ENGINEERING
Evolution of Software Architecture: From Mainframes and Monoliths to Distributed Computing

Liv Wong
Technical Writer
Last updated: August 6, 2024
August 6, 2024
10 min read








Join thousands of developers building the future with Orkes.
Software architecture—the blueprint of our digital world—has evolved tremendously since the dawn of the computer age in the mid-20th century. The early 1960s and 70s were dominated by mainframes and monolithic software. Today, the digital landscape looks entirely different, running on a distributed web of cloud computing, API connectivity, AI algorithms, microservices, and orchestration platforming.
How has software architecture evolved over the years? As we revisit the technological progress through the decades, we will see how changes in business needs, market trends, and engineering practices have impacted software architecture.
The first computers were mainframe computers—large, powerful hardware machines that took up an entire room. Mainframes originated as standalone machines that could run complex computing tasks. Prior to the 1970s, instructions to mainframe computers were sent via punchcards or magnetic tape, and the output received via printers.
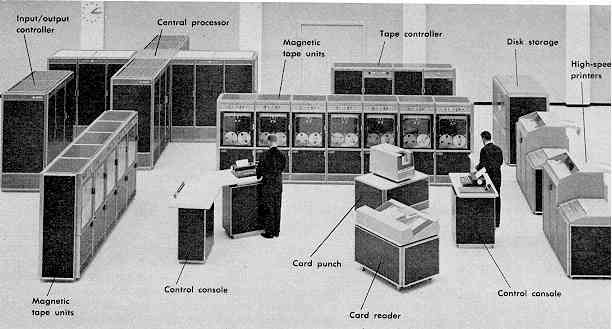
The first mainframes, Harvard Mark I and ENIAC, were developed for military and research purposes in the 1930s-1940s. In 1948, the first commercial mainframe was introduced to the world: UNIVAC. The following decades saw widespread adoption by banking, financial, and airline sectors for the mainframe’s outstanding ability in batch processing transactional data. Many of these systems still remain in operation today.
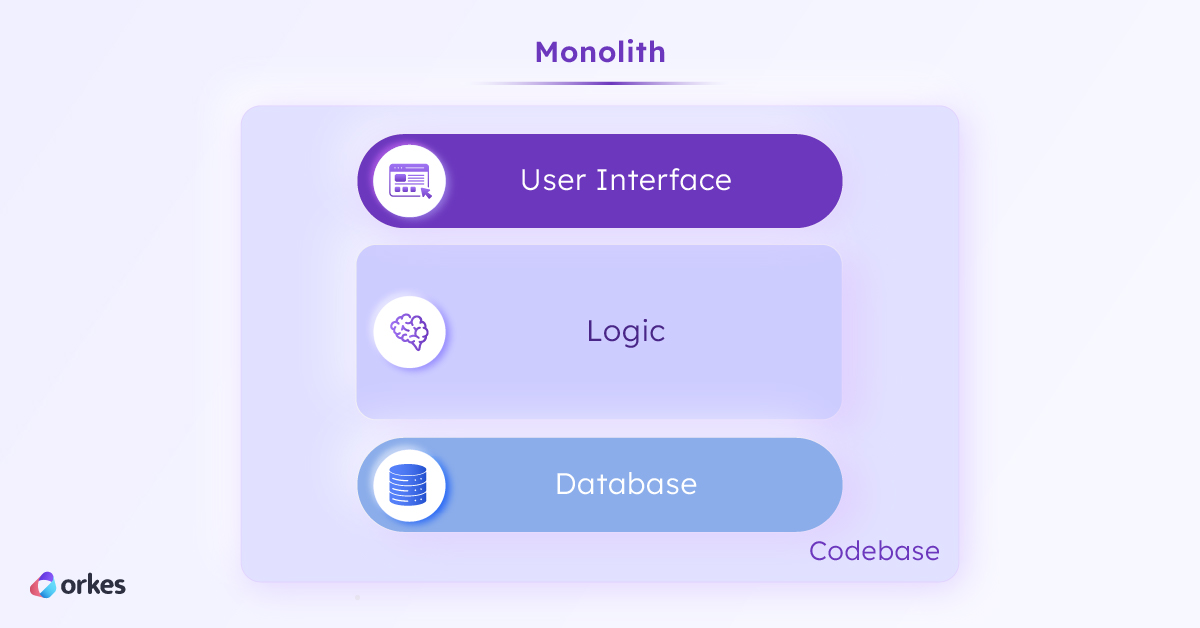
Mainframe applications were programmed in COBOL (Common Business-Oriented Language), which remains popular amongst mainframers even today. The software architecture for these applications was monolithic, which meant a single, unified codebase that contained the data schema, application methods, database connections, presentation logic, and so on without modularization. To update any of these components, developers would have to access the entire codebase and redeploy it in a single package.
