SOLUTIONS
Upgrade EKS Clusters across Multiple Versions in Less Than a Day — using Automated Workflows

Liv Wong
Technical Writer
Last updated: April 8, 2024
April 8, 2024
7 min read








Join thousands of developers building the future with Orkes.
Upgrading your Kubernetes clusters to the latest version can be a time-consuming and laborious process, even with a managed Kubernetes service like Amazon Elastic Kubernetes Service (EKS). Amazon EKS does the heavy lifting of implementing the upgrade, such as creating new control planes and initiating rollbacks in case of failure. But to ensure a successful update, cloud engineers still need to spend days or weeks to orchestrate several high-level tasks behind the scenes:
With three Kubernetes releases every year and only 14-months’ standard support for each release, the technical overhead to maintain your cloud infrastructure ramps up rapidly. An enterprise that uses a single cluster with several node groups may be able to handle the technical overhead with some effort. But organizations with tens or hundreds of clusters, each with different configurations, may soon find themselves overwhelmed trying to keep up.
Using Orkes as an example, let’s take a look at the difficulties we faced during a manual upgrade, and how we used an automated workflow in Conductor to update our clusters from 1.25 all the way to 1.29 in under 7 hours.
At Orkes, we deploy and manage numerous clusters for our customers. In this scenario, our EKS clusters are significantly outdated and reaching the end of Amazon’s standard support in less than two months.
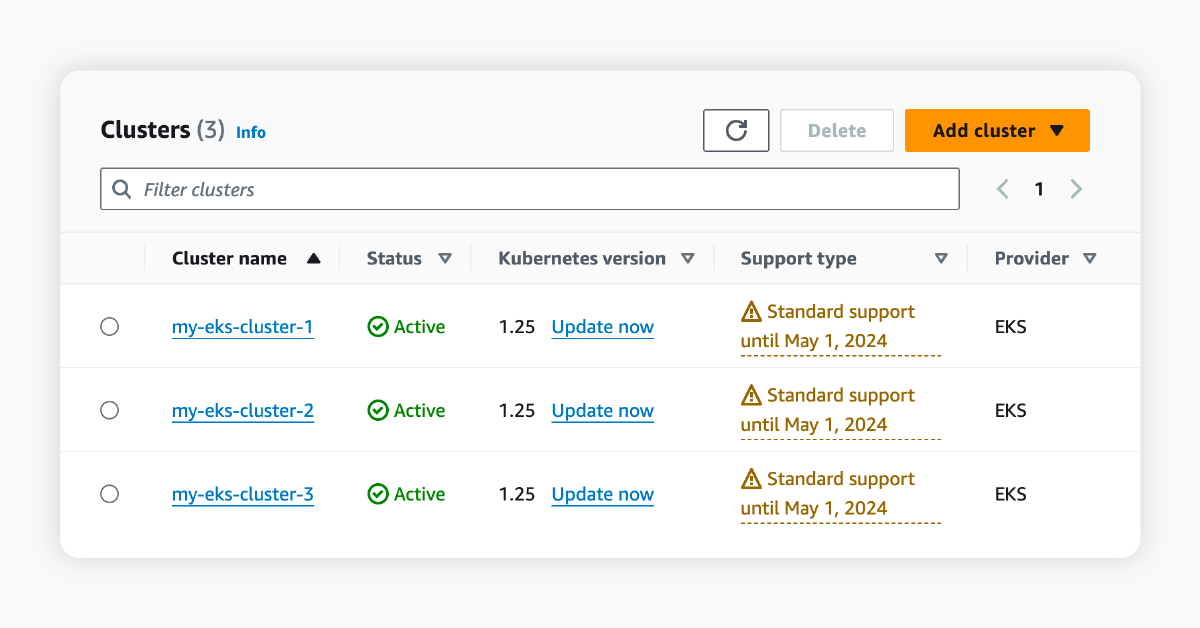
Kubernetes only allows upgrades from one minor version to another (for example, 1.25 to 1.26). To go from version 1.25 to 1.29, our engineers would have to upgrade each cluster, each underlying node group, and each associated add-on in multiple iterations. Using the CLI or Amazon console, this would be a very tedious process of entering command after command, clicking button after button, with tons of time spent waiting for each update task to be completed before starting the next task.
