SOLUTIONS
Using Conductor Forks to run tasks in parallel - creating multiple images
Orkes Team
Developer Relations
Last updated: January 31, 2022
January 31, 2022
8 min read








Join thousands of developers building the future with Orkes.
In our previous post on image processing workflows, we built a Netflix Conductor workflow that took an image input, and then ran 2 tasks: The first task resizes and reformats the image, and the second task uploads the image to an AWS S3 bucket.
With today's varied screen sizes, and varied browser support, it is a common requirement that the image processing pipeline must create multiple images with different sizes and formats of each image.
To do this with a Conductor workflow, we'll utilize the Fork operation to create parallel processes to generate multiple versions of the same image. The FORK task creates multiple parallel processes, so each image will be created asynchronously - ensuring a fast and efficient process.
In this post, our workflow will create 2 versions of the same image - a jpg and webp.
NOTE: This demo is provided to explain the FORK task in Conductor, but is not the best workflow to generate multiple images. For that - please read the Image processing with dynamic workflows post.
In this demonstration, we'll be running Conductor locally. Once you have followed the steps for setting up a local Conductor instance, you'll be ready to go.
Since we are doing image processing, you'll also want to have ImageMagick installed on your machine.
The workflow, tasks and Java workers are all a part of the orkesworkers GitHub repository.
Let's start off by building a workflow that will create 2 different versions of the same image. To do this, we will use the FORK operation to split our workflow into 2 paths. This will allow us to create two workers and do the image processing in parallel.
The visualization of this workflow will be:
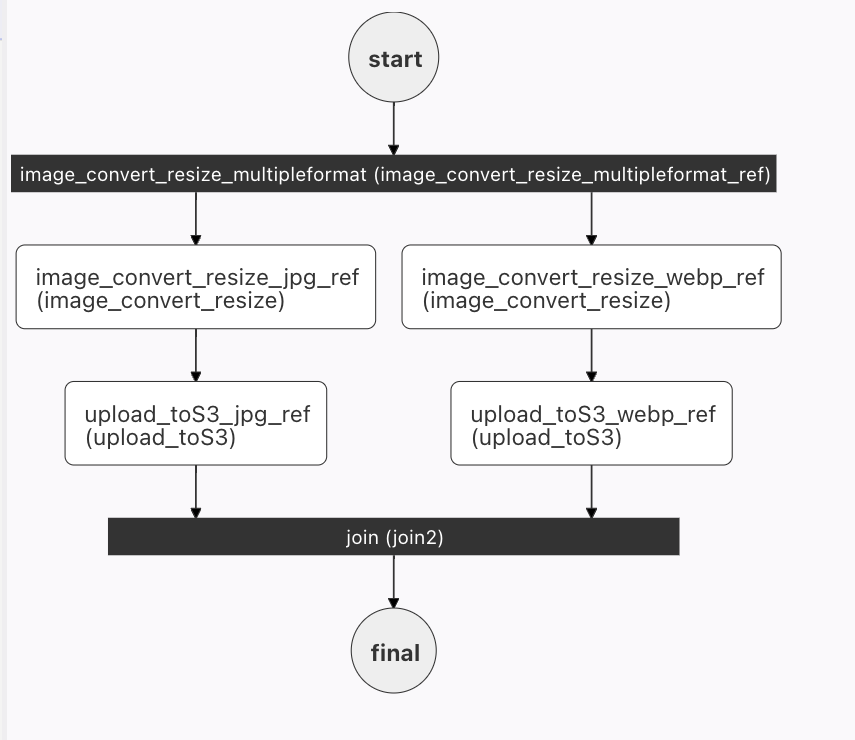
Our first task in this workflow is the fork - splitting the workflow. At the fork, we'll have 2 paths, one to create a jpg and the other to create a webp version of the image.
Let's look at the workflow JSON file (I have removed the fork tasks for readability - but we'll get there - I promise!):
{
"name": "image_convert_resize_multipleformat",
"description": "Image Processing Workflow",
"version": 1,
"tasks": [
{
"name": "image_convert_resize_multipleformat_fork",
"taskReferenceName": "image_convert_resize_multipleformat_ref",
"type": "FORK_JOIN",
"forkTasks":[
[
<task 1 workflow>
],
[
<task 2 workflow>
]
]
},
{
"name": "image_convert_resize_multipleformat_join",
"taskReferenceName": "image_convert_resize_multipleformat_join_ref",
"type": "JOIN",
"joinOn": [
"upload_toS3_jpg_ref",
"upload_toS3_webp_ref"
]
}
],
"outputParameters": {
"fileLocationJpg": "${upload_toS3_jpg_ref.output.fileLocation}",
"fileLocationWebp": "${upload_toS3_webp_ref.output.fileLocation}"
},
"schemaVersion": 2,
"restartable": true,
"workflowStatusListenerEnabled": true,
"ownerEmail": "devrel@orkes.io",
"timeoutPolicy": "ALERT_ONLY",
"timeoutSeconds": 0,
"variables": {},
"inputTemplate": {}
}
Like all workflows, we gave the workflow a name, description and version. After these terms, we begin defining the tasks in our workflow.
