AGENTIC ENGINEERING
Building Durable Loops with Conductor, Part 1: Why Agentic Loops, and Why Now?

Nick Lotz
Content Engineer
Last updated: July 1, 2026
June 30, 2026
12 min read








Join thousands of developers building the future with Orkes.
An AI agent in some respects can be thought of as a loop. It asks a model what to do next, takes an action, and repeats until the task is done. This pattern certainly predates large language models, but LLMs made it the default behavior in agentic software. For example, the ReAct formulation of interleaved reasoning and acting (released in 2022!) is a loop, and so is every self-correcting variant that followed it.
While loops are easy to write, they are also very easy to underestimate. A while statement might behave perfectly in isolation. But it stops behaving well the moment the loop has to run longer than a short, individual session. Think integration with slow tool calls, an approval that takes a day, or redeploys with multiple process restarts. When the process holding the loop dies, the loop's state dies with it.
This series is about building a more robust approach. A durable loop keeps its iteration state in a runtime instead of in your process memory. We'll start by discussing how we got here: why agentic systems are loops, why the naive loop fails as tasks get longer, and what specifically makes a loop durable rather than merely restartable.
We'll then ground these concepts in a small working example on Conductor, the orchestration engine powered by Orkes. Later, we'll build the patterns production agents need on top of a durable loop.
A modern agent can be thought of as a control loop with a model inside it. Each pass, the model reads the current state and proposes an action, something executes that action, the result is appended to the state. Then the loop decides whether to go again.
This structure has been implemented in several different ways. ReAct runs a single loop that alternates a reasoning step with a tool call. Reflexion wraps an outer loop around it: after an attempt, the agent writes a critique of its own trajectory and runs the inner loop again with that reflection in context. Plan-and-execute agents split the work in two, one pass to draft a plan and a loop to carry it out and revise it.
But ultimately a survey of these systems finds a common architecture underneath the variations: memory, a step that decides on an action, and execution, iterated until a goal is met.
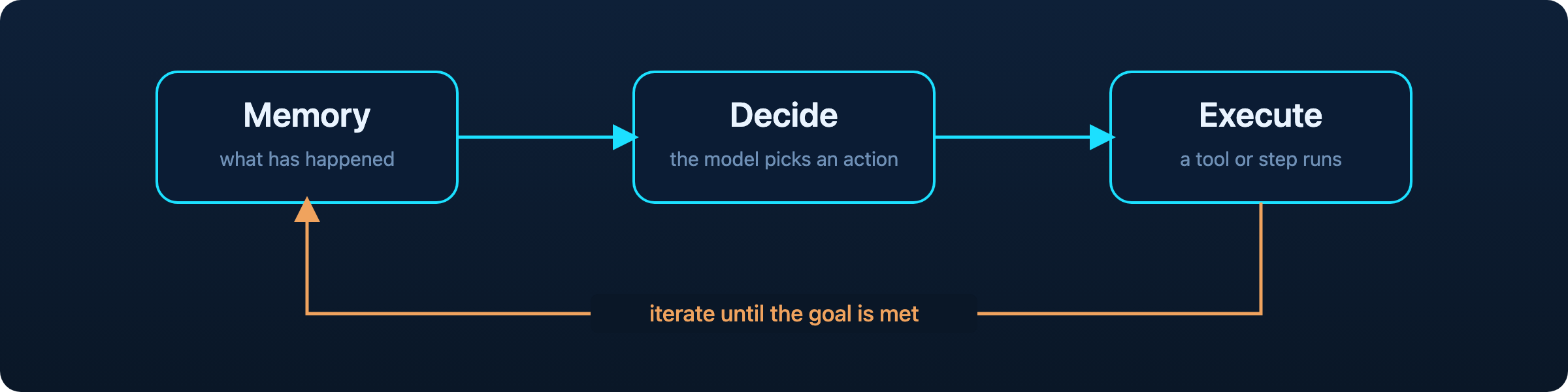 ReAct, Reflexion, and plan-and-execute all run the same loop: read the memory, decide an action, execute it, and repeat until the goal is met.
ReAct, Reflexion, and plan-and-execute all run the same loop: read the memory, decide an action, execute it, and repeat until the goal is met.
Because the loop is the control structure, its reliability is the agent's reliability. Anything the loop forgets, the agent forgets. Any pass that silently runs twice, the agent does twice. The question of how durable your agent is reduces to the question of how durable its loop is.
