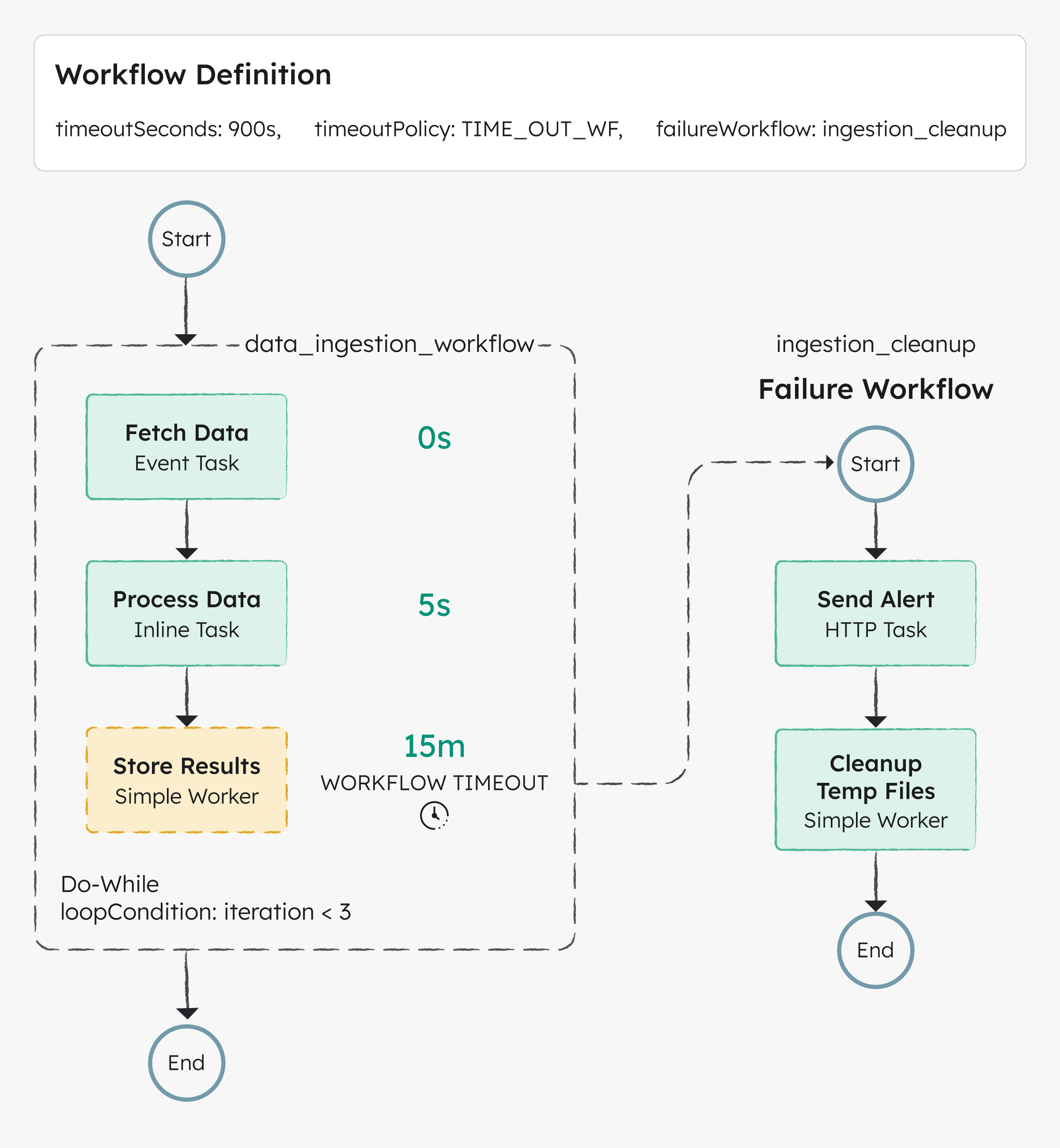
Retries give tasks more chances. Timeouts limit how long each attempt can run. Workflow timeouts cap the total duration of the workflow. If all else fails, failure workflows take over.
