SOLUTIONS
Automating Serialization/Deserialization Tests with Orkes Conductor and LLMs

Harshil
Software Engineer
Last updated: May 29, 2025
May 29, 2025
5 min read








Join thousands of developers building the future with Orkes.
Writing unit tests for serialization and deserialization can be time-consuming and repetitive work. It’s monotonous and prone to human error, but still essential for ensuring that data is correctly sent across systems (API to server, application to application, SDK clients to server).
Unlike humans, software systems don’t get tired, bored, or distracted, even if faced with such mind-numbing work of writing serialization and deserialization (SerDe) tests.
Enter Orkes Conductor, a workflow orchestration platform. Combined with large language models (LLMs), Conductor transformed a week-long grind into a streamlined automation pipeline, cutting the testing time by over half.
In this post, we’ll walk through what SerDe tests are, why they matter, how we automated their creation using orchestration, and what made Orkes Conductor the ideal orchestration tool for the job.
Serialization refers to the conversion of a data object from its current state into a format that can be stored in a database or transmitted through a network. For example, a Python object into JSON, or a Java object into a stream of bytes.
Deserialization is the exact opposite of serialization: it refers to the process of reconstructing the data object from its serialized format so that it can be used again. For example, from JSON back into a Python object so that it can be used in a function.
Serialization and deserialization are key processes for transmitting data across distributed systems in a standardized format while maintaining usability.
Serialization and deserialization tests are critical for data integrity. They ensure that your data objects can:
Neglecting these tests can introduce subtle, high-impact bugs, especially in systems where APIs evolve or where SDKs are maintained separately from backend logic.
Yet writing these tests is typically:
That’s exactly what our engineering team was facing at Orkes: dozens of nearly identical tests with minor variations. Instead of slogging through them manually, we built an automated solution using Orkes Conductor.
In our case at Orkes, we needed to create tests to validate the mappings between SDK POJOs and server-side POJOs to ensure that data is transmitted correctly.
Accurate serialization and deserialization are crucial for the SDK's functionality, as they ensure that workflows and tasks are correctly interpreted by the Conductor server. By including comprehensive tests, developers can confidently make changes to the SDK without introducing regressions in data handling.
Using an orchestration tool like Orkes Conductor, we can automate repetitive actions across multiple services while ensuring that intermittent failures are remediated through retries and state persistence.
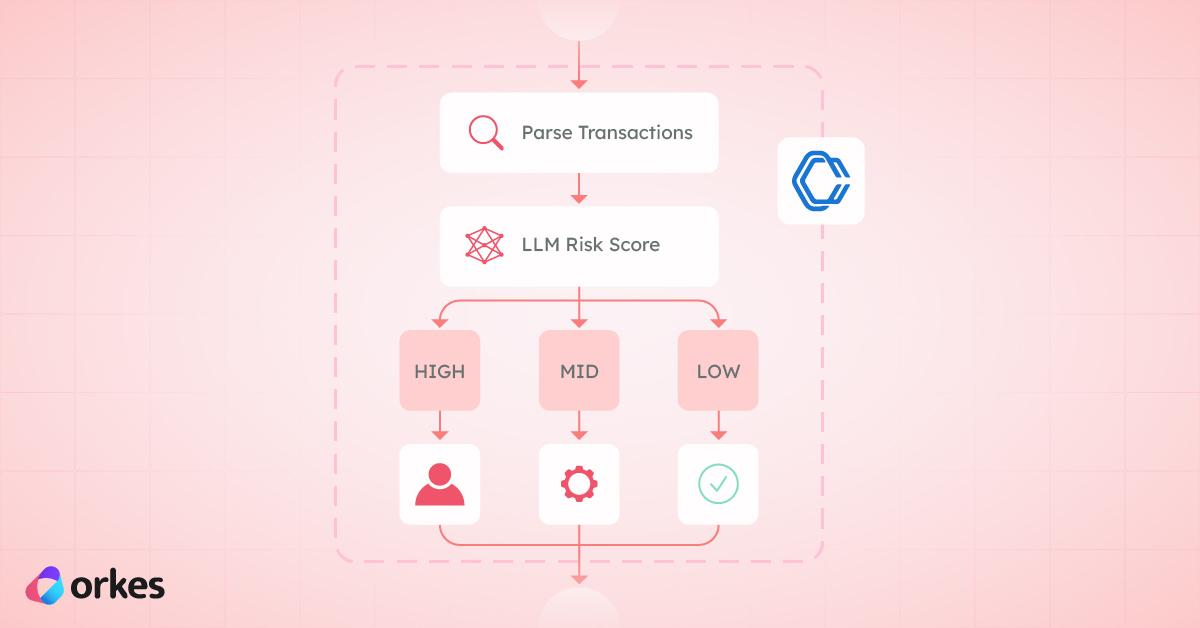
Here’s the high-level breakdown of the automated process:
Let’s explore how Conductor’s enterprise functionalities enable seamless automation at each step.