Our first task is the task image_convert_resize_multipleformat_fork. It's type is FORK_JOIN - and its job is to split the workflow into two flows that will run in parallel. (Of course, this example uses 2 parallel tracks - there is no reason there cannot be more than two!)
{
"name": "image_convert_resize_multipleformat_fork",
"taskReferenceName": "image_convert_resize_multipleformat_ref",
"type": "FORK_JOIN",
"forkTasks":[
[
<task 1 workflow>
],
[
<task 2 workflow>
]
]
}
The parallel workflows will run until they are re-connected by the JOIN task:
{
"name": "image_convert_resize_multipleformat_join",
"taskReferenceName": "image_convert_resize_multipleformat_join_ref",
"type": "JOIN",
"joinOn": ["upload_toS3_jpg_ref", "upload_toS3_webp_ref"]
}
When the 2 workflows have completed, the last task in each flow will fire that it is completed. In this case, the last task for the 2 flows is the upload to S3: upload_toS3_<imageFormat>_ref. When these 2 (or more) final tasks have completed, the workflow will rejoin. Upon rejoining, we've completed all the work to be done, so we can provide the output parameters:
"outputParameters": {
"fileLocationJpg": "${upload_toS3_jpg_ref.output.fileLocation}",
"fileLocationWebp": "${upload_toS3_webp_ref.output.fileLocation}"
},
This creates a JSON object with our 2 AWS S3 URLs where our new jpg and webp images are now hosted.
The JOIN and FORK tasks are System tasks, and therefore do not require an additional task definition- the workflow definition is sufficient.
In the workflow above, we omitted the workflow tasks. Let's look at the first workflow:
[
{
"name": "image_convert_resize",
"taskReferenceName": "image_convert_resize_jpg_ref",
"inputParameters": {
"fileLocation": "${workflow.input.fileLocation}",
"outputWidth": "${workflow.input.recipeParameters.outputSize.width}",
"outputHeight": "${workflow.input.recipeParameters.outputSize.height}",
"outputFormat": "jpg"
}
},
{
"name": "upload_toS3",
"taskReferenceName": "upload_toS3_jpg_ref",
"inputParameters": {
"fileLocation": "${image_convert_resize_jpg_ref.output.fileLocation}"
}
}
]
These two tasks should be familiar to those who read the first image processing post. They are very nearly the same - the only difference is the addition of _jpg_ to the taskReferenceName, and the "outputFormat" term) is now hardcoded to jpg.
In the first fork, we have 2 tasks: image_convert_resize and upload_toS3.
The image_convert_resize task reads in the file, width and height of the image from the workflow input. We hardcode in the "outputFormat" as jpg.
When the resizing task has completed, the upload_toS3 task takes the file created image_convert_resize_jpg_ref.output.fileLocation and uploads it to S3.
This fork is nearly identical to the first one. The only change is that every instance of jpg has been replaced with webp. This ensures that the 2nd task creates the webp version of the image.
[
{
"name": "image_convert_resize",
"taskReferenceName": "image_convert_resize_webp_ref",
"inputParameters": {
"fileLocation": "${workflow.input.fileLocation}",
"outputWidth": "${workflow.input.recipeParameters.outputSize.width}",
"outputHeight": "${workflow.input.recipeParameters.outputSize.height}",
"outputFormat": "webp"
}
},
{
"name": "upload_toS3",
"taskReferenceName": "upload_toS3_webp_ref",
"inputParameters": {
"fileLocation": "${image_convert_resize_webp_ref.output.fileLocation}"
}
}
]
Each of the forks end on the upload_toS3_<imageformat>_ref, which the JOIN then uses to know when all of the forks have completed.
The two tasks that must be defined are image_convert_resize and upload_toS3. Now, we begin to see the magic of microservice orchestration. If you have a local version of Conductor running, and you ran the first image processing tutorial, these two tasks are already defined and are running in your Conductor instance.
We'll just reuse the same tasks again! It's like landing on a big ladder in Snakes and Ladders - you can skip the next few steps, and rejoin us at Ready to Go.

If you have not defined these two tasks yet, here's the path to the task in GitHub: /data/task/image_convert_resize.json:
This task is described in our previous post.