The case against the in-process loop starts as an arithmetic problem. Suppose every step of an agent succeeds, end to end, 99% of the time. A 20-step task then succeeds about 82% of the time, because 0.99 to the 20th power is 0.82.
A 100-step run, the size of a serious multi-agent task once sub-agent calls are counted, drops to 37%. Past a certain length, most runs hit at least one failed step.
Length also exposes failure modes that have nothing to do with the model's judgment! An in-process loop loses its state when the process dies mid-iteration. It repeats side effects when a restart replays a step whose effect already landed, so an agent that crashes after charging a card and before recording the charge will charge again on retry.
It also keeps no durable record of what the agent saw and decided, so a run that does something strange at three in the morning is unauditable after the fact. And it offers no way to meaningfully observe or intervene: once the loop is running, a human or a supervising agent cannot tell it to stop or reconsider.
A while loop has one response to any of this: start over from the top. That doubles the token usage, and is unsafe wherever an earlier step already had an effect.
Underneath sits a distinction the rest of this series depends on: durability is not continuity. Checkpointing your state to a database gives you durability, meaning your data survives. It does not give you continuity, meaning knowledge of which step was in flight when the process died and whether its effect already landed.
Continuity is what lets a system guarantee that a step runs effectively once, however many times the process dies between attempting it and recording it. A durable loop needs both. It has to persist the agent's state and the position of the loop itself.
Durable execution is an old idea that means the following: a computation's progress is persisted as it runs, so after a failure it resumes from the last committed point instead of restarting.
The idea predates agents by decades. Its lineage runs from the Sagas model of long-lived transactions, through event-sourced systems that reconstruct state by replaying a log, into the workflow engines that now carry agents. What they share is a commitment to treating each step's completion as a durable fact rather than a line of code that happened to run.
A loop is durable when four things hold:
 A loop is durable when the runtime owns the counter, commits each iteration, keeps steps idempotent, and terminates on purpose.
A loop is durable when the runtime owns the counter, commits each iteration, keeps steps idempotent, and terminates on purpose.
For example, Conductor models this with a loop task called DO_WHILE. The tasks inside it run once per iteration, and a loopCondition decides whether to repeat. The loop's state is owned by the Conductor server, not by the workers that do the work, which is the property that makes everything later in this post possible.
A durable loop is one point on a spectrum. At one end is the in-process while loop: maximally flexible, and gone the instant the process dies. At the other is the late-bound saga, where the execution graph does not exist when the run starts and the model synthesizes it edge by edge, committing each edge to a ledger before it runs.
A durable loop sits between them. Its approach is fixed, a body and a condition, but its state and position belong to the runtime.
This is a feature, not a limitation. A loop whose structure is known ahead of time is easy to reason about, easy to bound, and easy to recover, which is exactly what you want for the parts of an agent that repeat a well-defined step until a condition holds. Where the plan itself has to be invented as the agent goes, you reach for a saga. Where the agent repeats a known step, a durable loop is the smaller and sturdier tool.
Let's make it concrete. Start by launching a local Conductor instance via the official Docker container:
docker run --init -p 8080:8080 -p 5000:5000 conductoross/conductor:latest
A workflow is ultimately an underlying JSON. This one runs a step called agent_think until the step reports done, or until a ceiling of six iterations:
{
"name": "durable_agent_loop",
"version": 1,
"tasks": [
{
"name": "agent_loop",
"taskReferenceName": "agent_loop",
"type": "DO_WHILE",
"loopCondition": "if ($.agent_loop['iteration'] < 6 && $.think['done'] != true) { true; } else { false; }",
"loopOver": [
{
"name": "agent_think",
"taskReferenceName": "think",
"type": "SIMPLE",
"inputParameters": {
"goal": "${workflow.input.goal}",
"draft": "${think.output.draft}",
"iteration": "${agent_loop.output.iteration}"
}
}
]
}
]
}
Two references show the durability aspect. $.agent_loop['iteration'] is the loop counter, maintained by the server. ${think.output.draft} feeds the previous pass's output into the next pass, which means the running state lives in the workflow execution rather than in any worker.
