ENGINEERING
Best Practices for Production-Scale RAG Systems — An Implementation Guide

Liv Wong
Technical Writer
Last updated: February 20, 2025
February 20, 2025
9 min read








Join thousands of developers building the future with Orkes.
Knowledge bases can augment AI model responses by providing additional background information. For instance, a financial analyst bot would need access to reports, market prices, and industry news; while a policy advisor bot would need access to hundreds of policy documents.
RAG (retrieval-augmented generation) is a popular method for providing AI models access to such background knowledge. At a high level, such knowledge gets chunked and stored in a database, which is later used to retrieve the most relevant information based on the user query. The retrieved information gets appended to the prompt sent to the AI model, thus improving its final response to the user query.
In theory, it sounds straightforward enough. But to implement a production-ready RAG system, we would need to consider factors like retrieval quality, search speed, and response quality to meet user satisfaction. Let’s explore some common issues in implementing RAG systems and best practices for resolving them. Afterward, we will demonstrate an implementation example built using an orchestration platform like Orkes Conductor.
Documents lose context when chunked, which affects the retrieval quality and subsequent response quality.
For example, chunks in a financial knowledge base may contain revenue data without specifying the company:
“Dollars in millions, except per share data FISCAL 2024 FISCAL 2023 % CHANGE
Revenues $ 38,343 $ 38,584 0 %”.
Without the proper context, a search query like “What was the revenue for Acme Inc in 2024?” could pull up dozens of incorrect revenue data for the AI model to process and reference. The model could just as well respond with revenue from Nakatomi Trading Corp or Sirius Cybernetics rather than from Acme Inc.
The vector embedding approach to storing and retrieving information is inherently lossy and may miss out on retrieving chunks with exact lexical matches.
Vector embeddings capture semantic meaning, like lexical relationships (e.g., actor/actress are closely related), intent (e.g., positive/negative), and contextual significance. This approach works well for capturing meaningful information, such that two completely different sentences, “I love cats” and “Cats are the best”, are marked as highly similar due to their conceptual similarity.
On the flip side, this means that precise and specific wording gets lost in the vectorization process. As such, a typical vector-based RAG approach can sometimes fail to pick up on exact lexical matches.
For example, if you are trying to search for information about the Cornish Rex, a chunk like:
“The appearance of the German Rex is reminiscent of the European Shorthair. Both cat breeds are of medium size and rather stocky build. The German Rex is a strong, muscular cat with a round head and a broad forehead, pronounced cheeks and large round eyes. It strolls through its territory on medium-long legs. The German Rex is not a graceful, Oriental-looking cat like its Cornish Rex and Devon Rex counterparts. It has a robust and grounded appearance.” - [Source](https://www.catsbest.eu/cat-breed/german-rex/)
could be overlooked by the RAG system because it is primarily about the German Rex, and thus stored further away from chunks about the Cornish Rex in the vector space.
Now, let’s explore some best practices to mitigate the common issues outlined above.
First: introduce context back into the chunks. This can be as simple as prepending chunks with the document and section titles, a method sometimes known as contextual chunk headers.
Document title: Acme Inc Annual Fiscal Report
Section title: Results of Operation
“Dollars in millions, except per share data FISCAL 2024 FISCAL 2023 % CHANGE
Revenues $ 38,343 $ 37,584 0 %”
Or it can be as elaborate as Anthropic’s context retrieval method, where a summary of the chunk’s relation to the entire document is added to the chunk. In this approach, the contextual summaries are generated by an AI model using a prompt like:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
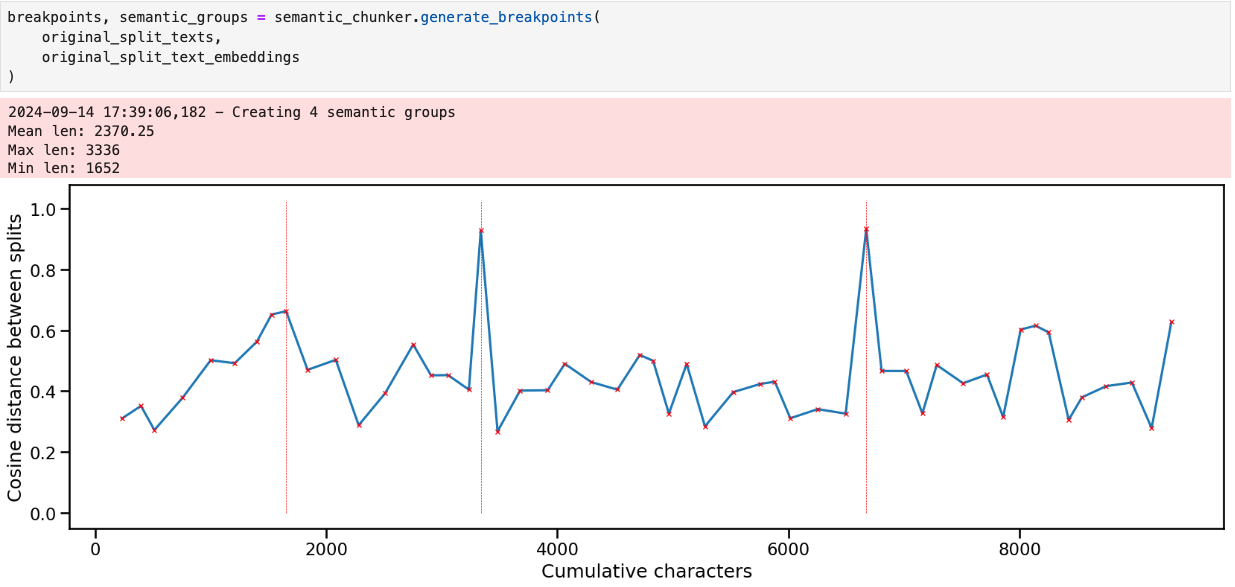
Semantic chunking can also help preserve each chunk's context. Rather than fixed-sized chunking, semantic chunking takes meaning and context into account when dividing the text.
In this approach, the text is split into individual sentences that are then indexed as embeddings. These sentence-level embeddings enable us to compare the semantic similarity of each sentence with neighboring sentences and split the chunks based on a breakpoint threshold value. This is useful for maintaining each chunk’s semantic integrity, which is essential for more accurate retrieval.
Next: use multiple search techniques at once to capitalize on each of their strengths. A hybrid search approach leverages both keyword-based search and vector search techniques, then combines the search results from both methods to provide a final search result.