{
"name": "image_convert_resize",
"retryCount": 3,
"timeoutSeconds": 30,
"pollTimeoutSeconds": 30,
"inputKeys": ["fileLocation", "outputFormat", "outputWidth", "outputHeight"],
"outputKeys": ["fileLocation"],
"timeoutPolicy": "TIME_OUT_WF",
"retryLogic": "FIXED",
"retryDelaySeconds": 60,
"responseTimeoutSeconds": 60,
"concurrentExecLimit": 100,
"rateLimitFrequencyInSeconds": 60,
"rateLimitPerFrequency": 50,
"ownerEmail": "devrel@orkes.io"
}
Here's how to add it to your local Conductor instance:
curl -X 'POST' \
'http://localhost:8080/api/metadata/taskdefs' \
-H 'accept: */*' \
-H 'Content-Type: application/json' \
-d '[
{"name":"image_convert_resize","retryCount":3,"timeoutSeconds":30,"pollTimeoutSeconds":30,"inputKeys":["fileLocation","outputFormat","outputWidth","outputHeight"],"outputKeys":["fileLocation"],"timeoutPolicy":"TIME_OUT_WF","retryLogic":"FIXED","retryDelaySeconds":60,"responseTimeoutSeconds":60,"concurrentExecLimit":100,"rateLimitFrequencyInSeconds":60,"rateLimitPerFrequency":50,"ownerEmail":"devrel@orkes.io"}
]'
This workflow is also in GitHub /data/task/upload_toS3.json, and described in our previous post:
{
"name": "upload_toS3_ref",
"retryCount": 3,
"timeoutSeconds": 30,
"pollTimeoutSeconds": 30,
"inputKeys": ["fileLocation"],
"outputKeys": ["s3Url"],
"timeoutPolicy": "TIME_OUT_WF",
"retryLogic": "FIXED",
"retryDelaySeconds": 30,
"responseTimeoutSeconds": 30,
"concurrentExecLimit": 100,
"rateLimitFrequencyInSeconds": 30,
"rateLimitPerFrequency": 50,
"ownerEmail": "devrel@orkes.io"
}
curl -X 'POST' \
'http://localhost:8080/api/metadata/taskdefs' \
-H 'accept: */*' \
-H 'Content-Type: application/json' \
-d '[
{"name":"upload_toS3_ref","retryCount":3,"timeoutSeconds":30,"pollTimeoutSeconds":30,"inputKeys":["fileLocation"],"outputKeys":["s3Url"],"timeoutPolicy":"TIME_OUT_WF","retryLogic":"FIXED","retryDelaySeconds":30,"responseTimeoutSeconds":30,"concurrentExecLimit":100,"rateLimitFrequencyInSeconds":30,"rateLimitPerFrequency":50,"ownerEmail":"devrel@orkes.io"}
]'
Our Java apps are in the orkesworkers GitHub repository, and can be started by running the OrkesWorkersApplication.java.
The OrkesWorkersApplication creates a list all of the workers that are available in the repository, and reports those to the conductor.server.url (defined in resources/application.properties as http://localhost:8000/api).
This will poll the Conductor server for any tasks for any of the workers that are running locally. When a task appears, Conductor will send it to the worker.
Now we are able to test our workflow with a simple curl command:
curl -X 'POST' \
'http://localhost:8080/api/workflow/image_convert_resize_multipleformat?priority=0' \
-H 'accept: text/plain' \
-H 'Content-Type: application/json' \
-d '{"fileLocation": "https://pbs.twimg.com/media/FJY7ud0XEAYVCS8?format=png&name=900x900",
"recipeParameters": {
"outputSize": {
"width": 300,
"height": 300
}
}
}'
The API response is a workflowId.
Connecting to http://localhost:5000/executrion/<workflowId> we'll see the processing, and on completion, we'll get the output:
{
"fileLocationJpg":"https://image-processing-sandbox.s3.amazonaws.com/d67ad5d9-31ef-4485-b30a-f16f2c1017e4.jpg"
"fileLocationWebp":"https://image-processing-sandbox.s3.amazonaws.com/d6447d9a-bb11-4b74-8e65-41099f9f0091.webp"
}
Here's the JPG version of the output:

In this post, we introduced the idea of a FORK - which splits the workflow into multiple parallel streams. This allows for several tasks to run simultaneously, and the results collected before continuing the workflow. In this case, we take an image (and resizing parameters), and use a fork to create the same image in two different formats.
The sample code, and sample workflows are all available on GitHub, so feel free to grab the code, and try it yourself!
In our next post, we will replace the parallel tasks with a subworkflow. Rather than reusing the tasks to re-create the same image processing workflow, we can simply use the workflow!