PRODUCT
Task-Level Resilience in Orkes Conductor: Timeouts and Retries in Action

Karl Goeltner
Software Engineer
Last updated: May 12, 2025
May 12, 2025
5 min read








Join thousands of developers building the future with Orkes.
In distributed systems, individual task failure is not a matter of if, but when. APIs go down, services stall, and workers disappear. What matters is how your system responds. With Orkes Conductor, you don’t just handle these failures—you design for them.
Conductor provides fine-grained control over how each task behaves under failure. With customizable timeouts and retries, you can recover from transient issues without human intervention, ensure critical steps don’t hang indefinitely, and build workflows that fail gracefully instead of catastrophically.
In this blog, we’ll explore three core capabilities that enable resilient task execution in Orkes Conductor:
One of the most common failure scenarios is a transient error—momentary service unavailability, network hiccups, or throttling by an external API. Conductor lets you retry failed tasks automatically, using configurable backoff strategies to avoid overwhelming downstream services.
Retry parameters
| Parameter | Description |
|---|---|
retryCount | The maximum number of retry attempts. Default is 3. |
retryLogic | Retry strategy for the tasks. Supports:
|
retryDelaySeconds | The delay between retries. This combines with the backoff logic to calculate the actual wait time. Note: The actual duration depends on the retry policy set in retryLogic. |
backoffScaleFactor | Multiplier applied to retryDelaySeconds to adjust how fast delays increase. Default is 1. |
Imagine your email provider fails intermittently. The first request sends a 500 error, but the second or third might succeed. This is a perfect scenario for retries.
from conductor.client.configuration.configuration import Configuration
from conductor.client.http.models import TaskDef
from conductor.client.orkes_clients import OrkesClients
def main():
api_config = Configuration()
clients = OrkesClients(configuration=api_config)
metadata_client = clients.get_metadata_client()
task_def = TaskDef()
task_def.name = 'send_email_task'
task_def.description = 'Send an email with retry on intermittent failures'
task_def.retry_count = 3
task_def.retry_logic = 'EXPONENTIAL_BACKOFF'
task_def.retry_delay_seconds = 2
task_def.backoff_scale_factor = 2
metadata_client.register_task_def(task_def=task_def)
print(f'Registered the task -- view at {api_config.ui_host}/taskDef/{task_def.name}')
if __name__ == '__main__':
main()
Check out the full sample code for the send email task.