BM25 (Best Matching 25) is one of the most popular ranking functions, used across major search engines. It’s a bag-of-words retrieval function that ranks documents based on the frequency of the search query appearing in its contents. BM25F is a variant that enables you to modify the weights of different fields, such as making the document body more important than the title.
These keyword-based functions remediate the lossy nature of vector searches, and using both types of search methods at once will cover the major bases in retrieving relevant information.
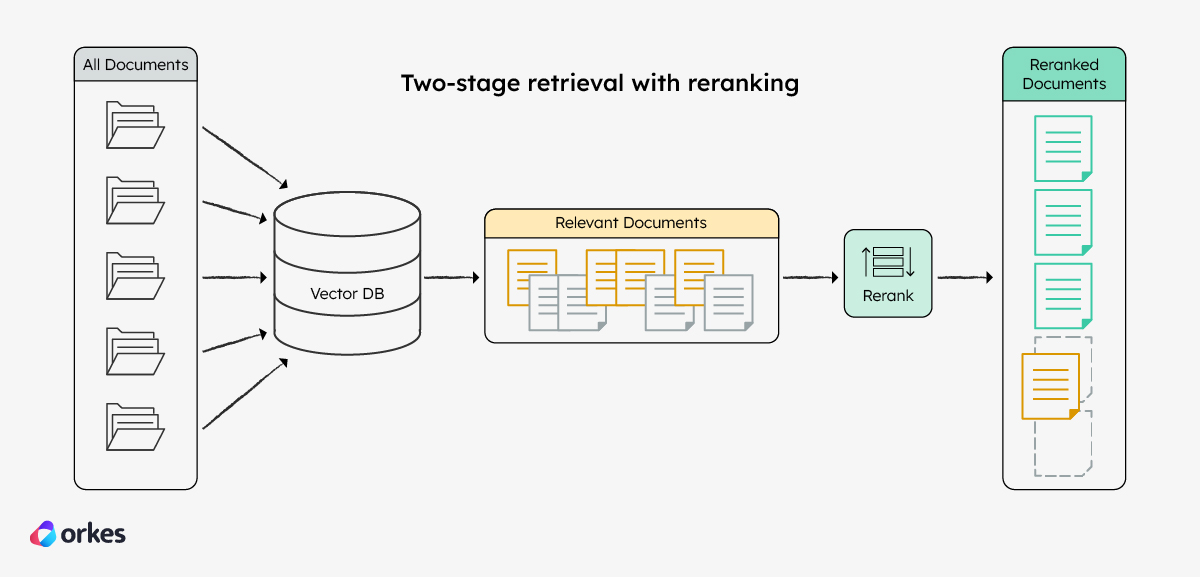
Reranking can also help to surface more relevant information from the set of retrieved documents. Rerankers are more accurate than embedding models in analyzing and comparing the query against the knowledge base, but are also much slower in processing compared to embedding models.
The best of both worlds (accuracy and speed) means using a two-stage retrieval process, where an embedding model is used to retrieve a subset of information from the entire knowledge base, and a reranker is used to further pare down and refine the search results.
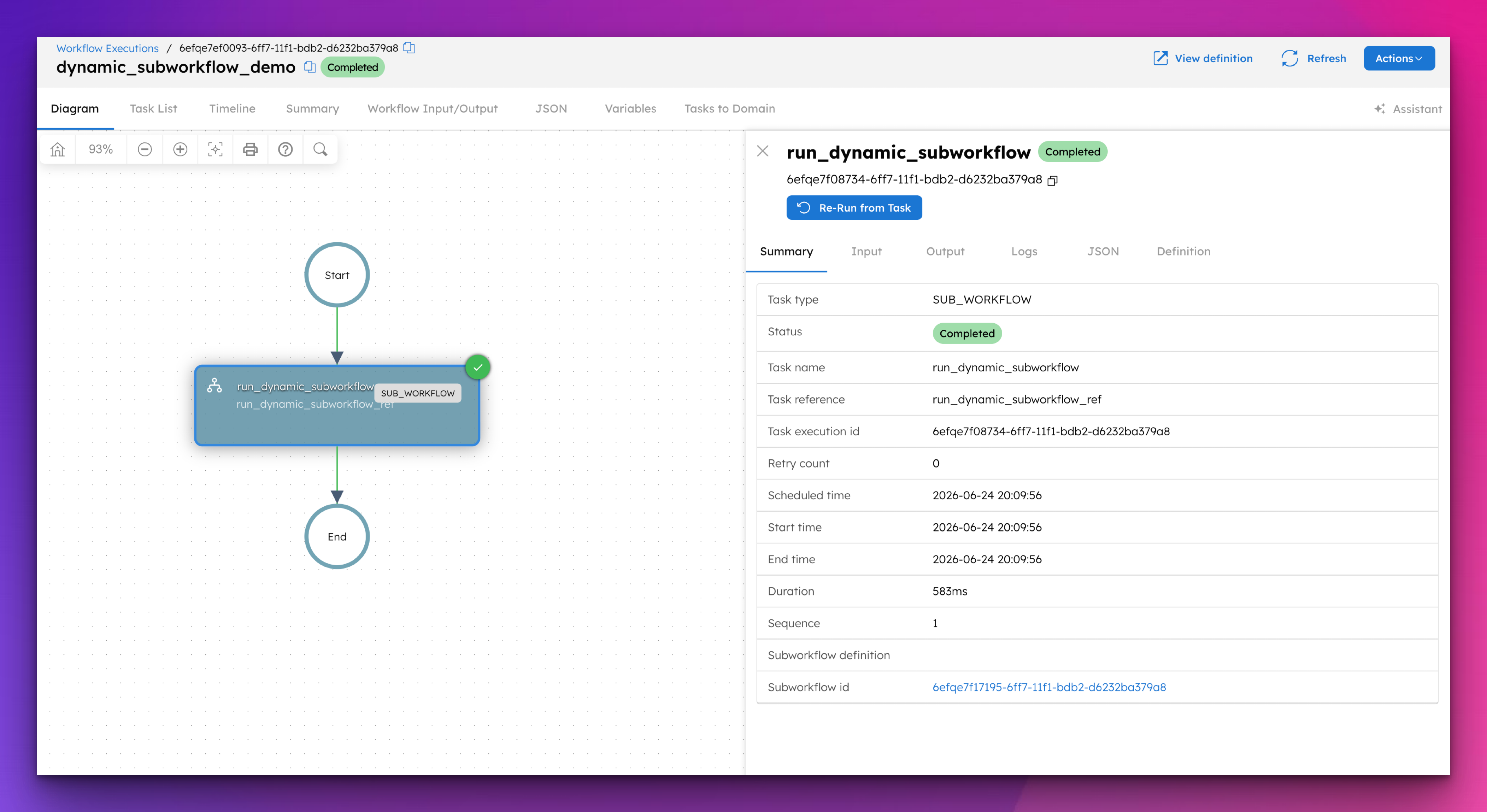
How can these best practices be implemented? Let’s look at an example of a production-grade RAG system that is efficiently implemented and monitored using an orchestration platform like Orkes Conductor. Using orchestration, developers can build and monitor complex flows across distributed components, frameworks, and languages. In our case, there are two key workflows required to build a RAG system:
index workflowsearch workflowTip: If you’d like to try building a RAG system yourself, sign up for our free developer sandbox at Orkes Developer Edition.