{
"templates" : {
"IndexedDoc" : {
"content" : {
"score" : 123.456,
"metadata" : {
"sample_key" : "sample_value"
},
"docId" : "sample_docId",
"text" : "sample_text",
"parentDocId" : "sample_parentDocId"
},
"dependencies" : [ ]
},
// rest of the JSON template
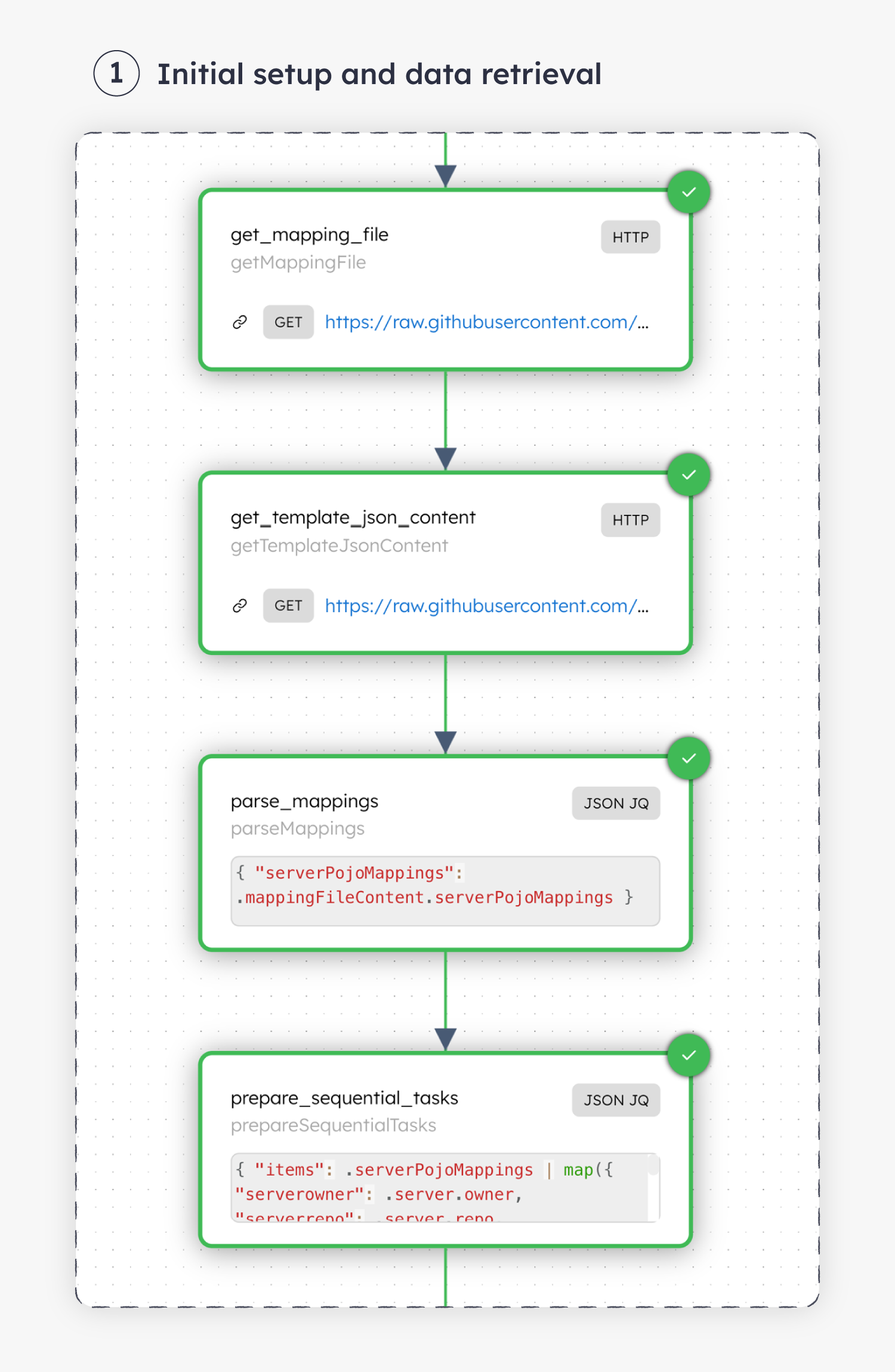
Using built-in system tasks like HTTP Task and JSON JQ Transform Task, these steps can be quickly assembled without needing to code everything from scratch.