Here, if the email task fails, it will automatically retry up to 3 times with increasing delays—2s, 4s, and 8s—allowing time for the service to recover between attempts.
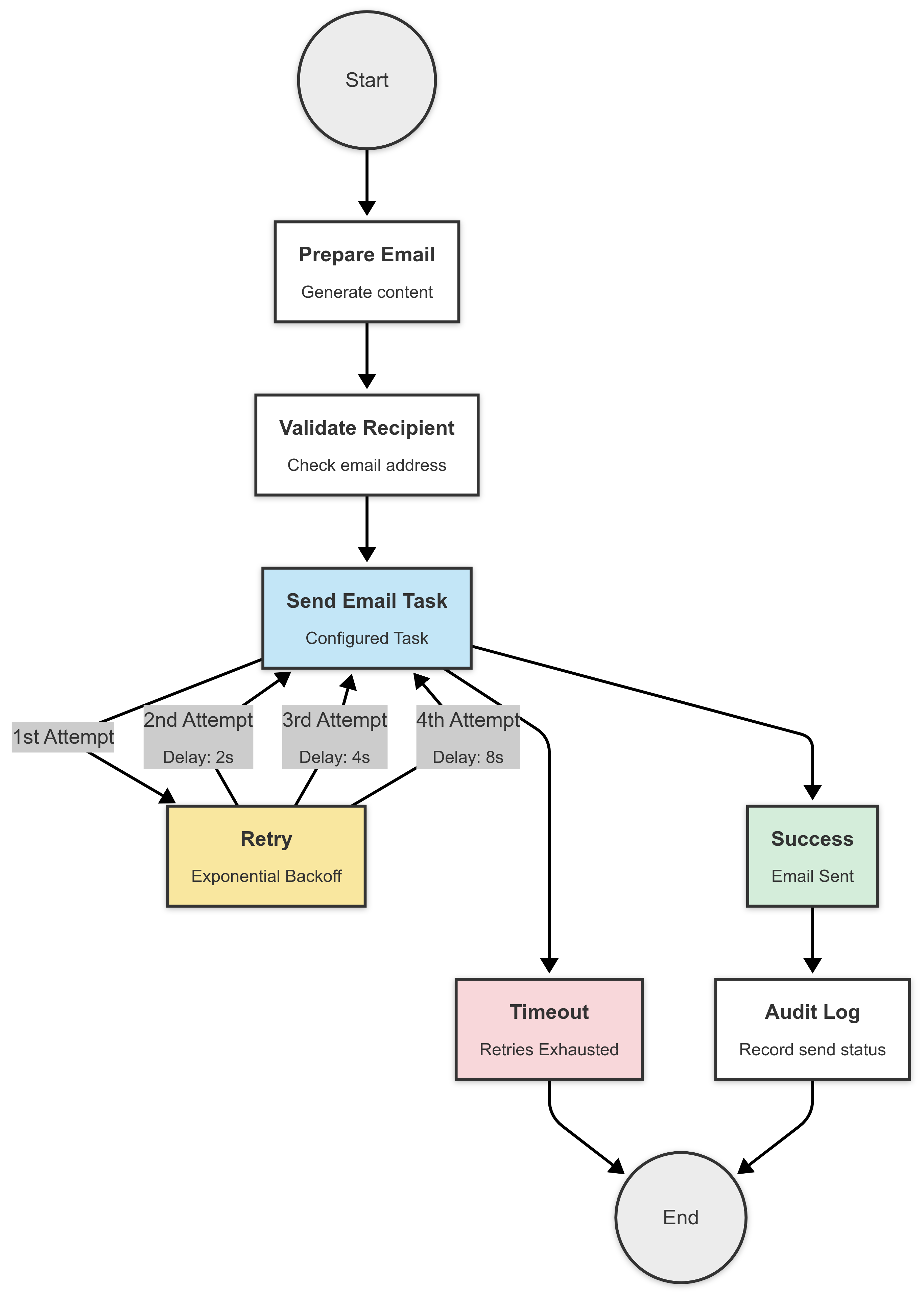
Retries help you recover, but timeouts prevent you from getting stuck in the first place. Whether a worker goes offline or an external service hangs, task-level timeouts ensure your workflow doesn’t wait forever.
Timeout parameters
| Parameter | Description |
|---|---|
pollTimeoutSeconds | The time to wait for a worker to poll this task before marking it as TIMED_OUT. |
responseTimeoutSeconds | The time to wait for a worker to send a status update (like IN_PROGRESS) after polling. |
timeoutSeconds | Total time allowed for the task to reach a terminal state. |
timeoutPolicy | Action to take when a timeout occurs:
|
Say you're calling a third-party inventory API that sometimes takes too long to respond. You don't want to wait forever, but you also don’t want to fail immediately. Here's how you'd configure a balanced timeout with retries:
from conductor.client.configuration.configuration import Configuration
from conductor.client.http.models import TaskDef
from conductor.client.orkes_clients import OrkesClients
def main():
api_config = Configuration()
clients = OrkesClients(configuration=api_config)
metadata_client = clients.get_metadata_client()
task_def = TaskDef()
task_def.name = 'inventory_check_task'
task_def.description = 'Check inventory status with timeout and retry settings'
# Retry settings
task_def.retry_count = 2
task_def.retry_logic = 'FIXED'
task_def.retry_delay_seconds = 5
# Timeout settings
task_def.timeout_seconds = 30
task_def.poll_timeout_seconds = 10
task_def.response_timeout_seconds = 15
task_def.timeout_policy = 'RETRY'
metadata_client.register_task_def(task_def=task_def)
print(f'Registered the task -- view at {api_config.ui_host}/taskDef/{task_def.name}')
if __name__ == '__main__':
main()
Check out the full sample code for the check inventory task.
This setup gives your worker 30 seconds to complete the task. If it doesn’t respond or fails, Conductor will retry it twice, waiting 5 seconds between each attempt.

Together, these retry and timeout configurations help you build workflows that are not just reactive, but resilient by design.
Next, we’ll look at how the same principles apply at the workflow level, giving you end-to-end control over your system’s behavior.
A key part of building resilient workflows is defining how long system tasks should wait on external services or heavy computations. In Orkes Conductor, each system task has default or configurable timeout settings to control this behavior.