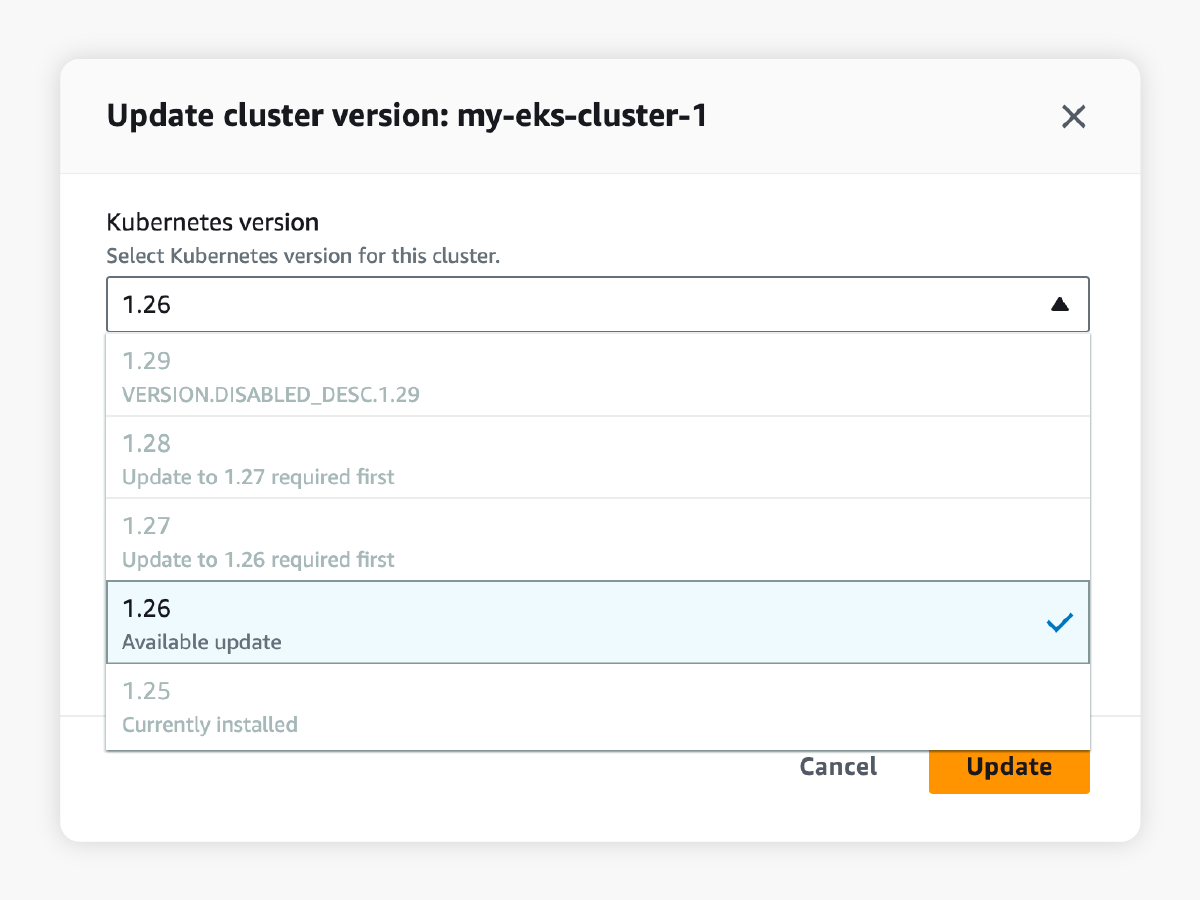
Furthermore, to reduce the risk of downtime during the upgrade process, it is best practice to upgrade each node or node group one by one, rather than all at once. Twenty node groups would amount to twenty iterative updates using the CLI or Amazon console, significantly extending the time spent to manually update the EKS cluster.