Networks connect and facilitate communication between computers—mainframe to terminal, mainframe to mainframe, and later client to server. The development of network technology from 1958 onwards enabled mainframes to be connected electronically, transforming them into multi-user computers that were connected to multiple terminals. Instead of punchcards and printers, people could use a monitor, keyboard, and a command-line interface (CLI) to send and receive data.
Technological limitations restricted the first few connected computer systems. Multiplex mainframes, for example, could only be used locally as the cable length meant that the terminals had to be positioned very close to the mainframe. These early data centers contained not just computers, but dozens of humans sending jobs to the mainframe.
ARPANET was the first public, wide-area computer network, going live in 1969. It communicated data using packet switching, which went on to serve as the foundation for modern-day Internet as we know it.
Network technology popularized the client-server structure in the 1980s, where an application is divided into a server software and a client software that communicates over a computer network. This structure is familiar to us today: a client, typically a desktop computer, remotely makes a request to a server, which returns a response. With the distribution of computing resources, the server handled data processing and retrieval while the client dealt with the presentation of the data.
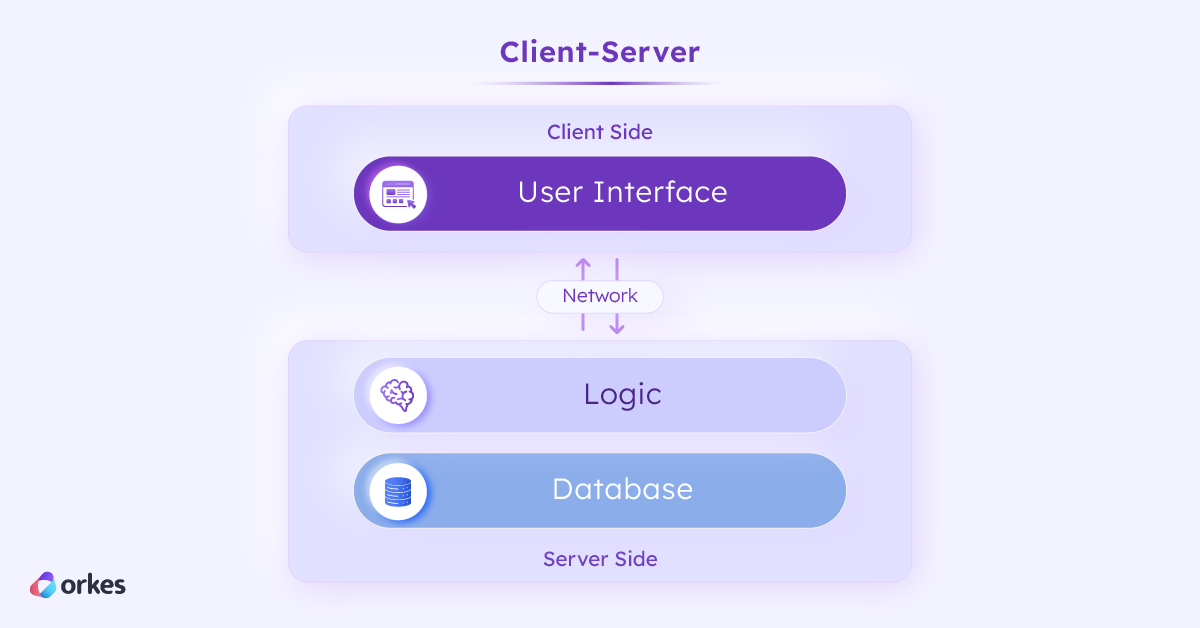
The first client-server applications were mail services, web servers, and other desktop applications with online capabilities. Today, client-server has become the standard paradigm for most applications, and more broadly encompasses a general model of a service requester and a service provider.
