AGENTIC ENGINEERING
The Secret to Stronger Agentic Workflows Is Breaking Prompts into Pieces

Maria Shimkovska
Content Engineer
Last updated: August 26, 2025
August 26, 2025
11 min read








Join thousands of developers building the future with Orkes.

Back in college, I really struggled with computer science. Even simple things like loops and algorithms felt overwhelming because I was always trying to solve the whole problem at once.
The game-changer was when my professor introduced divide and conquer. Suddenly I realized you don’t solve one massive problem at once. You break it down into smaller pieces, tackle each, then stitch them together.
It’s the same principle with prompts, too. Don’t throw one impossible question at an AI. Break it down, let each piece be handled well, and then combine the results.
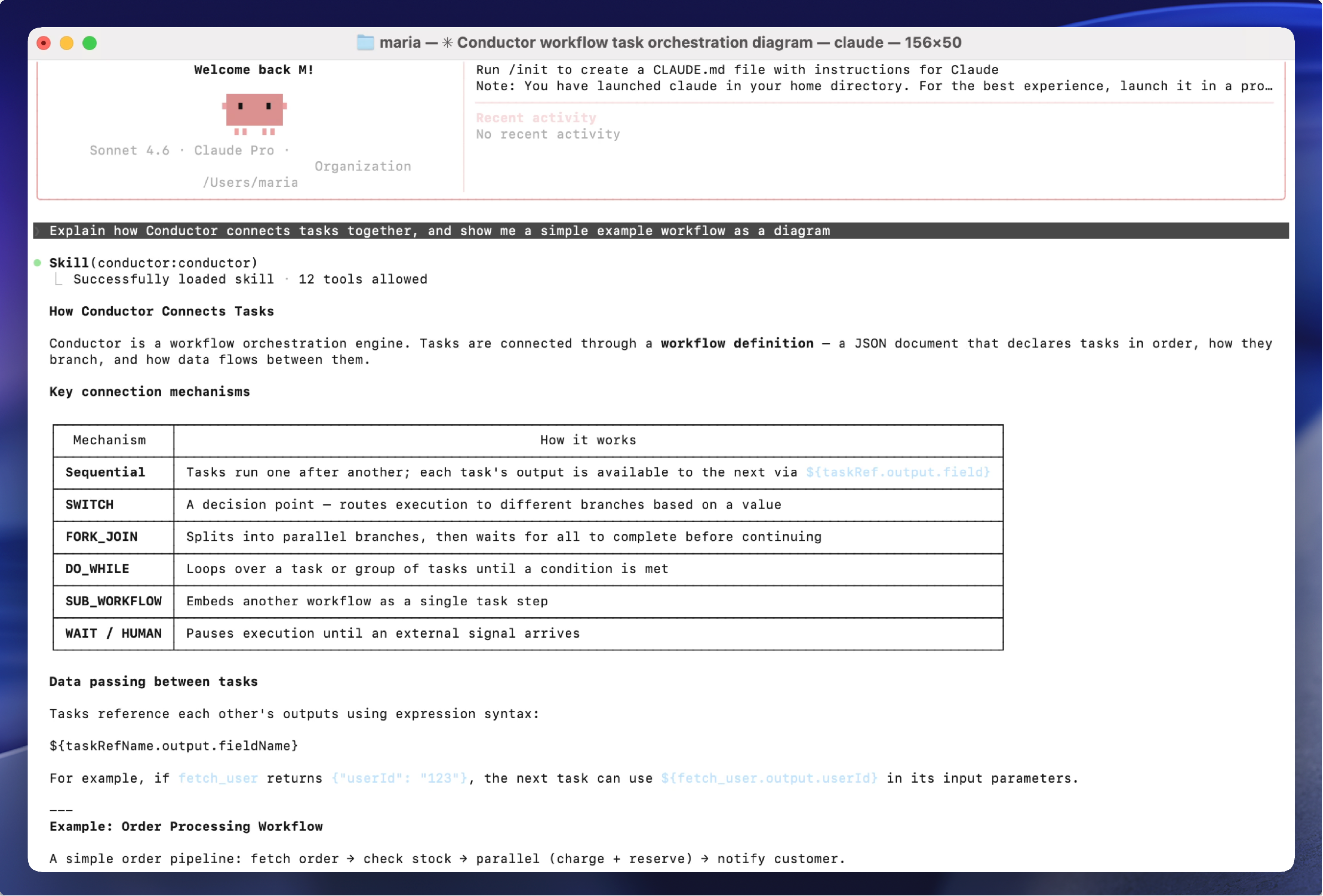
Divide and conquer is an algorithm strategy but it’s also a way of successfully tackling other problems too. And Orkes Conductor makes it super easy to implement exactly that stategy with your prompts.