The index workflow consists of several parts:
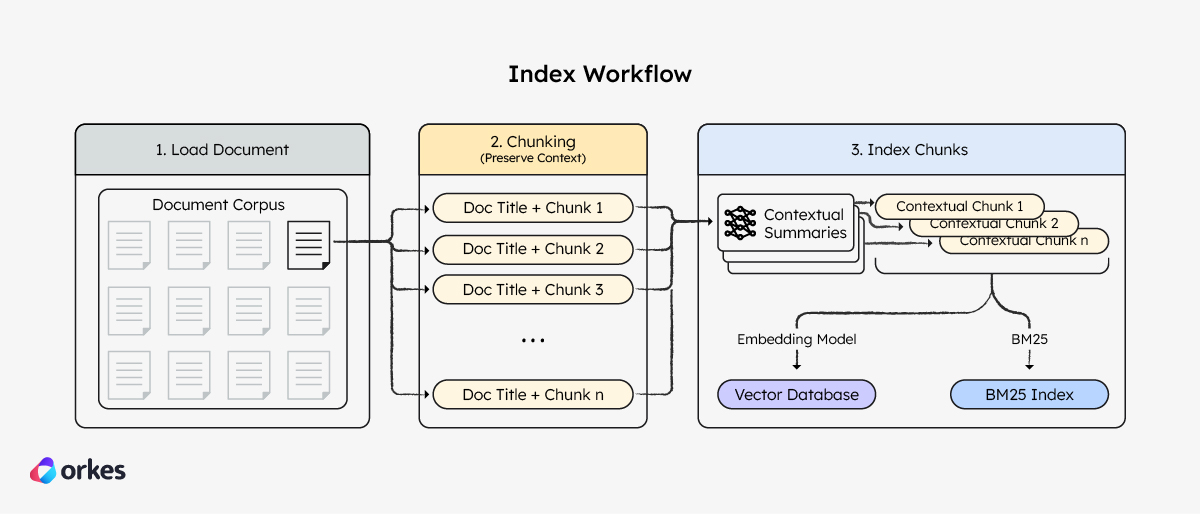
Part 1: Load a document from a source
As an orchestration engine, Conductor facilitates all sorts of implementation choices with its wide variety of tasks. In this example, we’ve used a pre-made Get Document task to retrieve a private policy document stored on an internal URL.
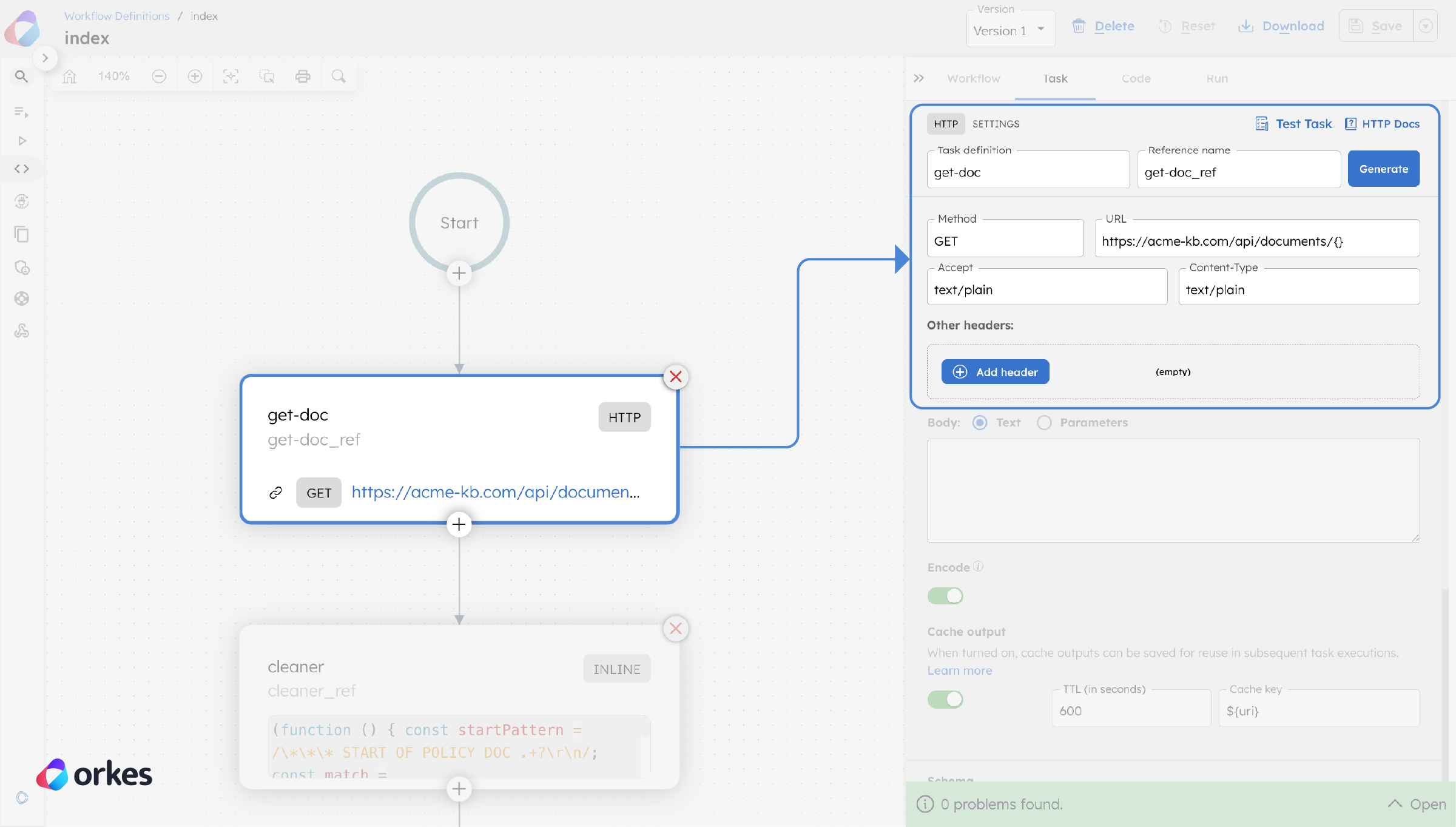
You could also use an HTTP task to get a document through an API call, or create a custom task for whatever custom implementation.