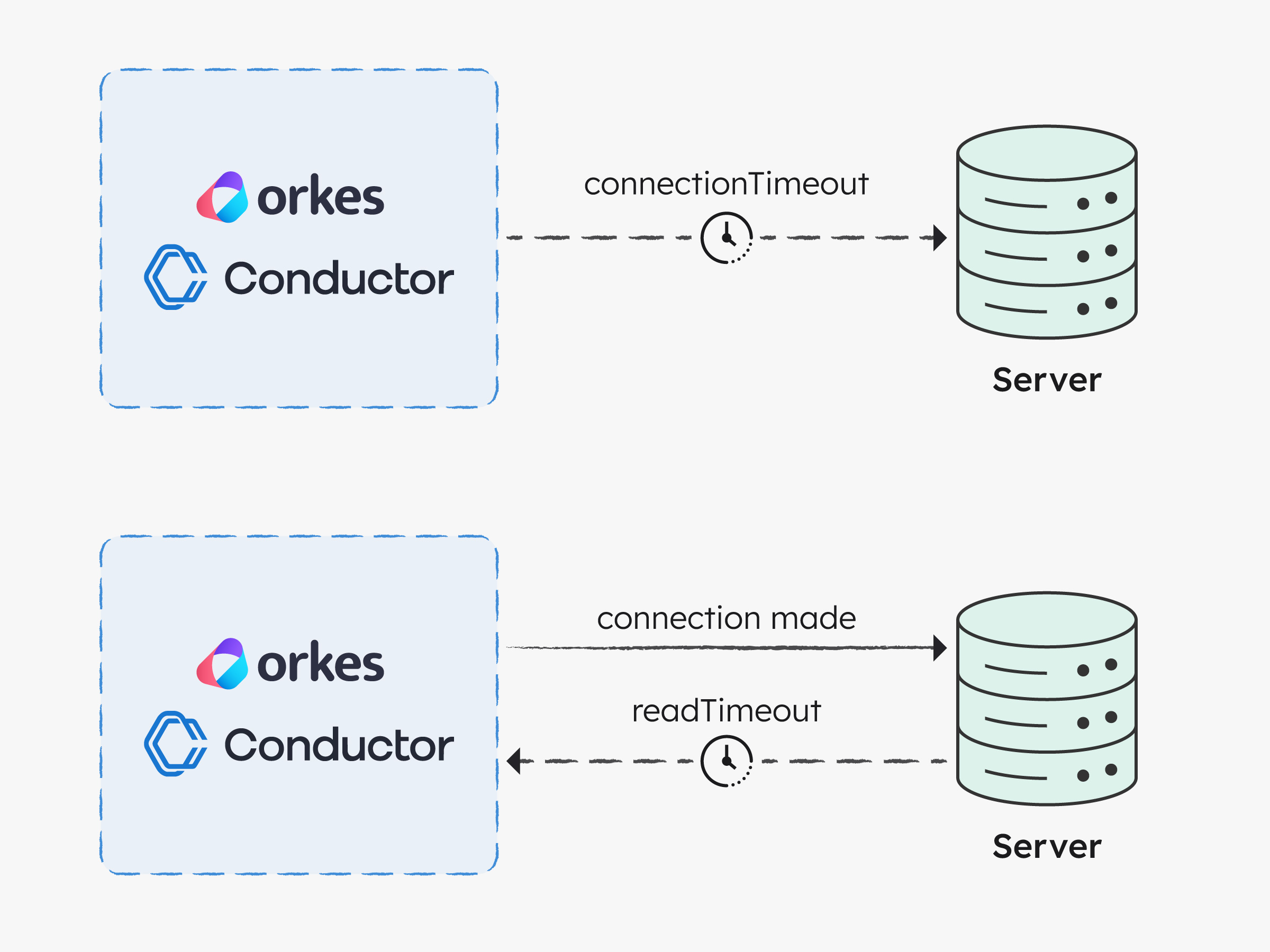
In Orkes Conductor, HTTP timeouts are defined by two parameters:
| Parameter | Description | Default Values |
|---|---|---|
connectionTimeout | The maximum time (in milliseconds) to establish a TCP connection to the remote server. | 30 sec |
readTimeout | The maximum time (in milliseconds) to wait for a response after the connection is established and the request is sent. | 60 sec |
In Orkes Conductor, these defaults are enforced to ensure platform stability.
Some system tasks have implicit timeout behaviors based on internal implementation. If you're designing workflows around system tasks, it's critical to understand and respect these limits.
| System Task | Connection Timeout | Read Timeout |
|---|---|---|
| HTTP | 30 sec | 60 sec |
| LLM | 60 sec | 60 sec |
| Opsgenie | 30 sec | 60 sec |
| Inline | n/a | 4 sec (max execution time) |
| Business Rule | 10 sec | 120 sec |
Task failures are unavoidable, but with proper retry and timeout configurations, they don’t have to break your workflows. Conductor’s task-level resilience features help you avoid cascading failures, handle transient issues gracefully, and prevent workflows from hanging indefinitely.
In the next article, we’ll scale this approach up and explore workflow-level failure handling strategies like timeout policies and compensation flows that give you end-to-end resilience.
Next up:
—
Orkes Conductor is an enterprise-grade orchestration platform for process automation, API and microservices orchestration, agentic workflows, and more. Check out the full set of features, or try it yourself using our free Developer Edition.