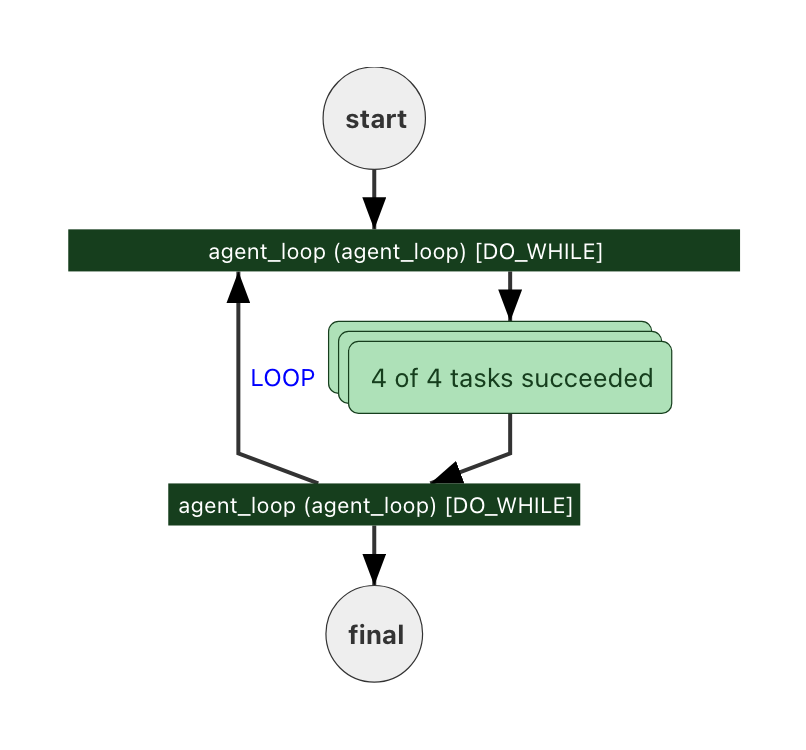 The
The DO_WHILE task is the loop. Conductor owns the iteration count and the per-pass state; the worker only does one pass at a time.
The step itself is an ordinary worker: a process that polls Conductor for agent_think work, calls a model, and reports the result. Here it runs one self-refinement pass with gpt-5.5 using the critique-and-improve move that Reflexion formalizes.
import json, requests
from openai import OpenAI
client = OpenAI() # reads OPENAI_API_KEY
SERVER = "http://localhost:8080/api"
SYSTEM = (
"You refine a definition over successive passes. Make one improvement per "
"pass and reply as JSON {draft, critique, done}. Always set done=false "
"before pass 4; from pass 4 on, set done=true only when the draft is "
"accurate, concrete, names the failure it prevents, and is 45 words or fewer."
)
def refine(goal, draft, n):
resp = client.chat.completions.create(
model="gpt-5.5",
response_format={"type": "json_object"},
messages=[{"role": "system", "content": SYSTEM},
{"role": "user", "content": json.dumps(
{"goal": goal, "current_draft": draft, "pass": n})}])
return json.loads(resp.choices[0].message.content)
while True: # a worker is just a process that polls
r = requests.get(f"{SERVER}/tasks/poll/agent_think")
if r.status_code == 204 or not r.text.strip():
continue # nothing queued right now
task = r.json()
if not task or not task.get("taskId"):
continue
d = task["inputData"]
out = refine(d["goal"], d.get("draft") or "", d.get("iteration") or 0)
requests.post(f"{SERVER}/tasks", json={
"taskId": task["taskId"],
"workflowInstanceId": task["workflowInstanceId"],
"status": "COMPLETED", "outputData": out})
Register the workflow and start a run:
curl -X POST localhost:8080/api/metadata/taskdefs -H 'Content-Type: application/json' \
-d '[{"name":"agent_think","responseTimeoutSeconds":20,"retryCount":3}]'
curl -X POST localhost:8080/api/metadata/workflow -H 'Content-Type: application/json' \
-d @durable_agent_loop.json
curl -X POST localhost:8080/api/workflow/durable_agent_loop -H 'Content-Type: application/json' \
-d '{"goal":"Define durable execution for a senior engineer."}'
Notice there is no agent loop in the worker. It handles one pass and returns; Conductor decides whether to schedule another. On this run the agent took four passes, about sixteen seconds, before it judged the draft good enough and set done.