Part 2: Chunk the data
The chunking task can be implemented using an Inline task or custom worker task. Here’s a sample Inline task code that utilizes a straightforward fixed-size chunking method with some overlap to reduce context loss:
(() => {
const policy = $.input.substring(0, $.input.indexOf('Policy'));
const context = 'This chunk is from the policy: ' + policy + '. ';
const paragraphs = $.input.split(/
/);
const chunks = [];
let currentChunk = "";
for (const paragraph of paragraphs) {
if (currentChunk.length + paragraph.length < 1000) {
currentChunk += (currentChunk ? "
" : "") + paragraph;
} else {
if (currentChunk) {
chunks.push(context + currentChunk);
}
const lastChunk = chunks[chunks.length - 1] || "";
const overlapText = lastChunk.slice(-200);
currentChunk = overlapText + "
" + paragraph;
}
}
if (currentChunk) {
chunks.push(context + currentChunk);
}
return chunks;
})();The contextual chunk headers can be created within the same chunking task:
const context = 'This chunk is from the policy: ' + policy + '. ';
// … code omitted
if (currentChunk) {
chunks.push(context + currentChunk);
}The more elaborate situated context approach (à la Anthropic) can be completed in a separate task during the final indexing part.
One major benefit of using Conductor to orchestrate these distributed components is the ease of switching up tasks and managing workflow versions. If we wanted to test whether semantic chunking will be worth the computational cost, it’s as simple as switching out the fixed-size chunking task with a new worker task that runs a different piece of code.
Using Conductor’s SDKs, you can easily write a worker that carries out semantic splitting with your framework of choice (LlamaIndex, Langchain, and so on).
Part 3: Store the data into your vector and BM25 indexes
The final part of the index workflow involves storing the data chunks into indexes.
Before indexing the chunks, you can create and prepend situated contextual summaries for each chunk. These summaries can be created using generative AI models, paired with prompt caching to reduce the cost of creating these contextual summaries.
Again, we can use a custom task worker to generate these contextual summaries using your preferred LLM provider. This sample worker code example leverages Conductor’s SDK with Anthropic’s prompt caching feature:
from conductor.client.worker.worker_task import worker_task
DOCUMENT_CONTEXT_PROMPT = """
<document>
{doc_content}
</document>
"""
CHUNK_CONTEXT_PROMPT = """
Here is the chunk we want to situate within the whole document
<chunk>
{chunk_content}
</chunk>
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk.
Answer only with the succinct context and nothing else.
"""
@worker_task(task_definition_name='get-context')
def situate_context(doc: str, chunk: str) -> str:
response = client.beta.prompt_caching.messages.create(
model="claude-3-haiku-20240307",
max_tokens=1024,
temperature=0.0,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": DOCUMENT_CONTEXT_PROMPT.format(doc_content=doc),
"cache_control": {"type": "ephemeral"} #we will make use of prompt caching for the full documents
},
{
"type": "text",
"text": CHUNK_CONTEXT_PROMPT.format(chunk_content=chunk),
}
]
}
],
extra_headers={"anthropic-beta": "prompt-caching-2024-07-31"}
)
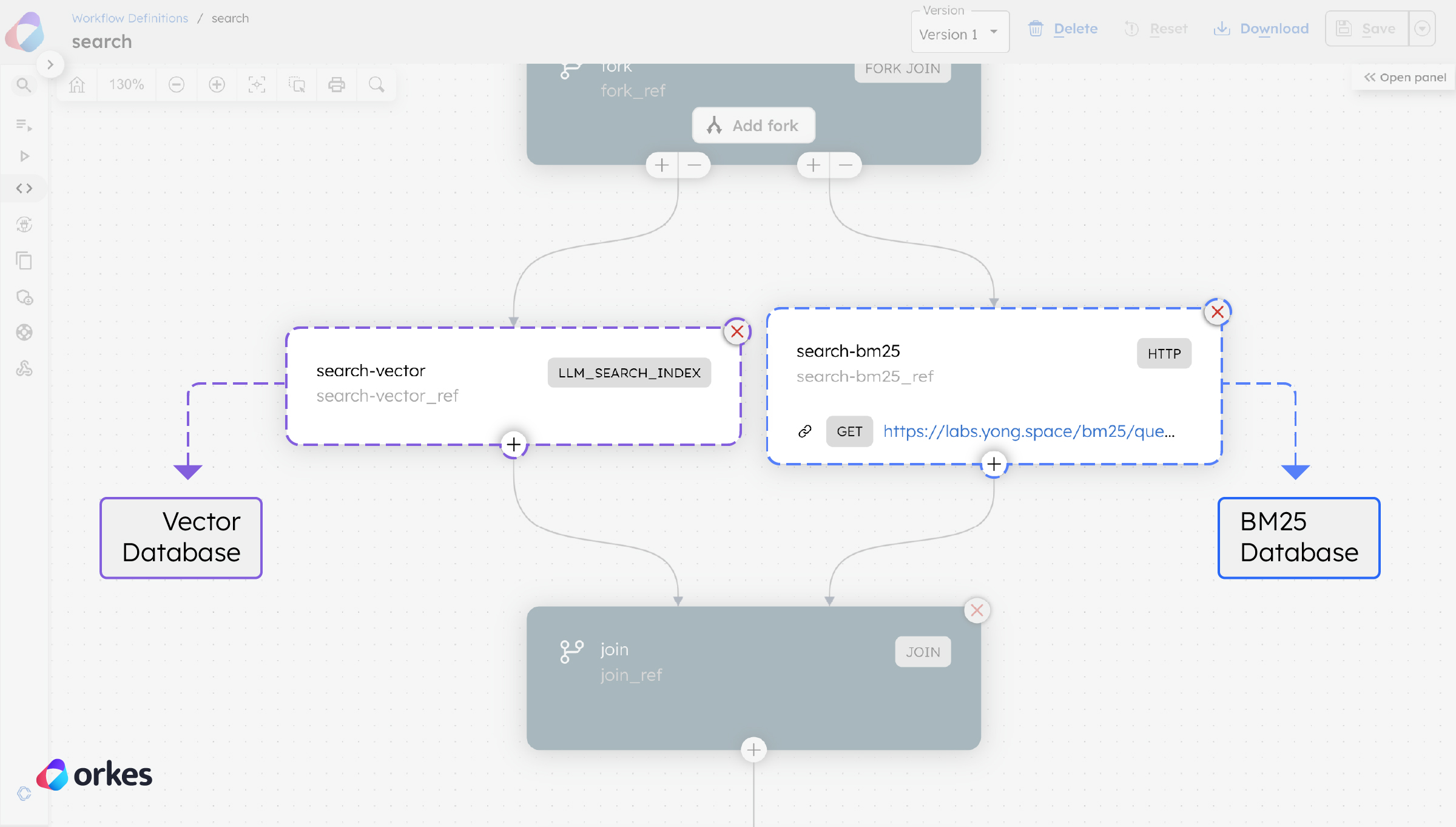
return responseOnce processed, we can finally index these chunks. Using a hybrid search approach means that the chunks must be indexed in a (i) vector database and (ii) BM25 index. With Orkes Conductor, we can easily use a Fork-Join operator to index the same chunk into both indexes simultaneously, speeding up the process.