Automated scripting tools can help resolve this issue. However, these tools only automate one part of the entire upgrade process. Without workflow orchestration, there’s no easy way to automate additional steps into a single workflow, such as conducting custom checks and sending status notifications, all of which are vital tasks enterprises would require. Which brings us to the next problem:
Beyond the time-consuming effort of updating each cluster manually, every upgrade also requires pre- and post-upgrade checks to ensure that the cluster is fully functioning: safe to be updated prior, and works as expected after.
Managed Kubernetes services like Amazon EKS and Google Kubernetes Engine (GKE) provide some degree of pre-upgrade checks, such as evaluating the upgrade compatibility. However, additional health checks are often critical in ensuring that the cluster is up, running, and ready to receive traffic. This would require configuring and running observability tools, such as probes, in your applications.
In our case at Orkes, we also needed to run custom checks to ensure that our container images can be reached post-upgrade and that any failure would be flagged. For example, if there are changes to the cluster’s security group or firewall settings, which may create issues with rescheduling the container images onto the new nodes, our engineers can detect such issues and fix them before commencing the cluster upgrade.
With the EKS cluster upgrade fragmented into disparate steps, there is limited visibility into the progress – are the pre-upgrade checks still ongoing, or has the upgrade commenced proper?
Of course, our cloud engineers could track the progress by watching the Amazon console or listening to an event. But we needed an effective way for all relevant teams in the company to be kept in the loop as well. This means global visibility into the entire process, even beyond the upgrade step on Amazon itself, and automatic notifications at critical junctures for human intervention, informing us about success, failure, and reason for failure.
Here at Orkes, instead of manually upgrading our clusters, we leverage our workflow orchestration platform, Conductor, to execute the upgrade quickly and efficiently. Orkes Conductor is an enterprise-grade platform that enables you to hook together any task or process into an automated workflow, thus simplifying development and operations at scale. With Conductor, every step – custom checks, upgrade commands, notifications, and so on – is unified into a single upgrade workflow, which is further powered by in-built features for scheduling, failure handling, global visibility, and more.
Let’s dive into how we used Conductor to upgrade our EKS clusters.
Every upgrade comes with careful research and planning, from identifying impacted areas in Kubernetes’ release notes to planning out what needs to be done. Building out an upgrade workflow for the first time in Conductor is no different. At Orkes, our workflow included these key tasks:
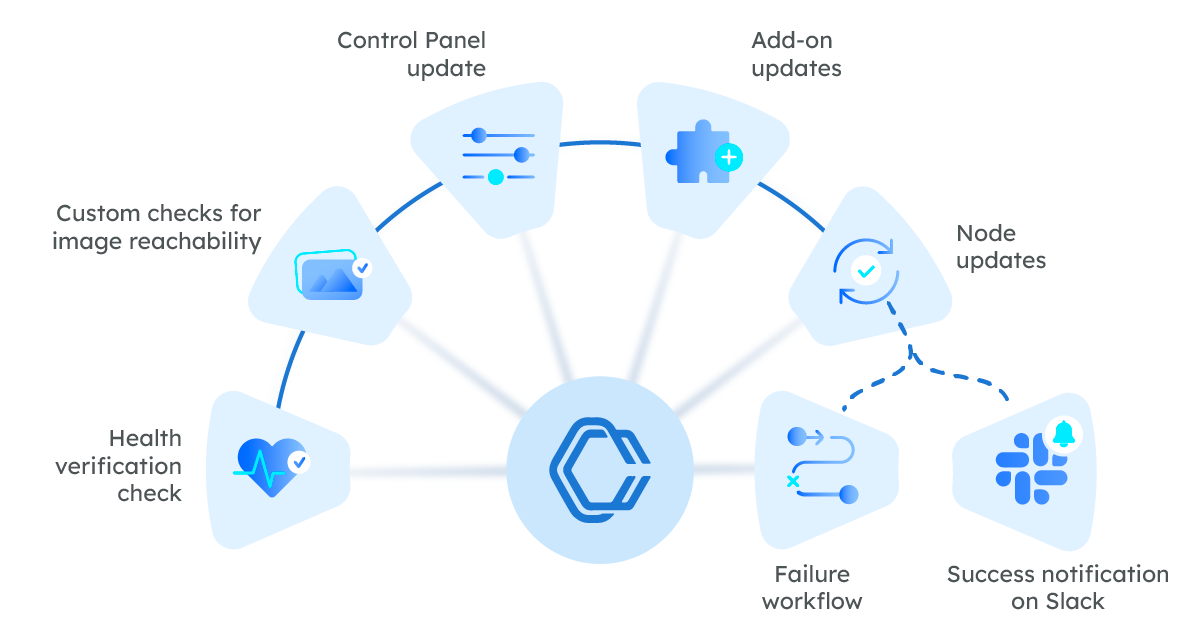
Once our team has pinned down what to do, the upgrade process becomes an algorithmic operation that can be scaled. With a single Conductor workflow, our team at Orkes manages upgrades for hundreds of clusters all year round.