Instead of wrestling with one giant, messy workflow or prompt, you define smaller tasks or prompts (payments, inventory, notifications) and Conductor orchestrates them into one cohesive ecosystem.
One of the easiest mistakes to make with AI is overprompting—trying to cram every single requirement into one giant instruction. It feels like you’re being efficient, but usually it just leads to messy, fragile results that are hard to fix.
So instead, break your prompts into smaller, more eliable steps.
Think about it: writing one “perfect” prompt that handles every bug, edge case, and logic detail is way too much pressure. On top of that, you’d still need to figure out how to pass new info into it as your workflow unfolds. It’s just cleaner to split things up into focused prompts that each handle one task really well.
When you ask a single prompt to do everything, you usually end up with weird, unpredictable answers.
One big prompt can work fine if you’re chatting with a simple model and just want one-off results. But once you’re building more complex agent workflows, you need a bit more strategy—and that’s where smaller, sharper prompts come into play.
When writing prompts for a singular LLM, you can usually rely on one prompt. An LLM is like a super smart search engine that takes your input, works its magic behind the scenes, and gives you one output. It's pretty much what the basic version of ChatGPT is.
For example:
That works fine when the task is simple, one-dimensional, and doesn’t require much structure. But for enterprise, production use cases you'd use agentic workflows and for that you need a more evolved approach.
Agentic workflows aim for bigger goals. They need prompts that are modular and specialized, with each step contributing to the final outcome.
Instead of trying to craft the one “perfect” mega-prompt (which will almost always break down at edge cases), you split the problem into smaller prompts that can be orchestrated and reused.
For example:
And within agentic workflows, there are two core prompting strategies:
When a problem is too big for one prompt, you can split it into a chain of smaller prompts where each one builds on the output of the last.
You can think of this chain of prompts as an assembly line:
Each prompt is dependent, so you can't run the third one without the second, and you can't run the second without the third. And if you are thinking to yourself, "Oh, but dependencies can be really bad," just remember that this is not necessarily good or bad. Just how the problem is. If you make coffee for instance, you also have steps that depend on the outcome of the previous one, like grinding the beans, pouring the water over the beans, and drinking the coffee.