Despite the two-tier separation, many such applications were still built in a monolithic fashion. All application features resided in a single codebase, tightly coupled, and shared access to a single database.
1983 marked the year of the Internet. The Internet was a global system of computer networks that used the TCP/IP protocol to facilitate communication between devices and applications. This was the backbone for FTP programs, SSH systems, and of course, the World Wide Web (WWW).
Although the Internet and WWW are used interchangeably today, the WWW was invented almost a decade later, in 1990. The WWW is an information system—a web of HTML content connected by links—shared and organized over the Internet using the HTTP protocol. It was a revolutionary way of storing information such that it could be accessed globally, paving the road for the era of websites and web programming.
In the early days, websites were static pages that displayed data from the web server. The introduction of the Common Gateway Interface (CGI) in 1993 brought web interactivity to the fore, kickstarting the prospects of web applications.
Fledging web interactivity took off with the invention of JavaScript in 1995, which brought scripting logic onto the client side. JavaScript quickly became the new standard for web programming, and web servers could more easily deliver dynamic, interactive content. These were the early forums, bulletin boards, and web forms.
The invention of the web and its latent possibilities soon kicked off the next wave of application development. Instead of building a dedicated client for your application, you could simply build a website to be hosted on the web.
As application development grew, a monolithic codebase became more unwieldy to manage, and it became clear that capabilities or data housed in one system could be reused in another.
To address these challenges, modularization became a topic of discussion. In the 1990s, the server side was further split into two tiers: the application server and the database. The application server stored all the application and business logic, while the database server stored the data records, which reduced latency at high processing volumes.
Around the same time, service-oriented architecture (SOA) emerged as an architectural pattern where software capabilities are designed as individual services that can be used with any system as long as the system followed its usage specification. SOA encouraged a move towards developing enterprise applications as loosely coupled services that interact through a communication protocol over a network, a pattern that has remained dominant today.
Under SOA, a shopping app would contain multiple services: one for inventory tracking, another for order processing, and yet another for user authentication. Unlike a microservice-based application, services in an SOA pattern still share the same database, through the application layer.
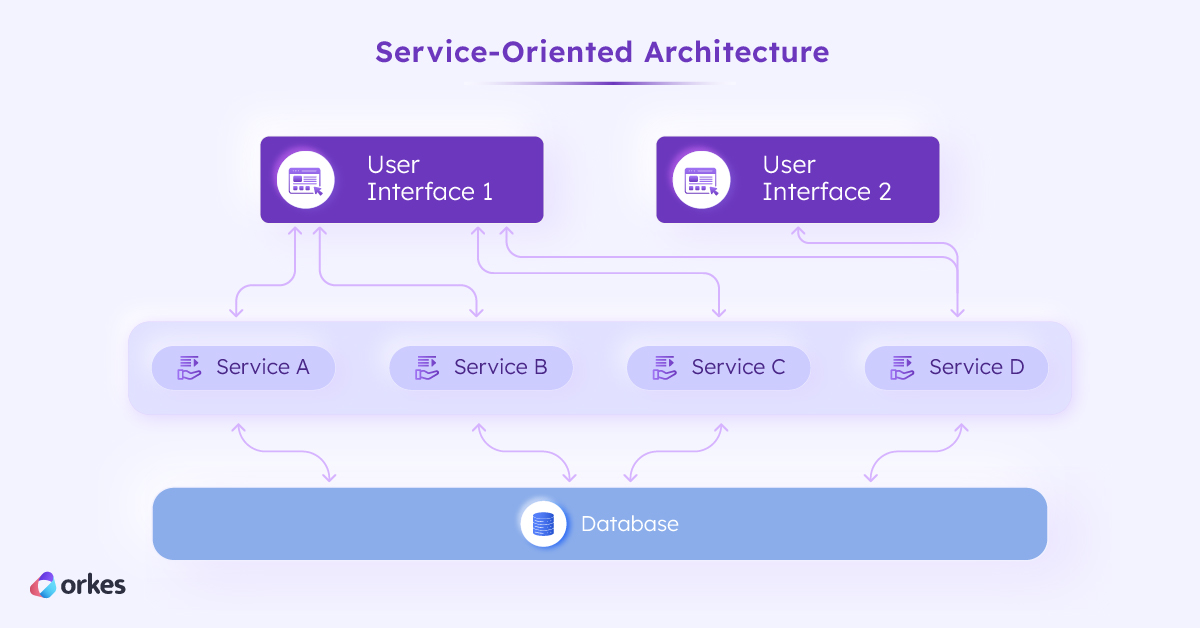
With SOA, came the need to define set standards and protocols for how these services interacted with all sorts of clients. DCOM and CORBA were some non-web-based standards soon overshadowed by web-based ones like SOAP and REST APIs. SOA offered a way for services from different providers to be integrated into one application or for the same services to be utilized on different clients, like a web portal or a dedicated desktop interface.