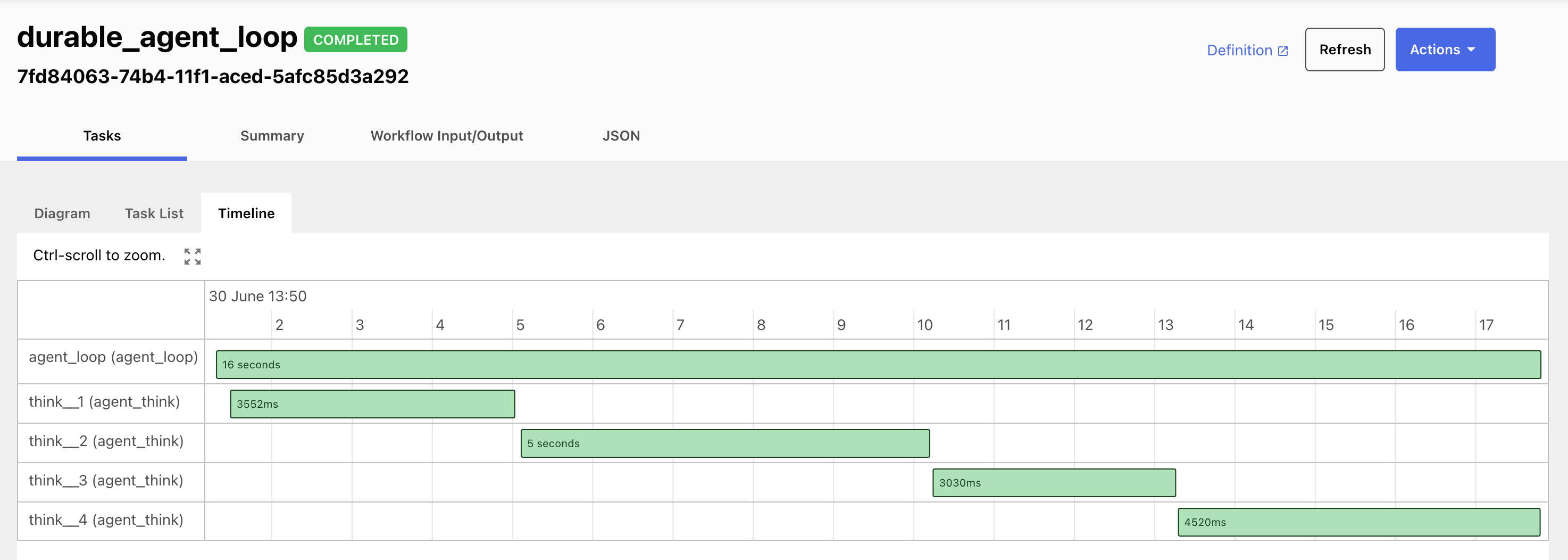 Four
Four gpt-5.5 passes, each one iteration of the same DO_WHILE loop, recorded by the server as they ran.
It converged on:
Durable execution is a runtime model that persists execution history, checkpoints, and recorded external I/O results so, after crashes, restarts, or redeploys, it can deterministically resume from the last committed step instead of re-running completed work, preventing duplicate side effects.
Here is the part the in-process loop cannot do. We start the loop, let two passes commit, and kill -9 the worker while the third pass is mid-flight, in the middle of its model call. The process is gone. Nothing is running.
The loop does not go with it. The interrupted pass sits as IN_PROGRESS on the server until its response timeout elapses; the server then marks it TIMED_OUT and re-queues it.
We start a fresh worker. It polls, picks up the re-queued pass, finishes it, and the loop runs to completion. The first two passes are never repeated, because the server already committed them.