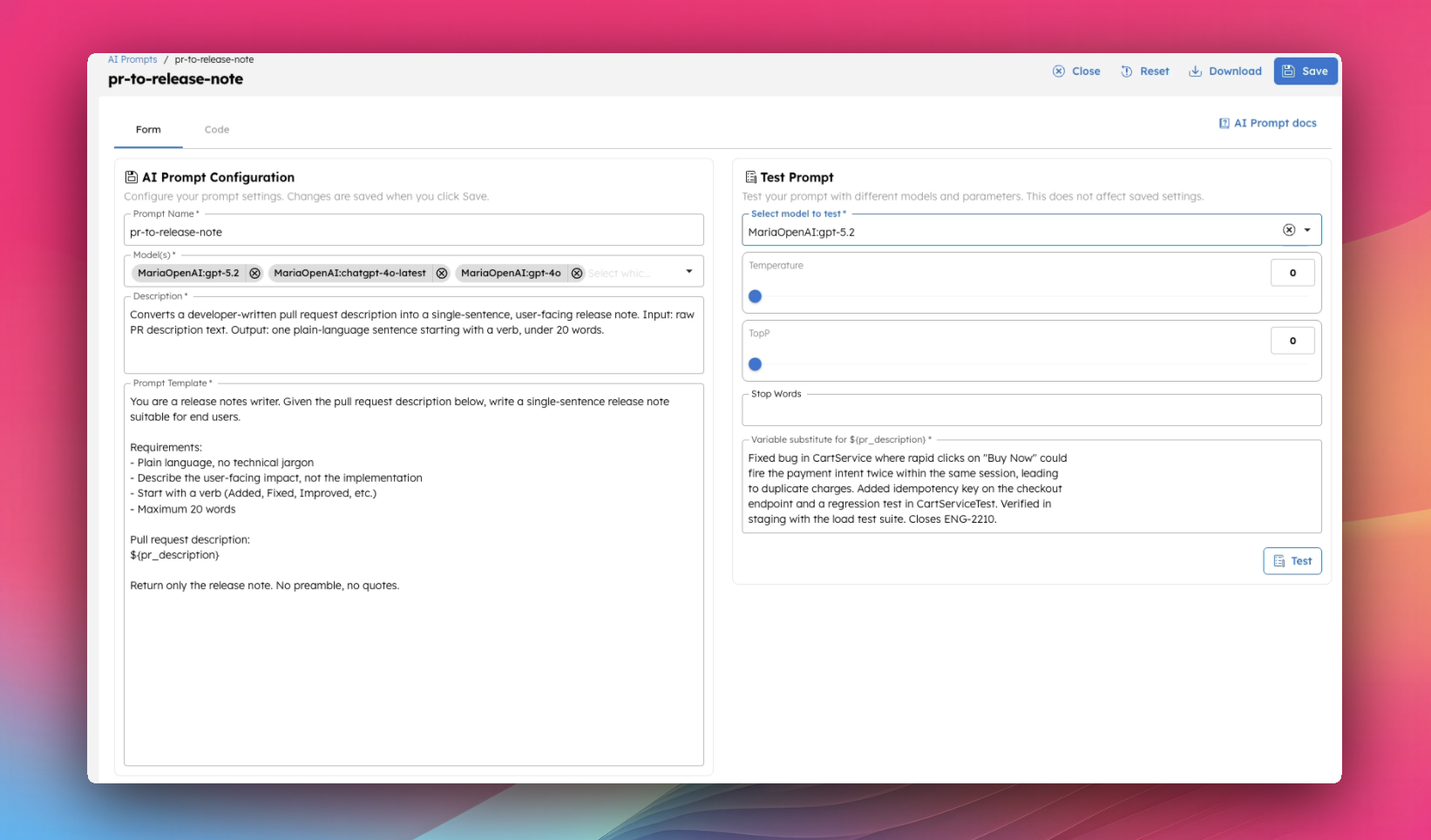
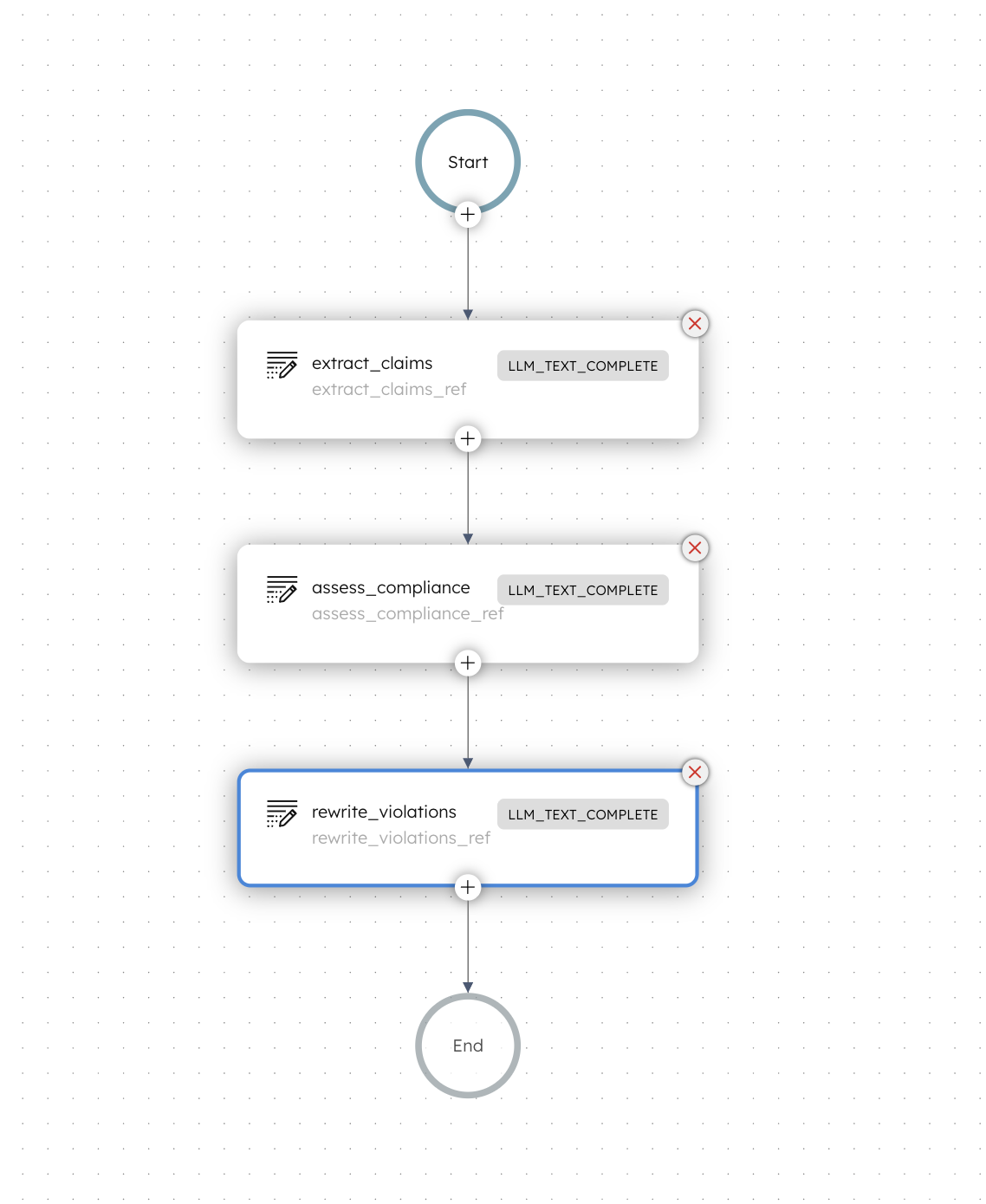
For this example, I am using a chain of 3 prompts built using the LLM_TEXT_COMPLETE task in Orkes Conductor.
Chain example: extracting claims → checking rules → rewriting violations.
Example of what the email can be: Our new investment fund guarantees a 15% return in the first year. Join thousands of satisfied clients who are already profiting.
That then will trigger the workflow however you choose to implement it on your frontend.
Below are examples of what the inputs and outputs of each prompt would look like:
List all financial claims in this email. ${input}
Return only the claims in your output, in JSON.
In this format:
{
"financial_claims": [
{
"claim": "a claim"
},
{
"claim": "a claim"
},
{
"claim": "a claim"
},
...
]
}
and prettify it.
{
"financial_claims": [
{
"claim": "guarantees a 15% return in the first year"
},
{
"claim": "thousands of satisfied clients who are already profiting"
}
]
}For each claim from ${extract_claims}, check compliance against rule ${rule_123}.Let's evaluate each claim against the specified rules: 1. Claim: "guarantees a 15% return in the first year" Compliance: This claim does not comply with the rule "No Guarantees." It explicitly states a guaranteed return, which is prohibited. 2. Claim: "thousands of satisfied clients who are already profiting" Compliance: This claim does not comply with the rule "No Unverifiable Mass Adoption." It implies widespread usage and satisfaction without providing verifiable evidence or credible support to back up the assertion. In summary, both claims violate the specified rules.
