LLM Search Index
The LLM Search Index task is used to search a vector database or repository of vector embeddings of already processed and indexed documents to get the closest match. This task is typically used in scenarios where you need to retrieve the data stored in a database using a natural language query.
The LLM Search Index task takes a query, which can be a question, statement, or request made in natural language. This query is processed to generate a vector representation, which is then used to search the vector database. The task returns a list of documents with vectors similar to the query vector, providing the closest matches based on the degree of similarity.
- Integrate the required AI model with Orkes Conductor.
- Integrate the required vector database with Orkes Conductor.
Task parameters
Configure these parameters for the LLM Search Index task.
| Parameter | Description | Required/ Optional |
|---|---|---|
| inputParameters.vectorDB | The vector database to retrieve the data. Note: If you haven’t configured the vector database on your Orkes Conductor cluster, navigate to the Integrations tab and configure your required provider. | Required. |
| inputParameters.index | The index in your vector database to search for relevant embeddings. The terminology of the index field varies depending on the integration:
| Required. |
| inputParameters.namespace | Namespaces are separate isolated environments within the database to manage and organize vector data effectively. Enter the namespace the task will utilize. The usage and terminology of the namespace field vary depending on the integration:
| Required. |
| inputParameters.embeddingModelProvider | The LLM provider for the embeddings. Note: If you haven’t configured your AI/LLM provider on your Orkes Conductor cluster, navigate to the Integrations tab and configure your required provider. | Required. |
| inputParameters.embeddingModel | The embedding model provided by the selected LLM provider. | Required. |
| inputParameters.query | The search query. A query typically refers to a question, statement, or request made in natural language that is used to search, retrieve, or manipulate data stored in a database. | Required. |
| inputParameters.maxResults | The maximum number of results to return. Provide a non-zero integer between 1 and 10000. | Required. |
| inputParameters.dimensions | The size of the vector, which is the number of elements in the vector. | Optional. |
The following are generic configuration parameters that can be applied to the task and are not specific to the LLM Search Index task.
Caching parameters
You can cache the task outputs using the following parameters. Refer to Caching Task Outputs for a full guide.
| Parameter | Description | Required/ Optional |
|---|---|---|
| cacheConfig.ttlInSecond | The time to live in seconds, which is the duration for the output to be cached. | Required if using cacheConfig. |
| cacheConfig.key | The cache key is a unique identifier for the cached output and must be constructed exclusively from the task’s input parameters. It can be a string concatenation that contains the task’s input keys, such as ${uri}-${method} or re_${uri}_${method}. | Required if using cacheConfig. |
Other generic parameters
Here are other parameters for configuring the task behavior.
| Parameter | Description | Required/ Optional |
|---|---|---|
| optional | Whether the task is optional. If set to true, any task failure is ignored, and the workflow continues with the task status updated to COMPLETED_WITH_ERRORS. However, the task must reach a terminal state. If the task remains incomplete, the workflow waits until it reaches a terminal state before proceeding. | Optional. |
Task configuration
This is the task configuration for an LLM Search Index task.
{
"name": "llm_search_index",
"taskReferenceName": "llm_search_index_ref",
"inputParameters": {
"vectorDB": "Pinecone",
"index": "doc",
"namespace": "docs",
"embeddingModelProvider": "openAI",
"embeddingModel": "text-embedding-3-large",
"query": "${workflow.input.query}",
"maxResults": 10,
"dimensions": 3024
},
"type": "LLM_SEARCH_INDEX"
}
Task output
The LLM Search Index task will return the following parameters.