SOA set the stage for the move from traditional desktop applications to a new mode of software applications—SaaS—but it was the invention of virtual machines and cloud computing that further spurred the explosion of SaaS products in the coming decades.
Virtual machines, enabled by the hypervisor, are computer systems that exist on the software layer instead of as a physical machine. Using virtual machines, it became much easier to create, update, and destroy multiple machines that run different operating systems on a single computer, maximizing resource allocation and utilization for application development.
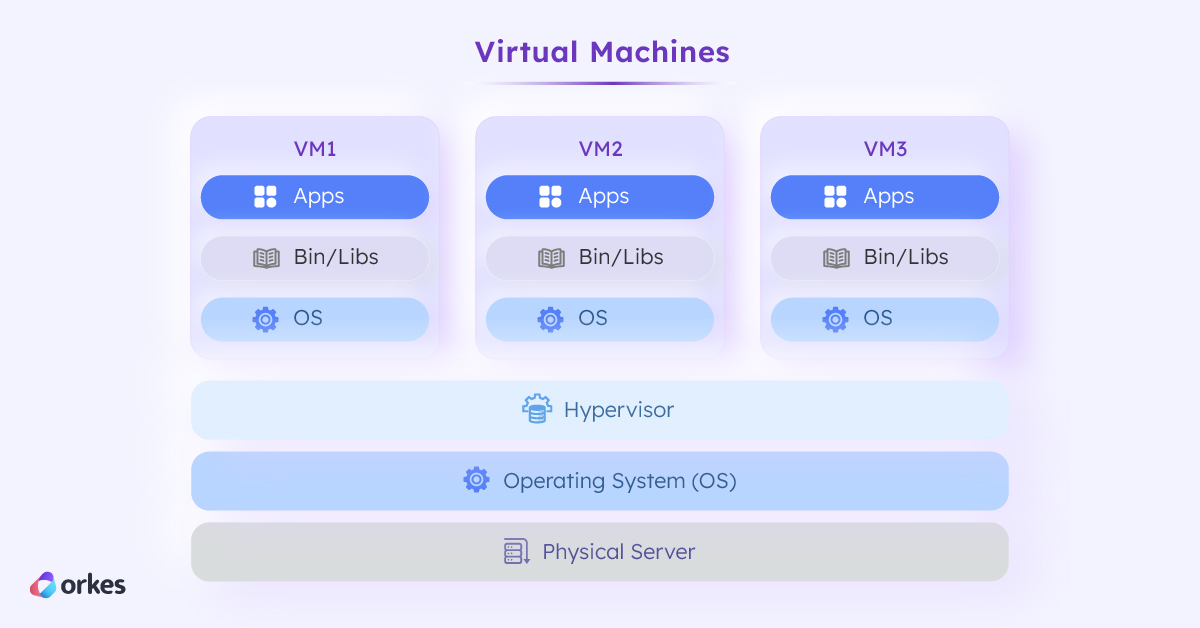
Although machine virtualization has existed since the 1960s, it only came into mainstream use in the 2ooos with the rapid succession of releases by Linux, Microsoft, and VMware. This was the period when companies like Amazon identified the lucrative opportunity that virtualization offered: managed cloud computing services. Physical bare metal machines are expensive and difficult to manage, a limiting factor when companies want to scale. With cloud computing services like Amazon EC2, companies could rent virtual machines for processing power and scale as required.
Growing companies like Facebook and Netflix could truly focus on building out their software capabilities without needing to maintain the underlying hardware of bare metal machines and data centers. The technical overhead to get started became much lower, accelerating the next wave of startups and digital-native businesses in the coming decades. In turn, this unlocked the next step in distributed computing and software architecture: microservices.