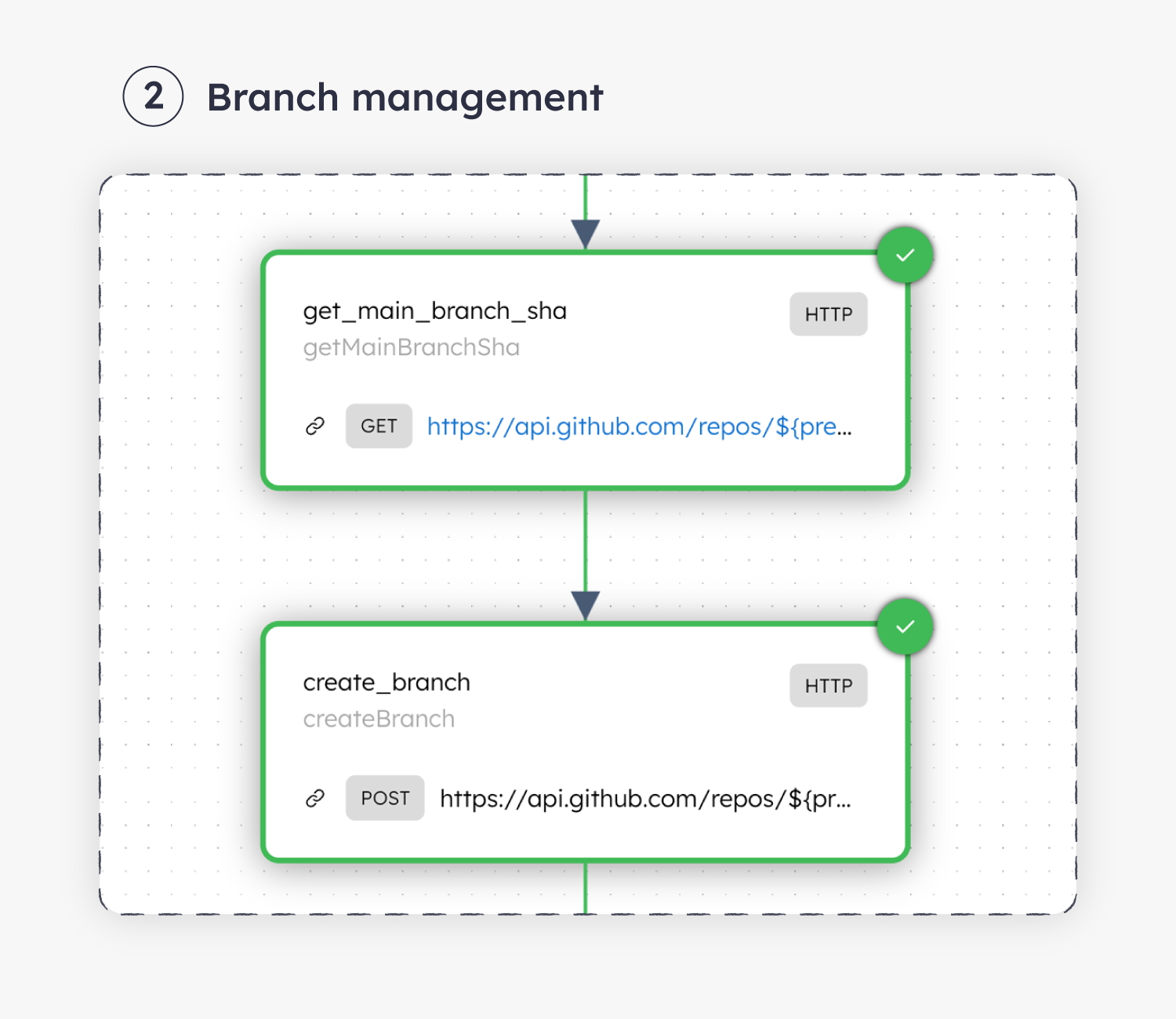
Using dynamic references like “${variable}” in the HTTP Task’s URI https://api.github.com/repos/${previousTask.output.owner}/${previousTask.output.repo}/git/refs/heads/${workflow.input.sdkbranch}, the workflow is repeatable across multiple execution runs. Going beyond, the workflow becomes reusable and can be embedded in other workflows as well.