Here is the full Conductor workflow, and the features we utilized to make the upgrade process seamless for us:
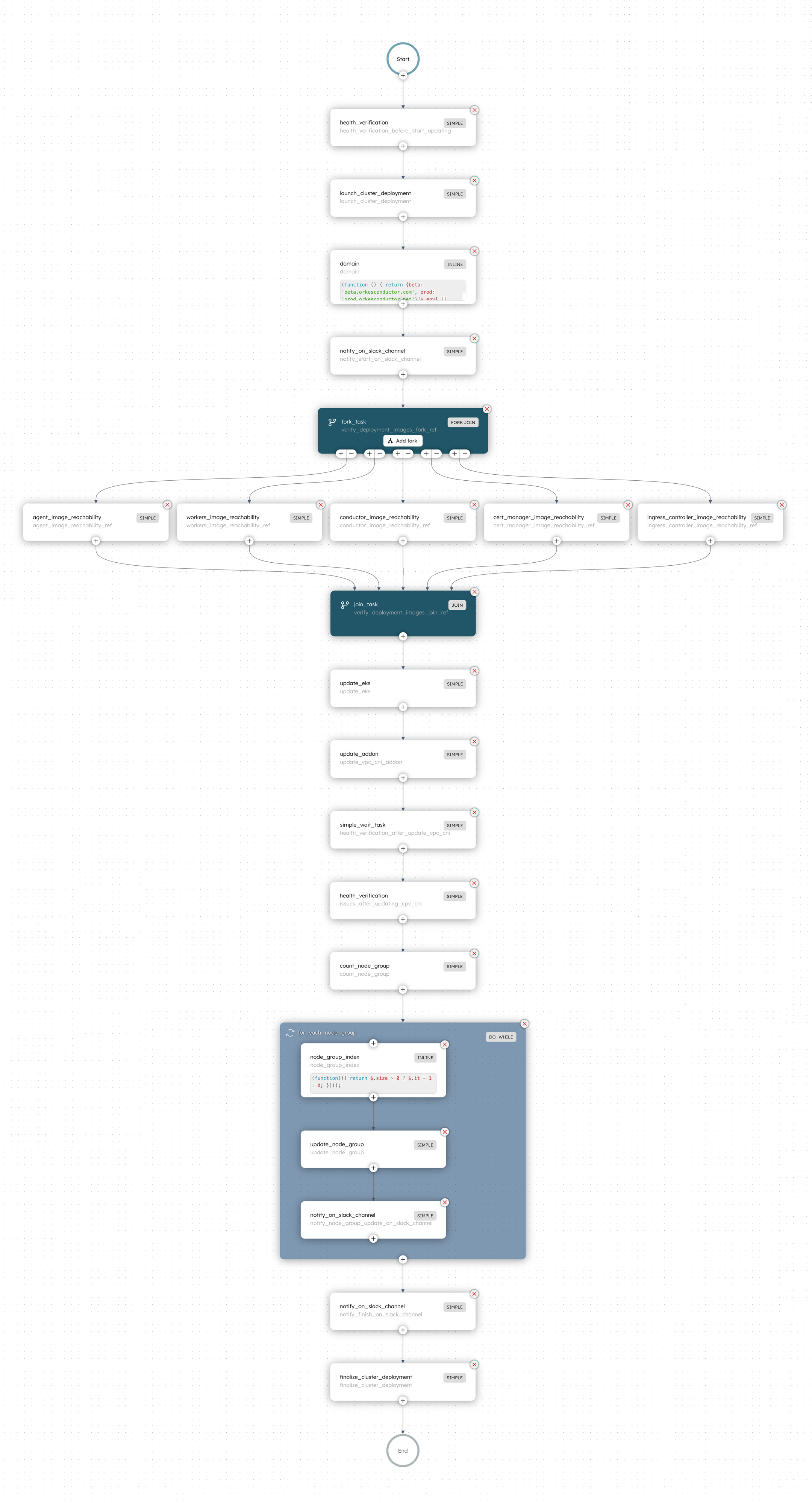
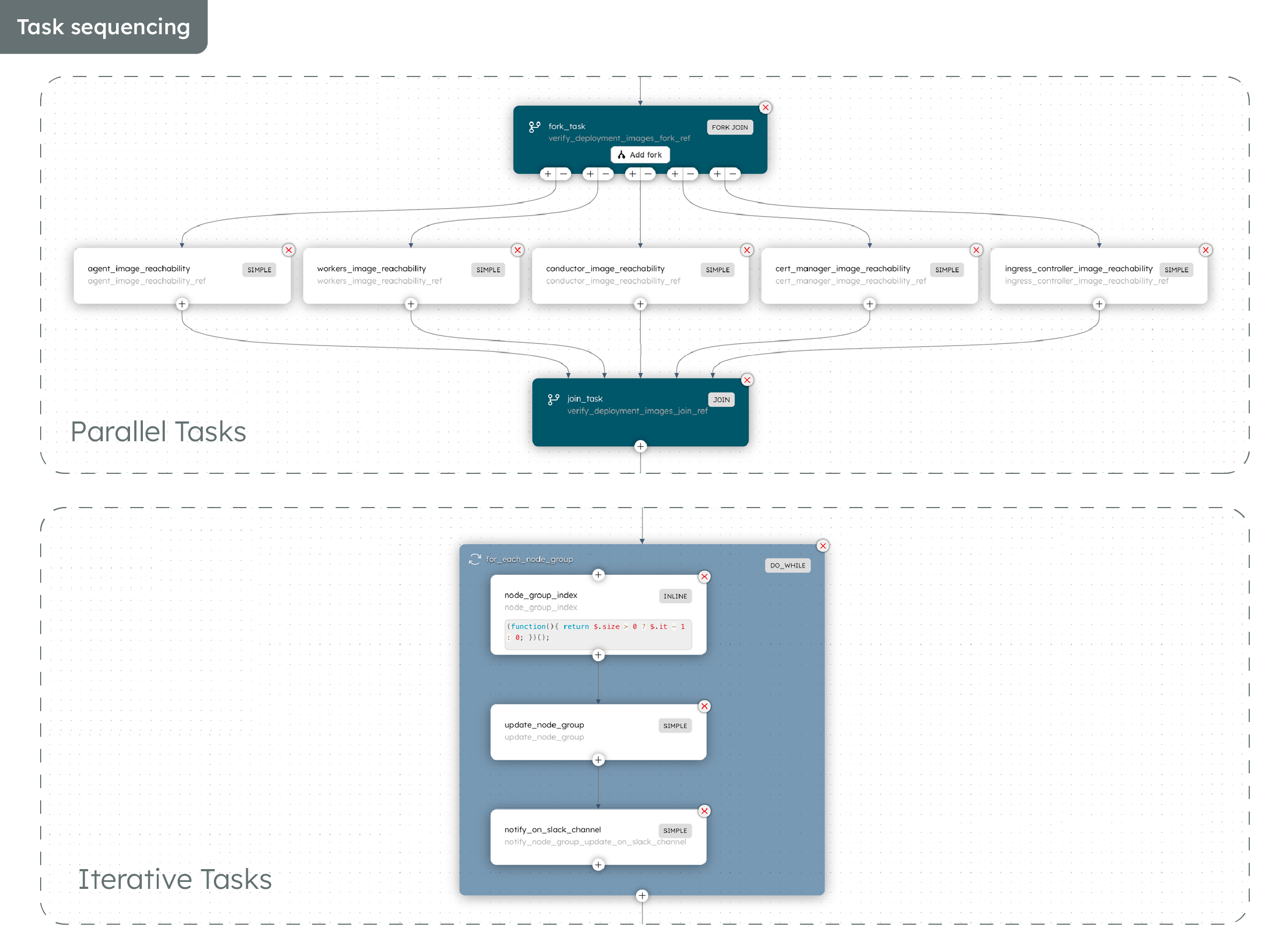
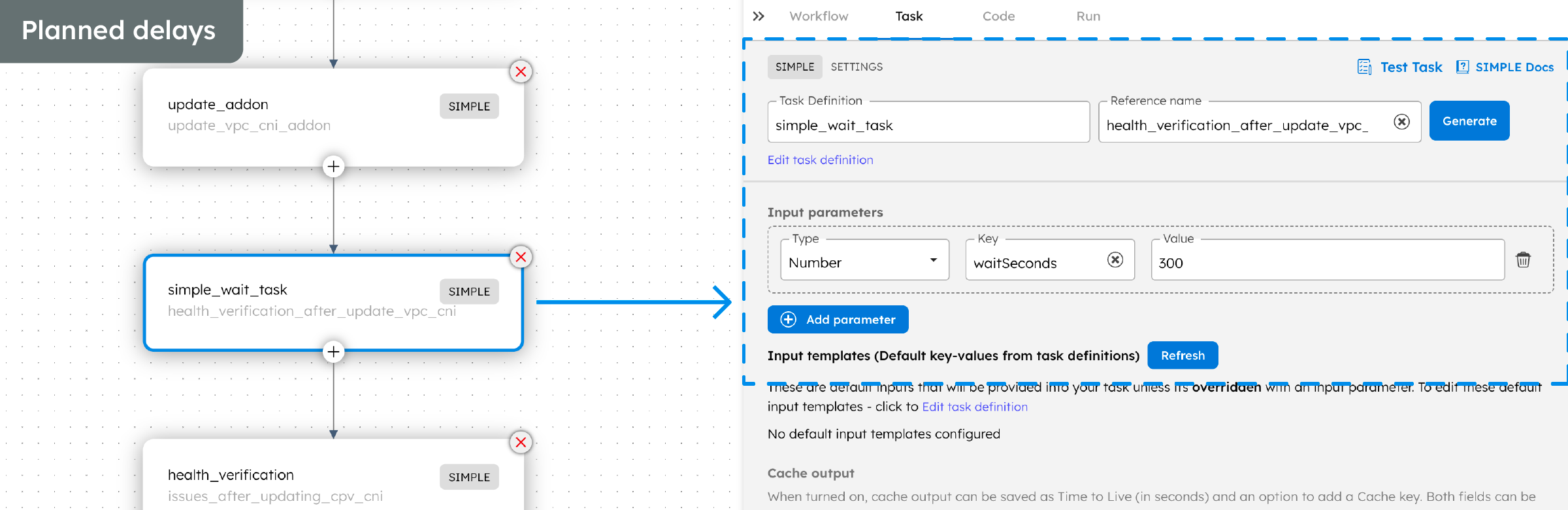

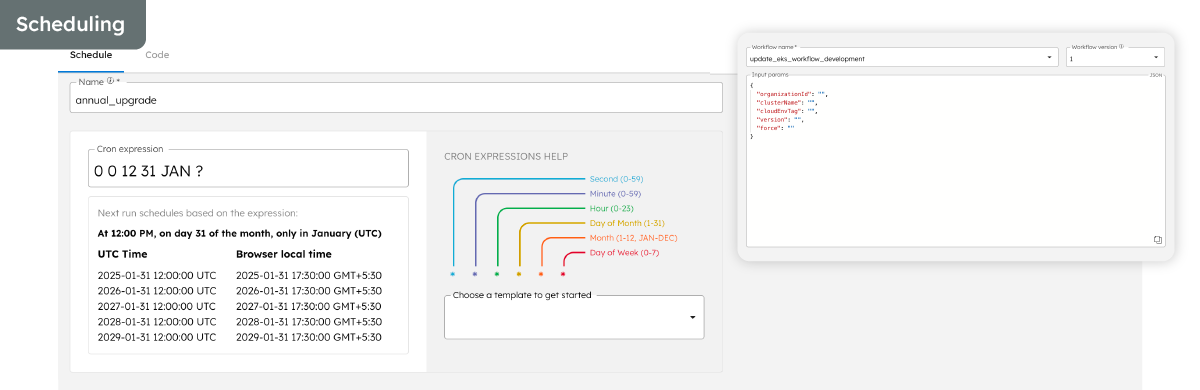