The 2010s were the culmination of multiple trends towards distributed computing. Fueled by the need for third-party access to their services, the first few commercial APIs were launched in 2000 by Salesforce and eBay, enabling their partners or customers to integrate features onto their own sites or applications. From Twitter and Google Maps to Stripe, Twilio, and now OpenAI, the API economy has ballooned since, powering integrated features across the web.
In the same vein, microservices took off when scaling companies like Amazon and Netflix needed to speed up and streamline the development cycle, which was slowed down by a monolithic codebase. By splitting up an application into individual microservices, each with its own database, teams could independently update and deploy them, leading to faster releases and improvements.
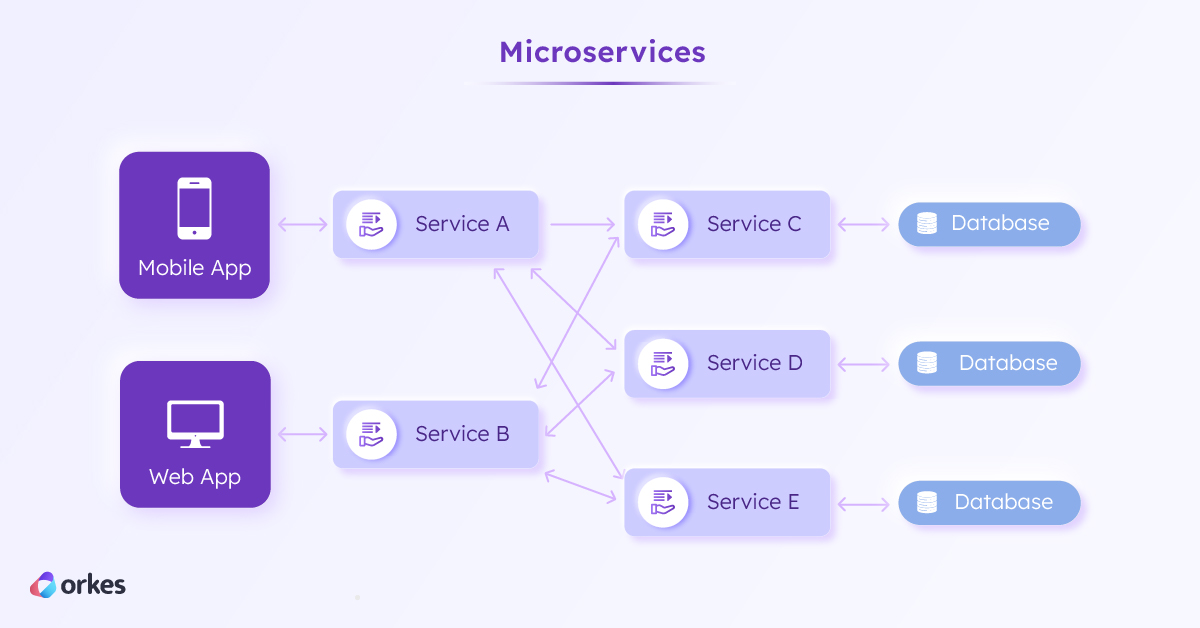
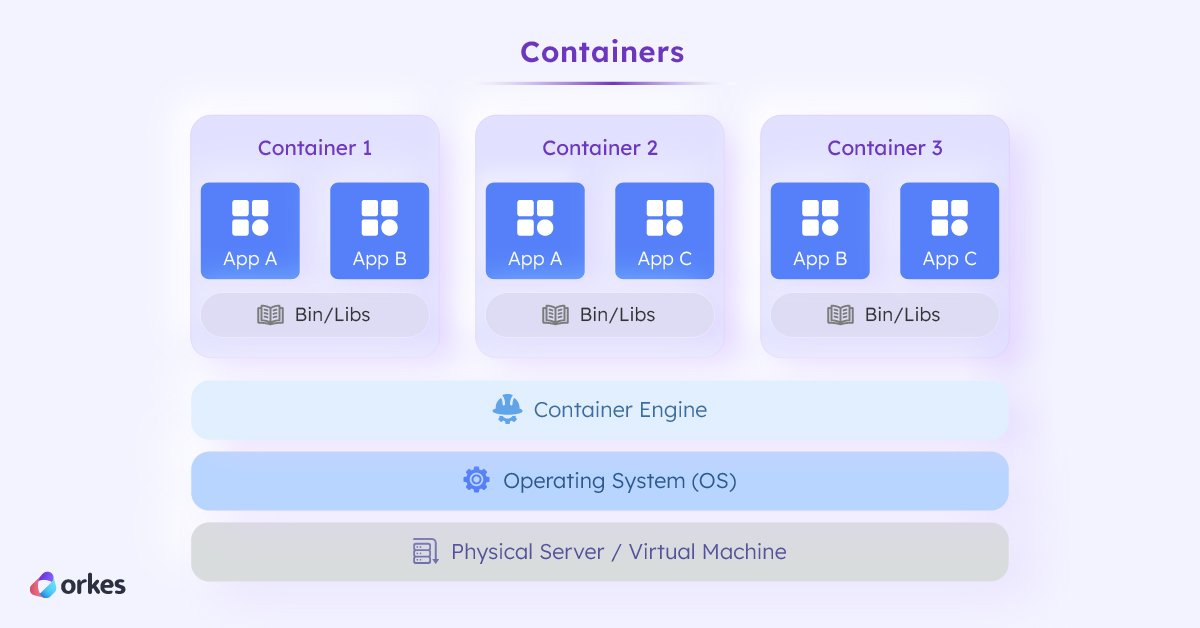
While there are many ways to package and deploy microservices—on a physical or virtual machine—the growth in microservice-based architecture was supported by the emergence of containers. Like virtual machines, containers were an abstraction layer conceptualized in the 1970s, but only launched into enterprise recognition after 2013 when Docker was made open-source.
Compared to virtual machines, containers provide a greater level of compartmentalization, so multiple instances and versions of the same application can run on the same operating system. All the components needed to run an application—code, run time, libraries, dependencies, and system tools—are stored within the container, offering greater portability and scalability for deploying applications or microservices.
With a patchwork of native or third-party services, databases, and so on, modern application development now requires a robust way to architect and integrate these different components. This brings us to the software architecture of today: orchestration and event systems.
With a distributed model of computing—microservices, APIs, and SOA to a degree—comes a pertinent problem in software architecture: how will these separate services, databases, and components communicate and interact with each other to flow cohesively?
There are two main approaches to resolving the issue of interdependency between distributed services: event-driven architecture and orchestration.
In an event-driven architecture, services push data into a service bus or event pipeline for any other connected service to read and execute if necessary. The overall system responds to events or state changes without keeping track of the impact of individual events on other events, thus reducing interdependency between each service.
While the concept of a service bus has been around since the emergence of SOA, the trend towards microservices has brought it even further to the fore, with the likes of Kafka and Amazon SQS. An event-driven system enables real-time updates and improved system responsiveness while unlocking increased throughput in parallel processing. This has powered systems with fast-changing updates, such as ride-hailing or airline transactions.