Take the flagged claims from ${access_compliance} and rewrite the initial email, ${email}, to remain persuasive but compliant. Only include the body of the email. Don't add anything else like subject or best regards.Discover the potential of our new investment fund, designed to aim for attractive returns in the first year. Join a growing community of clients who are experiencing positive results and taking steps towards financial growth.
Now the final output is a compliant email draft, and you can trace exactly what was extracted, what was flagged, and how it was rewritten.
If we tried to do this with one giant prompt, it might look like this:
You are a compliance assistant. Given the following marketing email, do three things:
1. Extract all financial claims from ${input}.
2. Check each claim against ${rule_123}.
3. Rewrite any non-compliant claims to remain persuasive but compliant.
Return the final compliant email body, and also include a list of what was flagged and why.Extracted Financial Claims: "Our new investment fund guarantees a 15% return in the first year." "Join thousands of satisfied clients who are already profiting." Compliance Check: Claim: "Our new investment fund guarantees a 15% return in the first year." Compliance Status: Non-compliant. This claim implies guaranteed returns, which is against the rule "No Guarantees: You may not state or imply guaranteed returns, profits, or risk-free outcomes." Claim: "Join thousands of satisfied clients who are already profiting." Compliance Status: Non-compliant. This claim implies mass adoption and user satisfaction without credible evidence, violating the rule "No Unverifiable Mass Adoption." Revised Email Body: Subject: Discover Our New Investment Fund! Dear [Recipient's Name], We are excited to introduce our new investment fund, designed with the potential for significant returns. While past performance is not indicative of future results, many clients have expressed satisfaction with their investment experiences. Join our community of investors and explore how our fund can align with your financial goals. Contact us today to learn more about the opportunities available. Best regards, [Your Name] [Your Company] Flagged Claims and Reasons: "Our new investment fund guarantees a 15% return in the first year." Reason: Implies guaranteed returns, which is prohibited. "Join thousands of satisfied clients who are already profiting." Reason: Suggests widespread usage and satisfaction without verifiable evidence. This revised email body maintains a persuasive tone while adhering to compliance regulations.
Notice how this one-shot prompt tries to juggle extraction, compliance checks, and rewriting all at once.
The downsides:
That’s why chaining works better: each step is focused, testable, and replaceable.
And sometimes the problem isn't sequential, but branching. So, instead of needing one prompt's output to feed into the next, you want to run multiple prompts side by side.
Why side by side you may ask?
Well, because if those prompts don't depend on each other's outcomes to start, then there is no need to wait on one to begin the next. It is way more efficient to run them at the same time and wait for them all to finish and aggregate the results. occasionally, you don't even need to wait on all to finish in order to continue a workflow.
You can also think of a team of specilists, if you want to aggregate results. Each speciliast works independently of another one on the same input, but they each have a different task, and at the end yo combine their outputs.
This is useful when:
Parallel example: Suppose we want to generate multiple compliant rewrites of the same email so the marketing team has options to choose from.
Instead of chaining, we run three independent rewrite prompts in parallel.