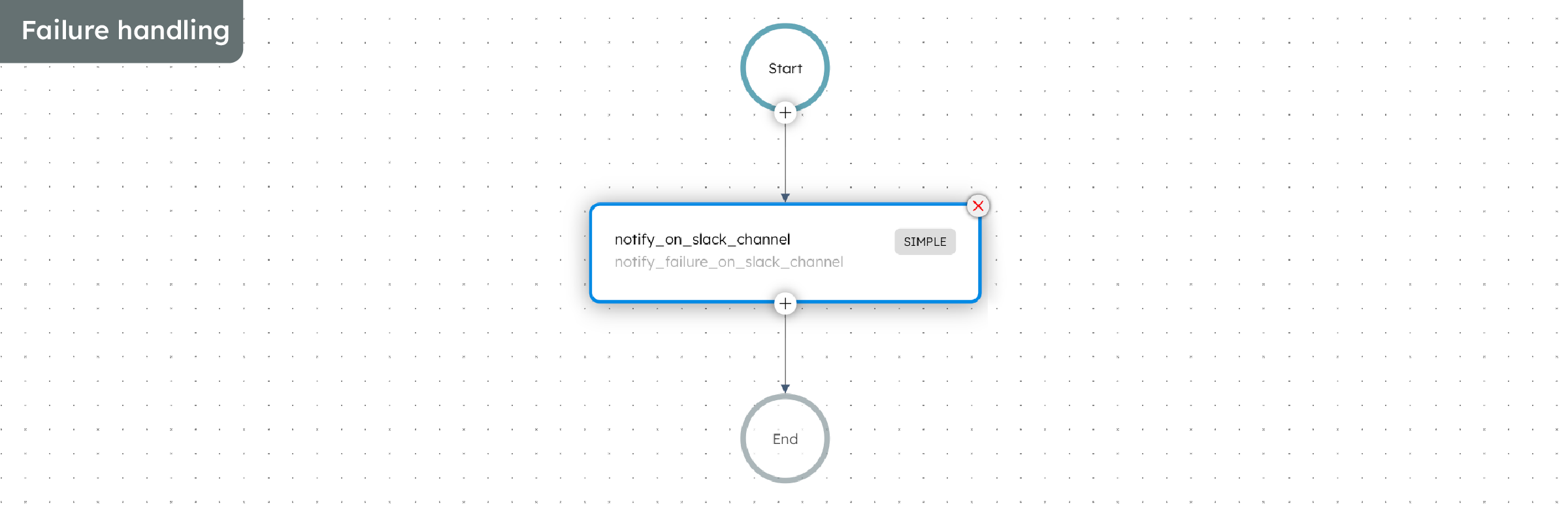
In summary, we overcame the problems that came with manual cluster upgrades by using an automated workflow in Conductor. By leveraging Conductor, engineering teams can streamline cloud infrastructure activities and transform it into a highly efficient, automated procedure with these benefits:
Curious to learn more about building workflows in Conductor? Check out our documentation or GitHub repository.
Conductor is an enterprise-grade orchestration platform for process automation, API and microservices orchestration, agentic workflows, and more. Check out the full set of features, try it yourself using our Developer Edition sandbox, or get a demo of Orkes Cloud, a fully managed and hosted Conductor service.