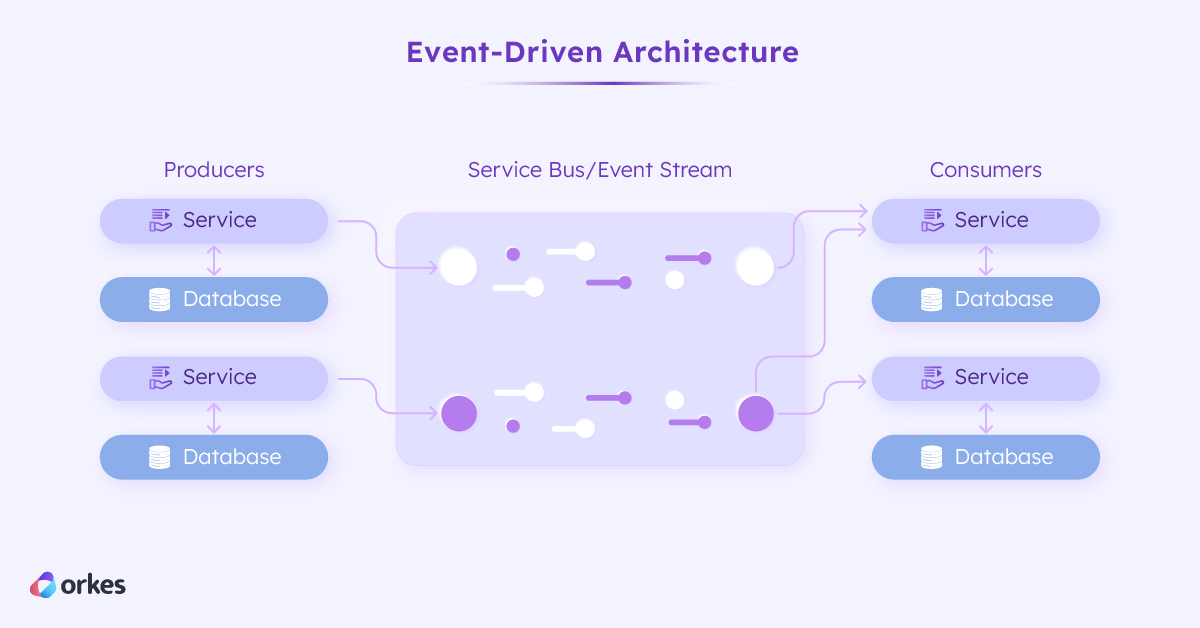
However, event streams do not provide insight into the overall state of the system and the progress of a process across distributed services. The lack of state tracking and visibility poses significant challenges when it comes to debugging and troubleshooting, as well as implementing error handling and resilience mechanisms. Designing an event stream that can properly handle sequential processes when there is no in-built chronology may end up overly complicated, requiring careful consideration of the event flow, routing, and handling.
Orchestration offers another viable solution to resolving the problem of microservice interdependency and even the issues encountered in event-driven architecture. In orchestration, a central orchestrator schedules each task or microservice based on a predefined flow, only proceeding to the next task in sequence when the previous one has been completed successfully. Unlike event streams, the orchestrator tracks the overall progress across each service, empowering developers to easily trace and debug errors and implement failure compensation.
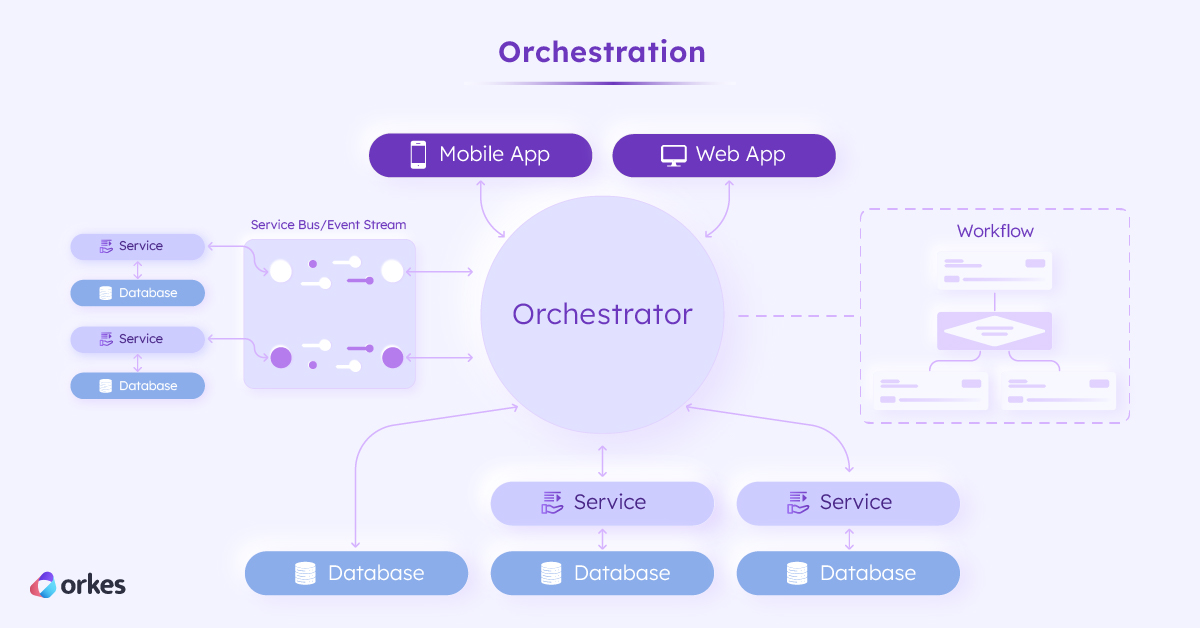
The orchestration layer forms an integral level of abstraction that coordinates separate services, databases, event streams, LLMs, and other components into a concerted process. From ease of integration to ease of tracking and troubleshooting, orchestration empowers developers to architect applications across the entire development lifecycle, seizing the world of software development with the likes of Orkes Conductor and Airflow. The durability of orchestration has streamlined many complex workflows, such as automating infrastructure upgrades or processing shipment orders over long periods of time.