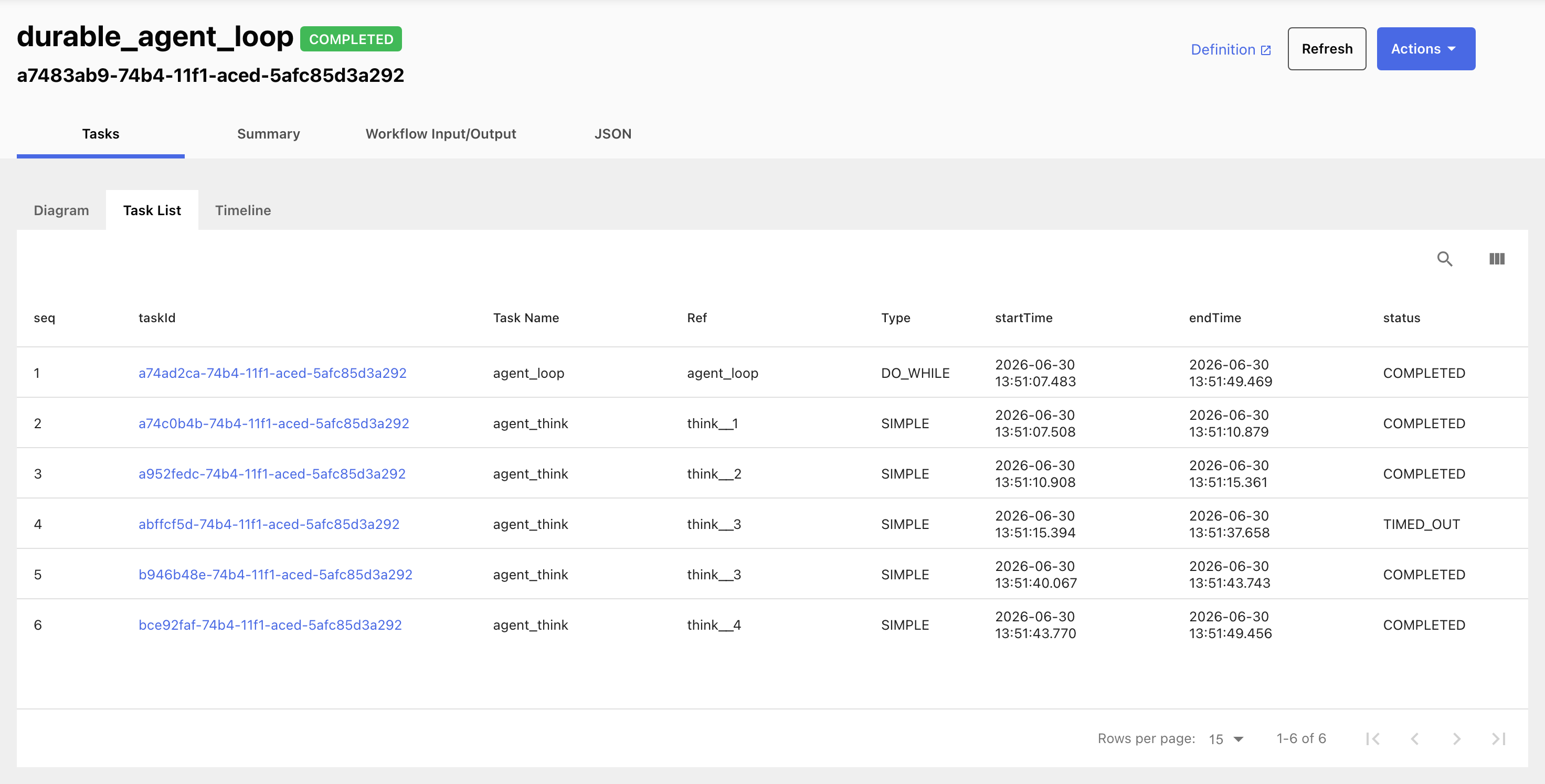 Pass
Pass think__3 timed out when its worker was killed, then ran again on a fresh worker and completed. The loop finished without losing the earlier passes.
This is the continuity we mentioned earlier, not just durability. The server knew which iteration was in flight, knew it had not committed, and handed it to another worker. The two committed passes were not lost and not repeated, so the loop resumed at the third pass instead of restarting from the top.
A durable loop removes the penalty for running long, which makes it easy to write loops that never stop. Two guards matter. First, give every loop a ceiling, so a model that never declares itself finished still terminates. And make each step idempotent, so the re-queue after a crash does not double an effect. Refining a draft was safe to retry because it has no external side effect; a step that charges a card or sends an email needs an idempotency key to be equally safe.
There is also a subtlety in how state crosses a crash: ${think.output.draft} resolves to the most recent task instance, so a pass retried after a timeout reads that timed-out instance's empty output rather than the last good draft. When a loop must carry accumulated state through a mid-pass failure, hold it in a workflow variable or reference the last committed output explicitly.
Part 1 establishes the idea of moving the loop off your process and into a runtime that owns its state, and the agent stops being something that dies when its process does. The next part will build on the same DO_WHILE foundation, with the patterns production agents actually need: pausing a loop for human approval and resuming it on a signal, fanning a loop out across parallel sub-agents, and changing a loop's definition without breaking the runs already in flight.