Here, a pre-made Index Text task is used to store the chunks into a vector database, while an internal API is used to store the chunks into a BM25 database.
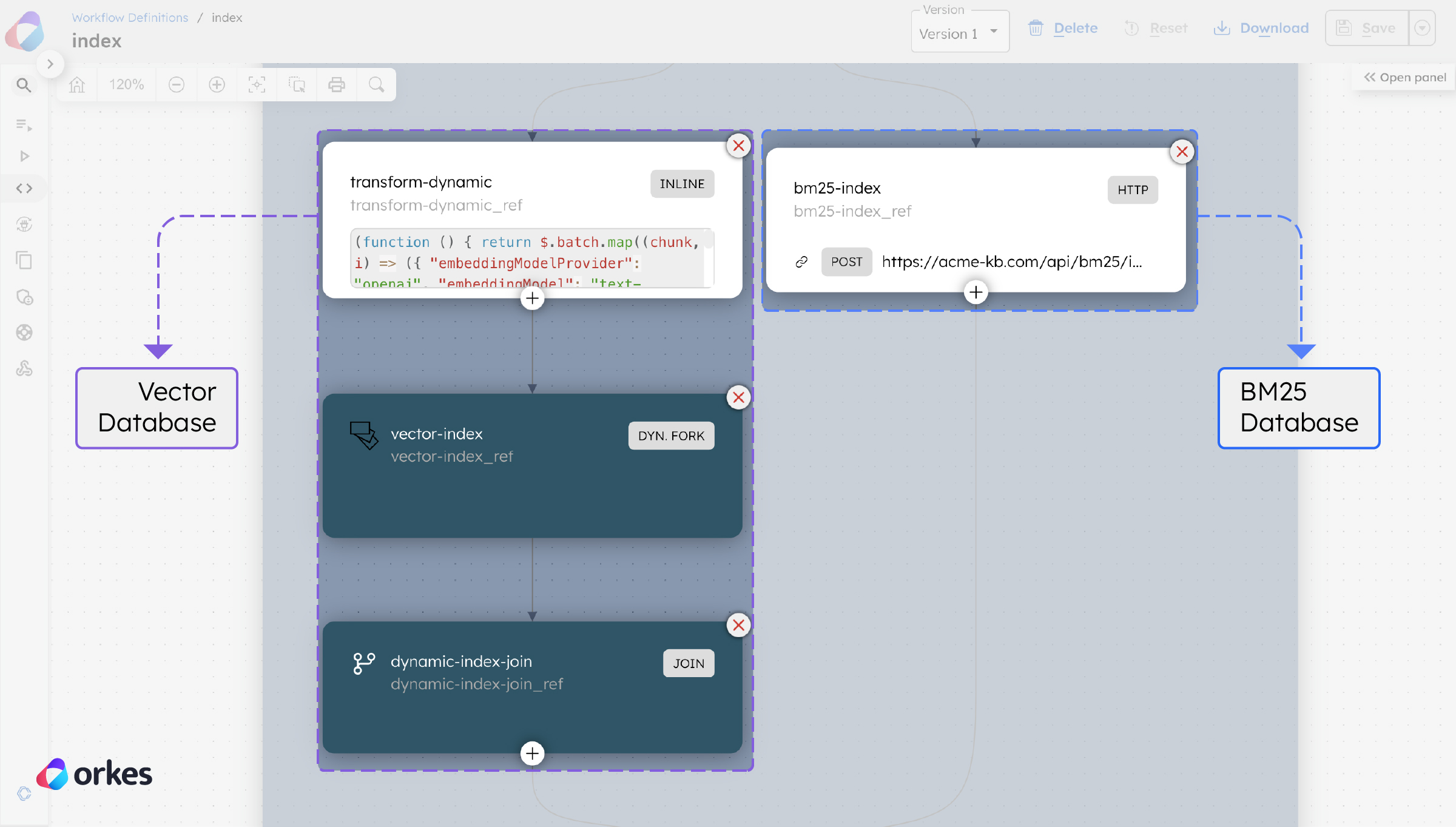
With that, the index workflow is completed. To build out your knowledge base, run the workflow to index your policy documents.