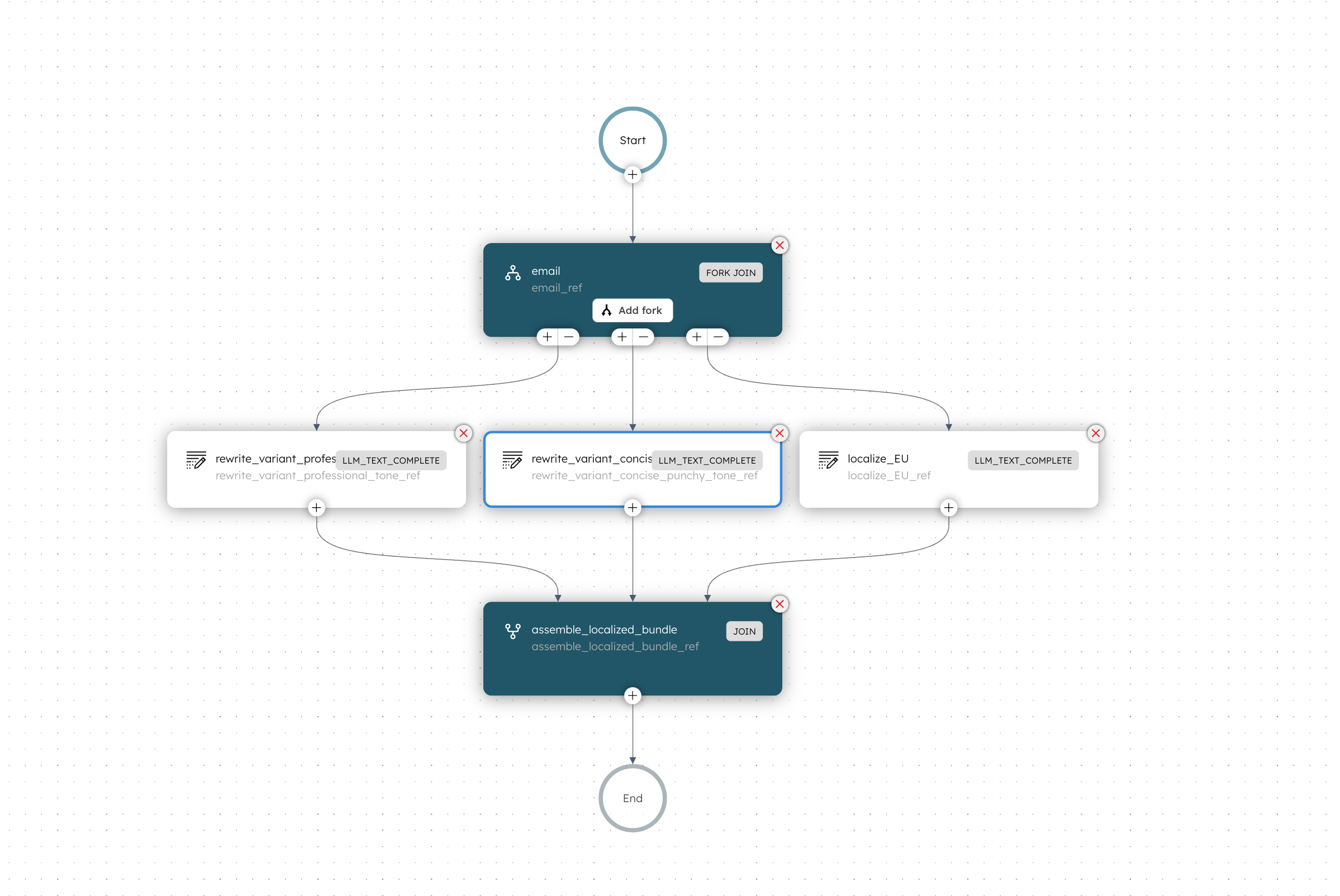
Rewrite this ${email} in a persuasive but compliant way. Focus on **professional** tone.Our new investment fund offers the potential for a 15% return in the first year. Join a community of satisfied clients who are already experiencing the benefits of our approach. Consider investing today to explore the opportunities that await you.
Rewrite this ${email} in a persuasive but compliant way. Focus on a **friendly** tone.Discover the opportunity of a lifetime with our new investment fund, which offers an attractive 15% return in the first year! Join the community of happy clients who are already enjoying the benefits of their investments. We’re excited to help you embark on your financial journey!
Rewrite this ${email} in a persuasive but compliant way. Focus on a **concise, punchy** style.Discover our new investment fund, offering a guaranteed 15% return in the first year. Join thousands of satisfied clients and start benefiting today!
This makes agentic workflows stronger, more reliable, and easier to debug than trying to jam everything into one giant prompt.
You can use the Developer Edition of Orkes Conductor to start building your agentic workflows:
LLM_TEXT_COMPLETE, and they will ask for a model and a prompt. Kind of like mixing and matching. You can define multiple models once and then test which models work best for your prompt if you wish. Go wild.