Now we arrive at the heart of the workflow. For each server-SDK POJO mapping, the workflow will:
The suite of pre-built LLM tasks like LLM Text Complete facilitates rapid assembly of AI-powered tasks using any LLM provider. Conductor also supports prompt management, so you can create, test, and refine your prompts. Here is a snippet of an initial prompt to generate the test code:
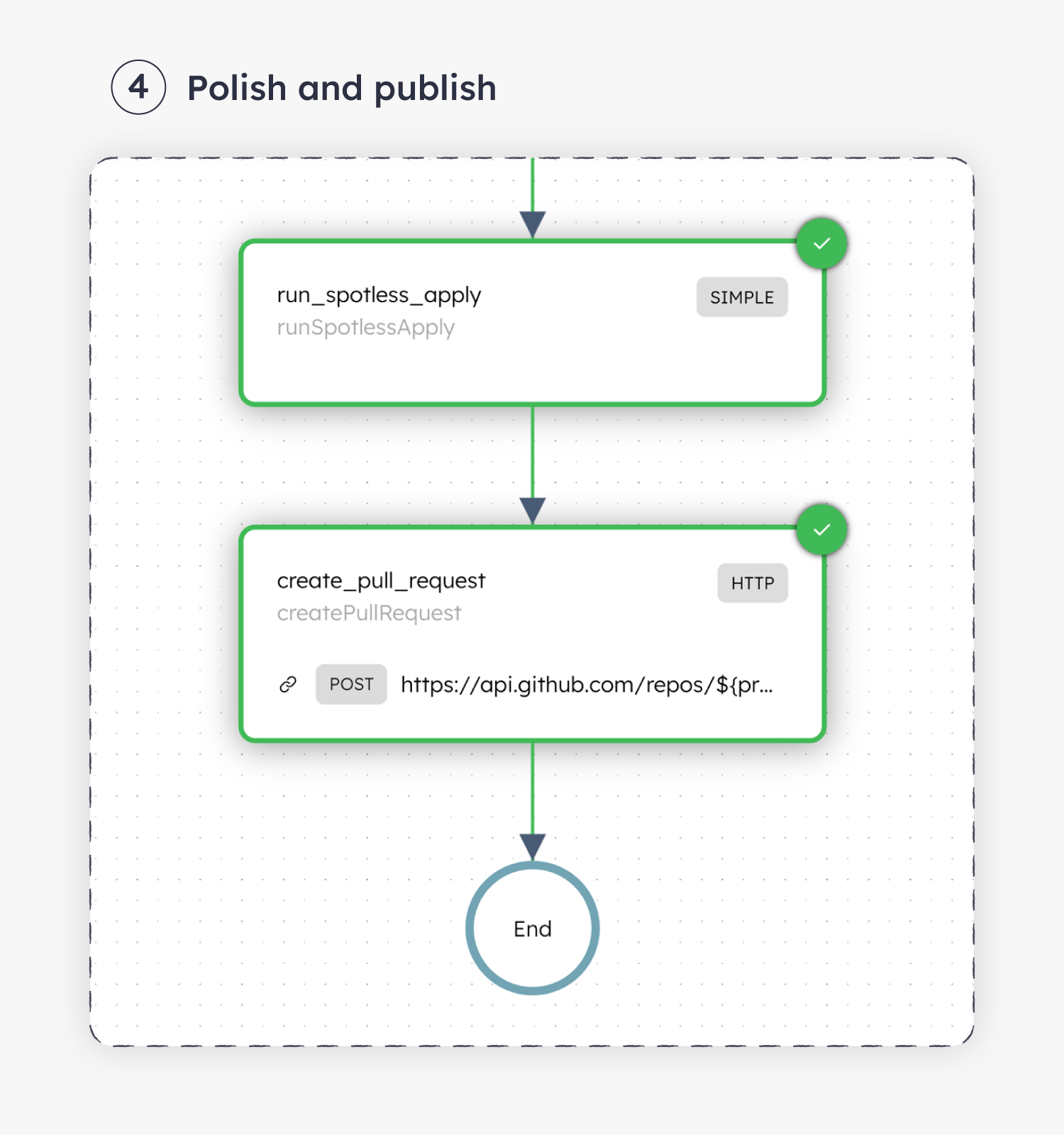
With all the test code generated, it’s time to wrap up:
Conductor tracks the data flow of every single task for each workflow run, making it easy to audit what has happened. Here is the execution trace of an example execution:
{
"ownerApp": "user@example.com",
"createTime": 1744977613276,
"updateTime": 1744978814626,
"createdBy": "user@example.com",
"status": "COMPLETED",
"endTime": 1744978814621,
"workflowId": "af4f073b-1c4c-11f0-8645-4e34a87470b0",
"tasks": [
{
"taskType": "HTTP",
"status": "COMPLETED",
"inputData": {
"asyncComplete": false,
"http_request": {
"headers": {
"Authorization": "token \${workflow.secrets.githubToken}",
"Accept": "application/json"
},
"method": "GET",
"uri": "https://raw.githubusercontent.com/orkes-io/sdk-codegen/base-code/conductor-java-sdk/SdkServerpojoMappings.json"
},
},
"referenceTaskName": "getMappingFile",
"retryCount": 0,
"seq": 1,
"pollCount": 1,
"taskDefName": "get_mapping_file",
"scheduledTime": 1744977613280,
"startTime": 1744977613299,
"endTime": 1744977613321,
"updateTime": 1744977613299,
"startDelayInSeconds": 0,
"retried": false,
"executed": true,
"workflowInstanceId": "af4f073b-1c4c-11f0-8645-4e34a87470b0",
"workflowType": "SDK_POJO_ser_deser_test",
"taskId": "af4fa37c-1c4c-11f0-8645-4e34a87470b0",
"callbackAfterSeconds": 0,
"workerId": "orkes-workers-deployment-6c5b9f55dc-5xknz",