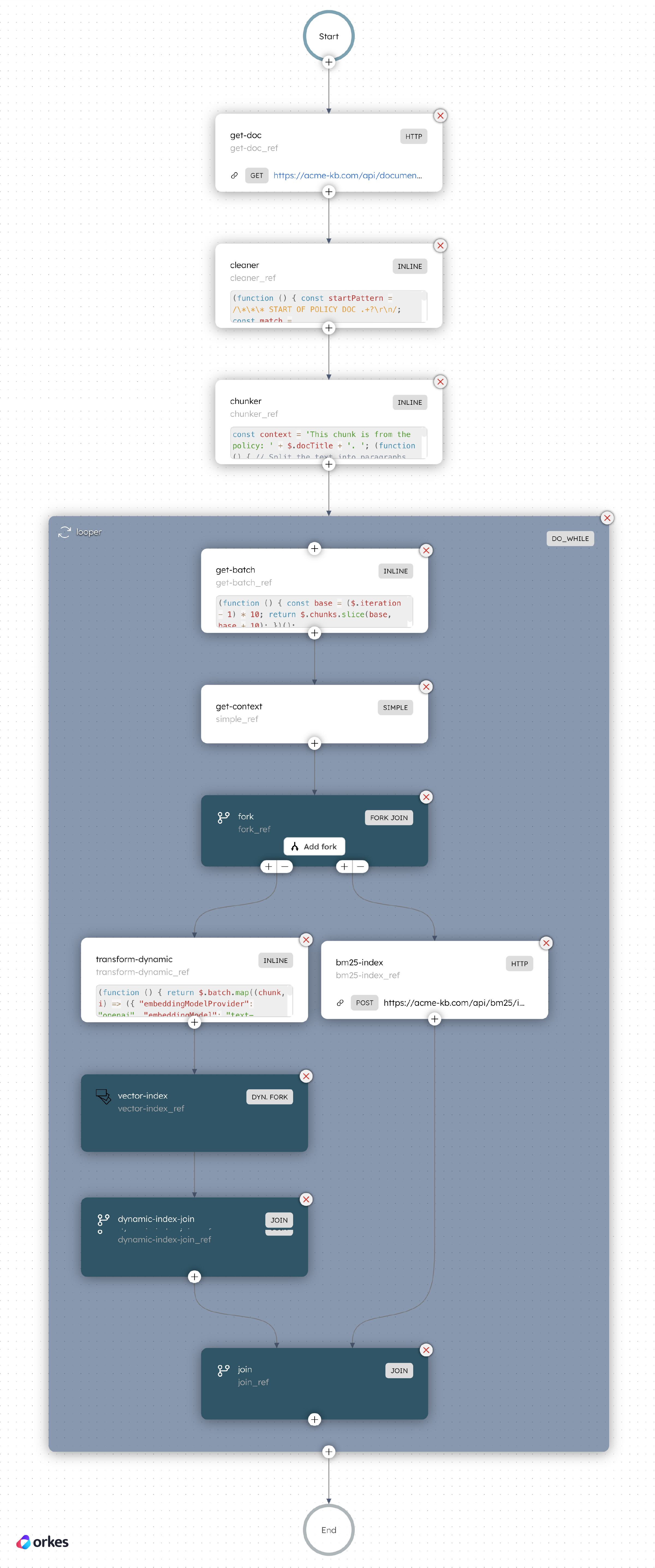
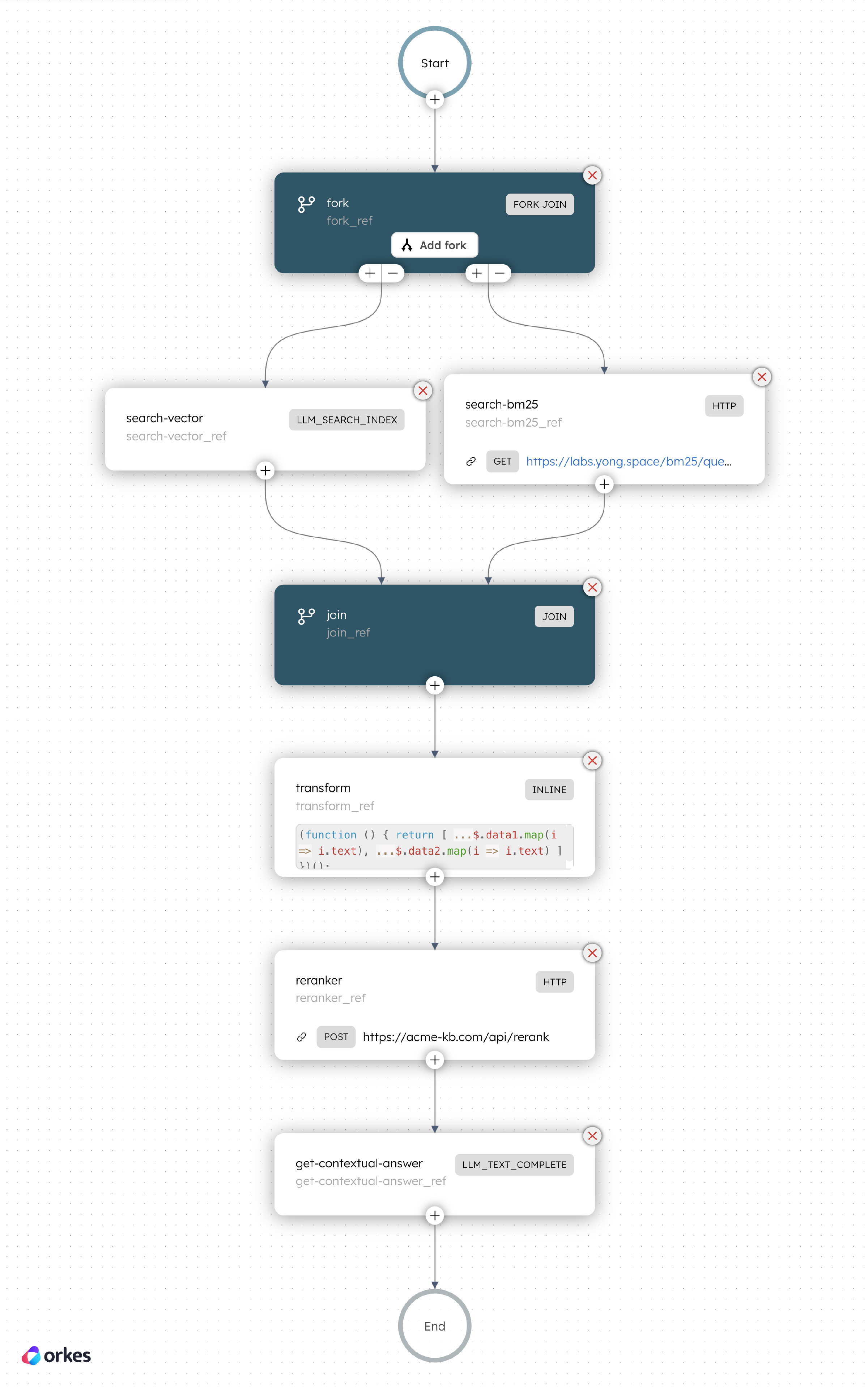
The search workflow retrieves relevant documents from the knowledge base and answers the user query. In production, a search workflow would include the following steps:
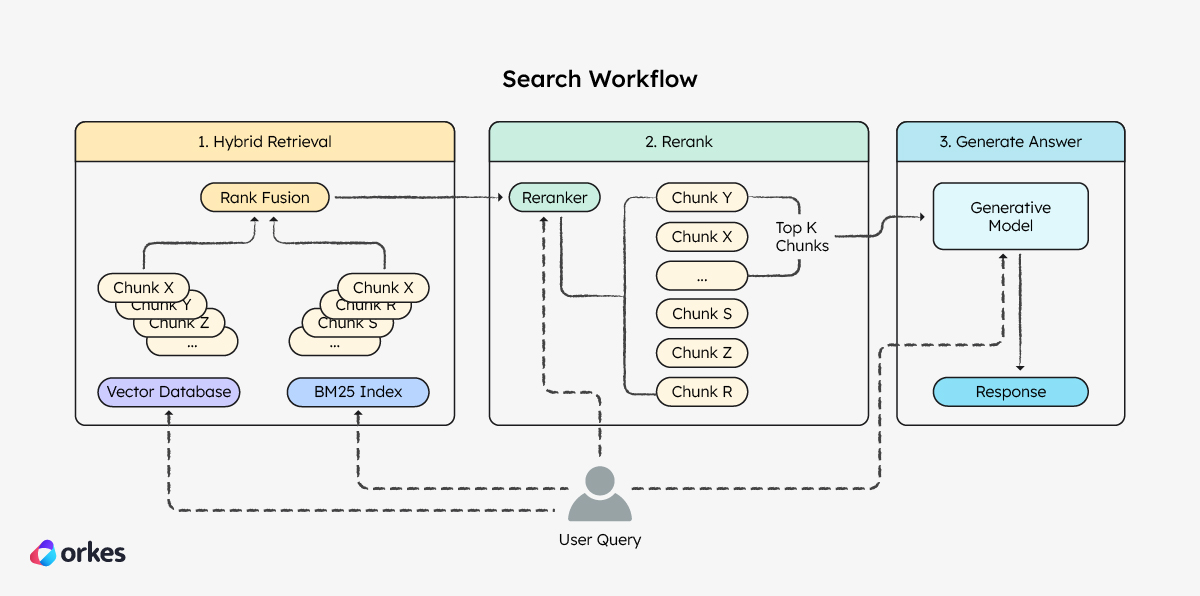
Part 1: Hybrid search
Since we are using a hybrid search approach, another Fork-Join operator is used to retrieve information from both indexes at once. Here, a pre-made Search Index task is used to retrieve from the vector database, while an HTTP task is used to call an internal API to the BM25 database.
Part 2: Rerank
Once the retrieval stage is completed, we can use a custom worker task to rerank the search results, by leveraging rerankers from providers like Cohere or Voyage AI. Here’s a sample code that uses Cohere’s reranker:
from conductor.client.worker.worker_task import worker_task
@worker_task(task_definition_name='reranker')
