LLM Text Complete
The LLM Text Complete task is used to generate a natural language response based on the provided context.
An LLM Text Complete task utilizes a large language model (LLM) to generate text predictions based on input context. The task configuration involves selecting an LLM provider, specifying the model, and defining the prompt and its variables. The fine-tuning parameters control the output, ensuring the generated text aligns with the desired randomness and length.
- Integrate the required AI model with Orkes Conductor.
- Create the required AI prompt for the task.
Task parameters
Configure these parameters for the LLM Text Complete task.
| Parameter | Description | Required/ Optional |
|---|---|---|
| inputParameters.llmProvider | The integration name of the LLM provider integrated with your Conductor cluster. Note: If you haven’t configured your AI/LLM provider on your Orkes Conductor cluster, go to the Integrations tab and configure your required provider. | Required. |
| inputParameters.model | The available language models within the selected LLM provider. For example, If your LLM provider is Azure Open AI and you’ve configured text-davinci-003 as the language model, you can select it here. | Required. |
| inputParameters.promptName | The AI prompt created in Orkes Conductor. Note: If you haven’t created an AI prompt for your language model, refer to the documentation on creating AI Prompts in Orkes Conductor. | Required. |
| inputParameters.promptVariables | For prompts that involve variables, provide the input to these variables as key-value pairs, where the key is the variable name defined in the prompt template. Values can be string, number, boolean, null, or object/array. For example: "promptVariables": {"country": "${workflow.input.country}"}. | Optional. |
| inputParameters.temperature | A parameter to control the randomness of the model’s output. Higher temperatures, such as 1.0, make the output more random and creative. A lower value makes the output more deterministic and focused. Tip: If you're using a text blurb as input and want to categorize it based on its content type, opt for a lower temperature setting. Conversely, if you're providing text inputs and intend to generate content like emails or blogs, it's advisable to use a higher temperature setting. | Optional. |
| inputParameters.stopWords | List of words to be omitted during text generation. Supports string and object/array. In LLM, stop words may be filtered out or given less importance during the text generation process to ensure that the generated text is coherent and contextually relevant. | Optional. |
| inputParameters.topP | Another parameter to control the randomness of the model’s output. This parameter defines a probability threshold and then chooses tokens whose cumulative probability exceeds this threshold. Example: Imagine you want to complete the sentence: “She walked into the room and saw a __.” The top few words the LLM model would consider based on the highest probabilities would be:
| Optional. |
| inputParameters.maxTokens | The maximum number of tokens to be generated by the LLM and returned as part of the result. A token is approximately four characters. | Optional. |
The following are generic configuration parameters that can be applied to the task and are not specific to the LLM Text Complete task.
Caching parameters
You can cache the task outputs using the following parameters. Refer to Caching Task Outputs for a full guide.
| Parameter | Description | Required/ Optional |
|---|---|---|
| cacheConfig.ttlInSecond | The time to live in seconds, which is the duration for the output to be cached. | Required if using cacheConfig. |
| cacheConfig.key | The cache key is a unique identifier for the cached output and must be constructed exclusively from the task’s input parameters. It can be a string concatenation that contains the task’s input keys, such as ${uri}-${method} or re_${uri}_${method}. | Required if using cacheConfig. |
Other generic parameters
Here are other parameters for configuring the task behavior.
| Parameter | Description | Required/ Optional |
|---|---|---|
| optional | Whether the task is optional. If set to true, any task failure is ignored, and the workflow continues with the task status updated to COMPLETED_WITH_ERRORS. However, the task must reach a terminal state. If the task remains incomplete, the workflow waits until it reaches a terminal state before proceeding. | Optional. |
Task configuration
This is the task configuration for an LLM Text Complete task.
{
"name": "llm_text_complete",
"taskReferenceName": "llm_text_complete_ref",
"inputParameters": {
"llmProvider": "openAI",
"model": "chatgpt-4o-latest",
"promptName": "translate",
"temperature": 1,
"topP": 0.8,
"maxTokens": 150,
"stopWords": [
"a",
"and",
"the"
]
},
"type": "LLM_TEXT_COMPLETE"
}
Task output
The LLM Text Complete task will return the following parameters.