"outputData": {
"response": {
...
Orchestration at scale
Conductor is built for chaining together complex, fault-tolerant workflows. This automation pipeline included over a dozen steps, with multiple dependencies across GitHub, OpenAI, and other services — exactly what Conductor was designed to handle.
LLM-ready
Not every task is rigid. For creative, generative work like cleaning up Java classes or writing test code, LLMs excel even when traditional automation breaks down. Conductor made it easy to drop in LLM-powered steps wherever flexible automation was required.
Reusable components
Once we built workers for custom tasks like applying Spotless auto-formatting and generating JSON templates, they became modular, reusable components. Now, creating a new workflow for a different use is just a matter of assembling these pieces together.
Developer-friendly
With REST APIs, SDKs, and a powerful UI, Conductor meets you where you are. Whether you need full developer tooling to build integrated workflows with your systems or visual dashboards to get complete visibility into the pipeline’s execution, Conductor’s product suite makes it seamless.
The original estimate for manually writing SerDe tests for this task was more than 5 days. Using Conductor and LLMs? Just 2.5 days to build and test the workflow itself. Now that the automated system exists, regenerating or extending the tests takes less than an hour.
More than just saving time, Orkes Conductor reframed how to think about developer productivity. Using Orkes Conductor with LLMs lets you:
The next time you need to ask yourself: “Can I orchestrate this instead?”
Because chances are, with Orkes Conductor, the answer is yes. Take a stab at automating repetitive work using our free Developer Edition.