async def rerank(input: RerankInput, k: int = 10):
co = cohere.Client(os.getenv("COHERE_API_KEY"))
response = co.rerank(
model="rerank-english-v3.0",
query=input.query,
documents=input.data,
top_n=k
)
return [input.data[r.index] for r in response.results]Part 3: Generate answer
Finally, a built-in Text Complete task is used to interact with an LLM, which will generate the answer based on the top reranked information. Using Orkes Conductor to orchestrate the flow, you can easily integrate and interact with any LLM provider, from OpenAI and Anthropic to open-source models on HuggingFace.
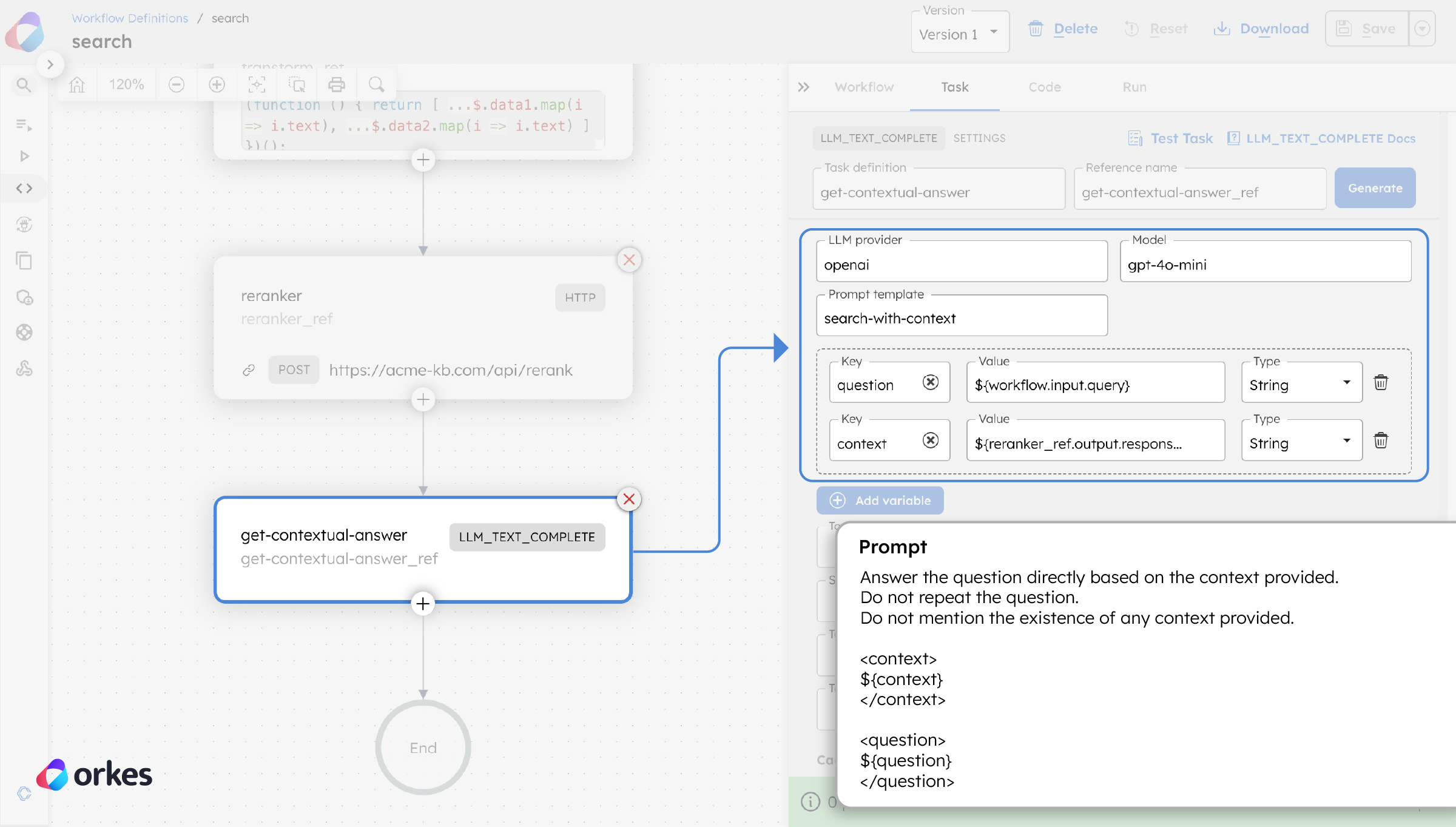
The Text Complete task sends the LLM a prompt template that is injected with the user query and the RAG-retrieved background knowledge. Orkes’ AI Prompt Studio feature makes it easy for developers to create, manage, and test these prompts, facilitating the prompt engineering process to enhance the LLM output.