Here’s how it all fits together:
retryCount).This layered approach gives you fault-tolerance at every level:
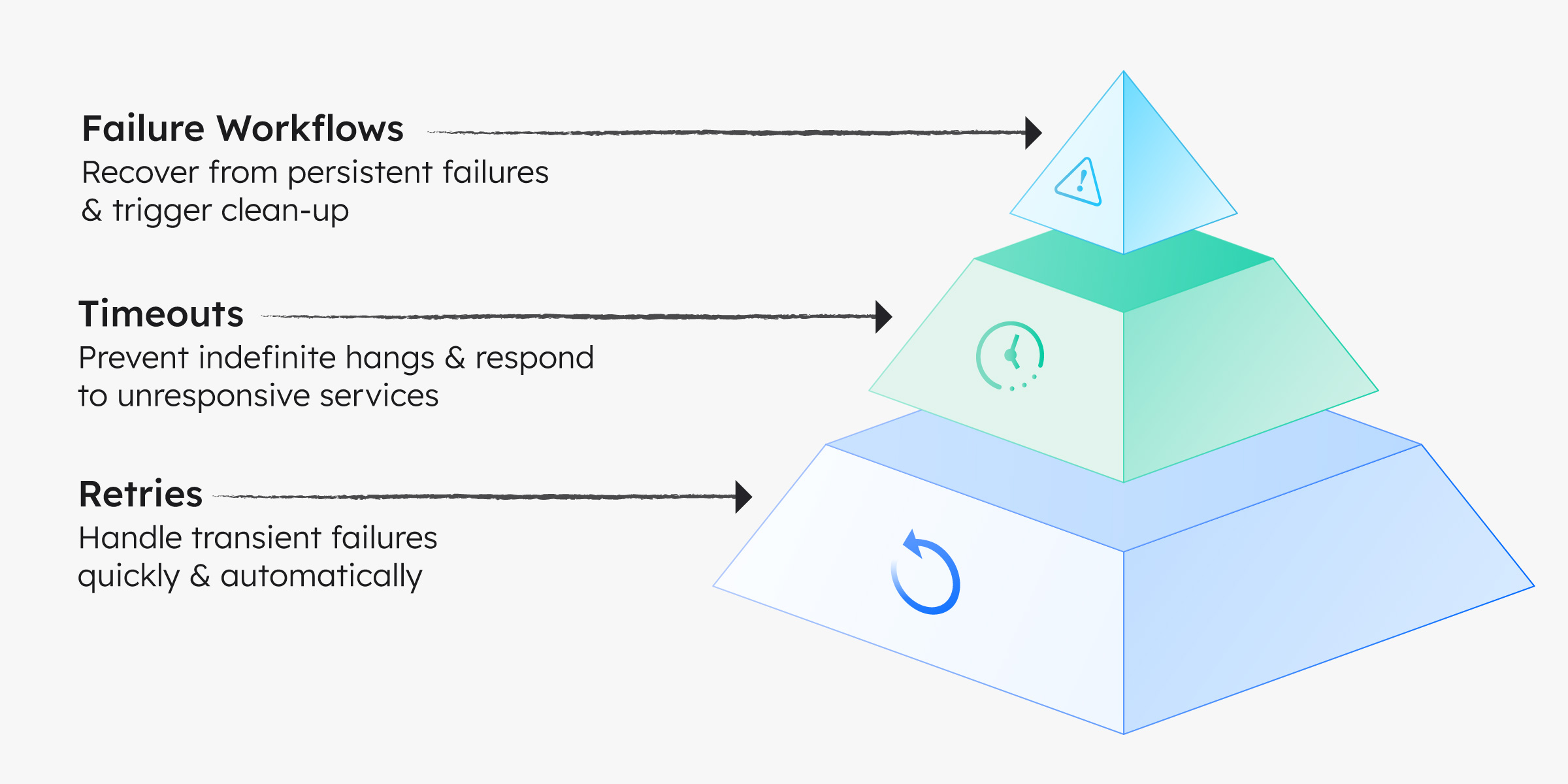
Orkes Conductor ships with sane defaults.
Task retry settings
{
"retryCount": 3,
"retryDelaySeconds": 60,
"retryLogic": "FIXED",
"backoffScaleFactor": 1
}
Task timeout settings
{
"responseTimeoutSeconds": 600,
"timeoutSeconds": 3600,
"pollTimeoutSeconds": 3600,
"timeoutPolicy": "TIME_OUT_WF"
}
Workflow settings
{
"timeoutSeconds": 0,
"timeoutPolicy": "ALERT_ONLY",
"failureWorkflow": ""
}
These are a solid starting point, but not always ideal for your SLAs.
Override the defaults when:
On the flip side, don’t override just for the sake of it. Defaults help reduce configuration sprawl and are good enough for many internal service workflows.
In distributed systems, failure is inevitable, but downtime doesn’t have to be. With Orkes Conductor, resilience is built in, not bolted on.
Timeouts help prevent indefinite hangs, and retries offer automatic recovery from transient issues. Workflow-level timeouts and failure workflows ensure your entire system can fail gracefully and bounce back, without manual intervention.
By combining these tools thoughtfully, you get more than reliability—you get confidence—confidence that your workflows will keep running, even when parts of your system don’t.
So, whether you're orchestrating high-stakes payment flows or background data pipelines, remember: design for failure, recover automatically, and keep moving forward.
Go more in-depth with task and workflow resilience with these follow-up articles:
—
Orkes Conductor is an enterprise-grade orchestration platform for process automation, API and microservices orchestration, agentic workflows, and more. Check out the full set of features, or try it yourself using our free Developer Edition.