We leave the history of software architecture at this juncture: orchestration as an architectural layer that unlocks the next step in distributed computing.
Throughout the past century, technology has advanced in leaps and bounds from mainframes and networks to virtual machines, containers, and genAI capabilities today.
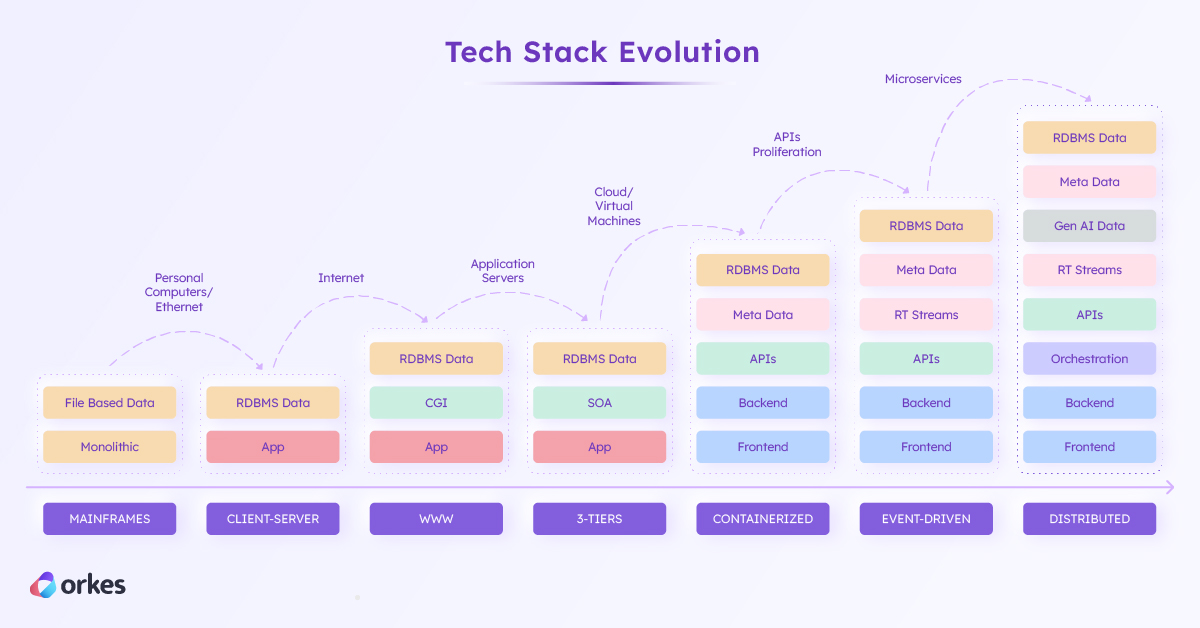
Looking ahead, software architecture will continue to evolve, shaped by advances in technology and the changing needs of businesses. For software architects and developers, it is more important than ever to adopt and adapt to better paradigms without losing sight of the core principles of good design. Ultimately, the best software architecture is one that best suits your business and product requirements.
Learn more about using the saga pattern in a distributed system.
Leveraging advanced workflow orchestration platforms like Orkes Conductor unlocks developer productivity in the world of distributed computing. Used widely in many mission-critical applications for microservice orchestration, event handling, and LLM chaining, Orkes Conductor empowers teams to build resilient, scalable systems with ease:
Conductor is an enterprise-grade orchestration platform for process automation, API and microservices orchestration, agentic workflows, and more. Check out the full set of features, try it yourself using our Developer Edition sandbox, or get a demo of Orkes Cloud, a fully managed and hosted Conductor service.