Using some of the common prompt engineering tactics, here is an example prompt used in the RAG system:
Answer the question directly based on the context provided.
Do not repeat the question.
Do not mention the existence of any context provided.
<context>
${context}
</context>
<question>
${question}
</question>
Done! The search workflow is completed. Unlike the index workflow, the search workflow is used for your system runtime, when your users interact with your application to make queries.
Orchestration is an ideal design pattern to follow when it comes to building distributed systems that are composable, governable, and durable. As demonstrated in the RAG example above, the workflows can be easily composed from multiple services, packages, frameworks, and languages. As systems evolve and refine, developers can switch out tasks, use new frameworks, test different AI models, and implement best practices frictionlessly.
Furthermore, an orchestration platform like Orkes Conductor unlocks complete visibility into each step of the workflow, from its task status to its inputs/outputs and even completion duration. For complex AI-driven systems, where multiple layers of AI interactions take place under the hood, the ease of monitoring becomes even more vital for troubleshooting and optimizing these interactions.
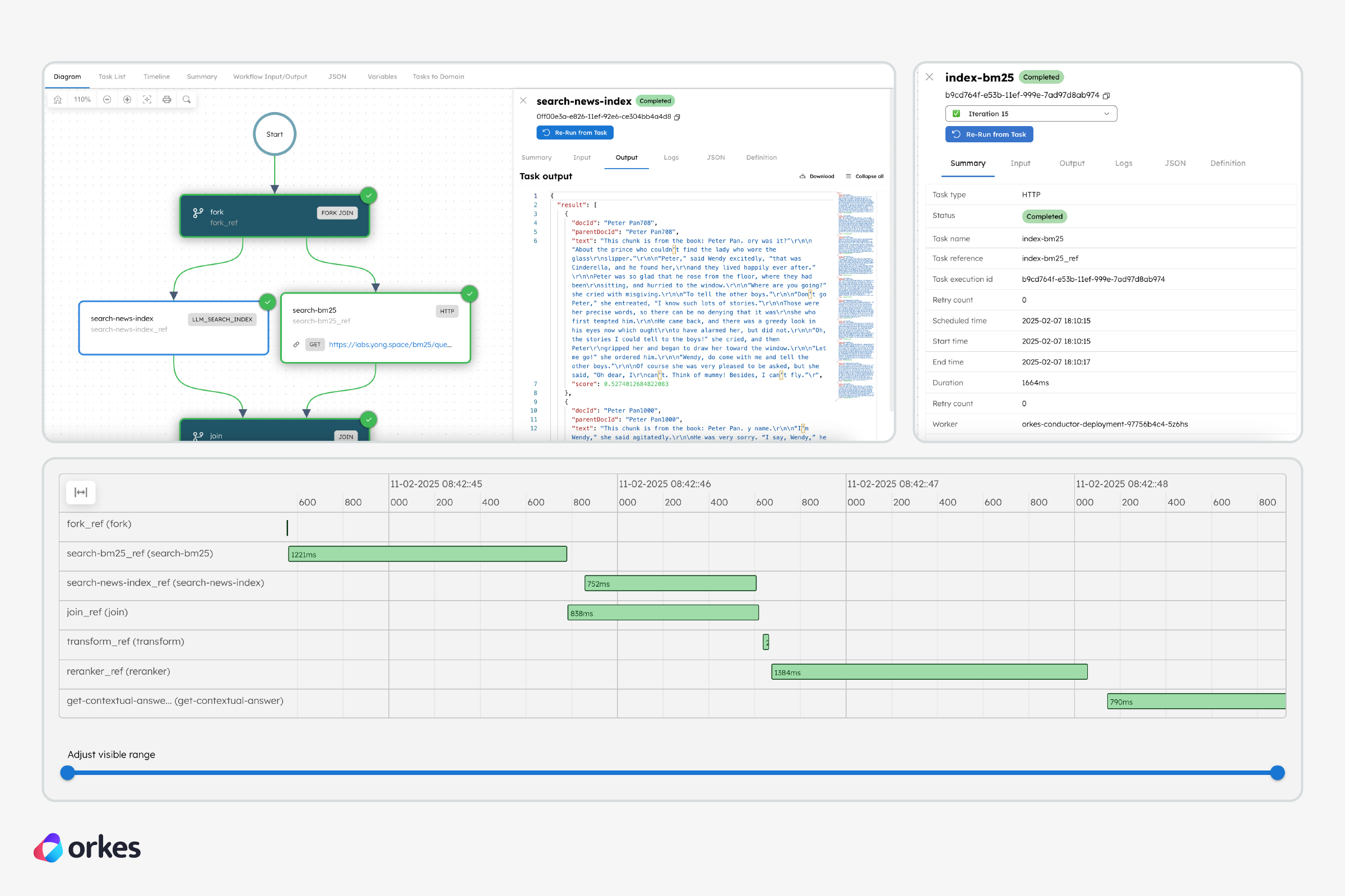
Most importantly, Conductor is hardened for failures, with comprehensive mechanisms for timeout, retry, idempotency, compensation flows, rate limits, and more. Such orchestration engines ensure the durable execution of any workflow, long-running or otherwise.
—
Conductor is an open-source orchestration platform used widely in mission-critical applications such as AI/LLM systems, event-driven systems, and microservice or API-first systems. Try it out using our online Developer Edition sandbox, or get a demo of Orkes Cloud, a fully managed and hosted Conductor service that can scale seamlessly to meet all enterprise needs.