| Parameter | Description |
|---|---|
| result | The completed text by the LLM. |
| finishReason | Indicates why the text generation stopped. Common values include STOP when the model completes naturally. |
| tokenUsed | Total number of tokens consumed for the request, including both prompt and completion tokens. |
| promptTokens | Number of tokens used to process the prompt. |
| completionTokens | Number of tokens generated by the model in the output text returned by the task. |
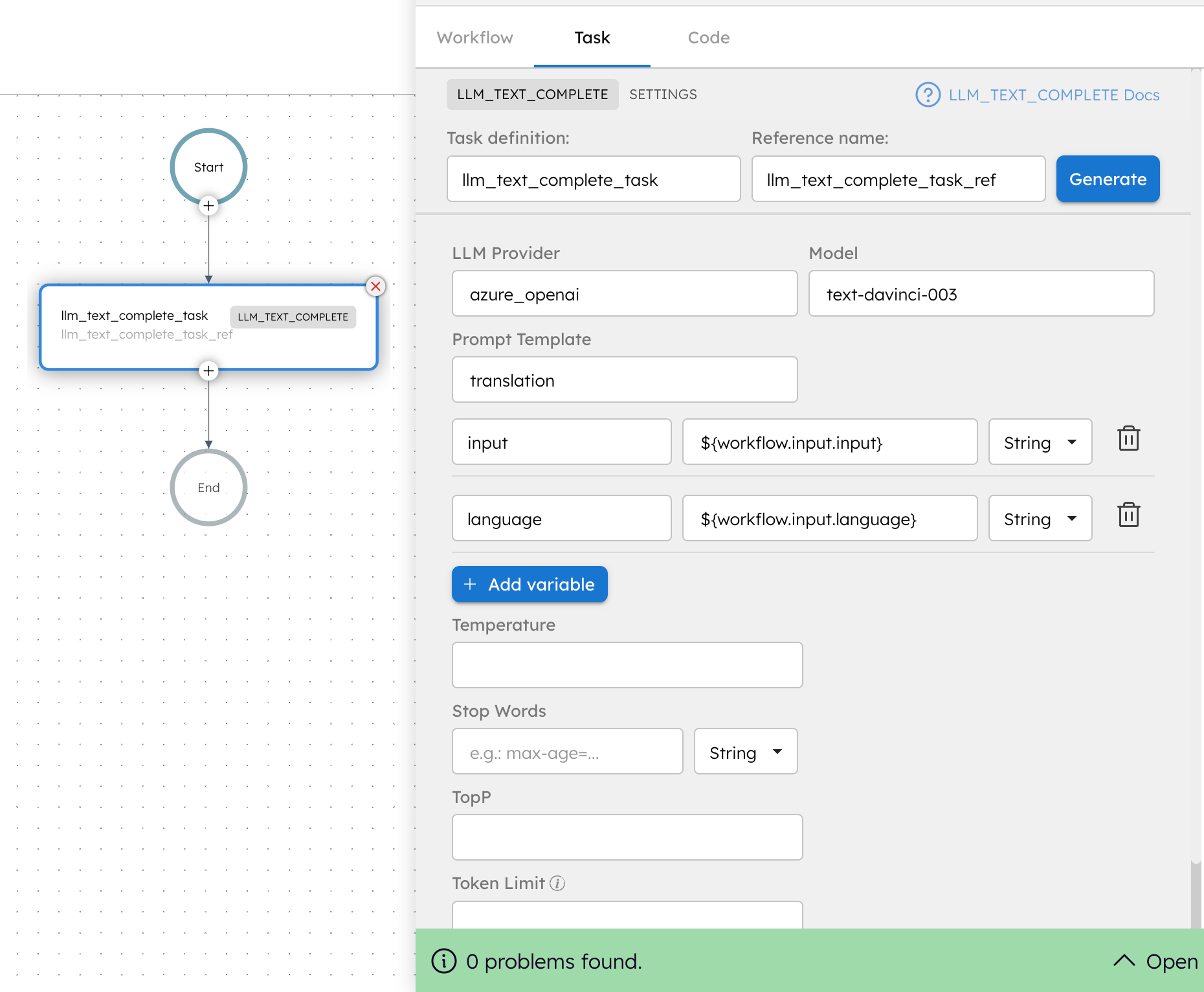
Adding an LLM Text Complete task in UI
To add an LLM Text Complete task:
- In your workflow, select the (+) icon and add an LLM Text Complete task.
- In Provider and Model, select the LLM provider, and Model.
- In Prompt and Variables, select the Prompt Name.
- (Optional) Select +Add variable to provide the variable path if your prompt template includes variables.
- (Optional) In Fine Tuning, set the parameters Temperature, TopP, Token Limit, Stop words, and Stop word type.
Examples
Here are some examples for using the LLM Text Complete task.
Using an LLM Text Complete task in a workflow
See an example of building an AI-powered translator using the LLM Text Complete task.