| Parameter | Description |
|---|---|
| result | A JSON array containing the results of the query. |
| score | Represents a value quantifying the degree of likeness between a specific item and a query vector, facilitating ranking and ordering of results. Higher scores denote stronger relevance to the query vector. |
| metadata | An object containing additional metadata related to the retrieved document. |
| docId | The unique identifier of the queried document. |
| parentDocId | An identifier that denotes a parent document in hierarchical or relational data structures. |
| text | The actual content retrieved. |
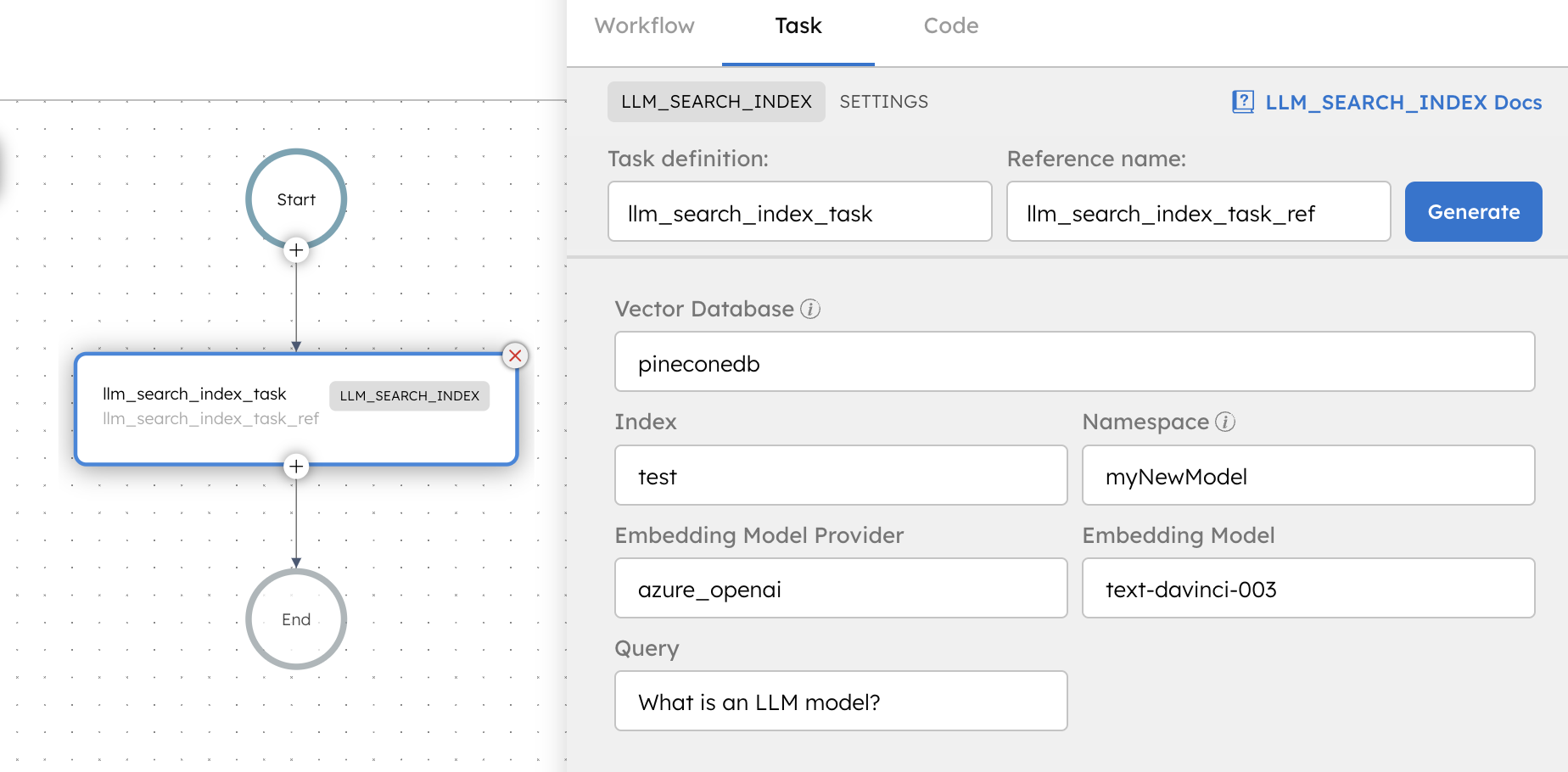
Adding an LLM Search Index task in UI
To add an LLM Search Index task:
- In your workflow, select the (+) icon and add an LLM Search Index task.
- In Vector Database Configuration, select the Vector database, Index, and Namespace to retrieve the embeddings.
- In Embedding Model, select the Embedding model provider, and Embedding model to generate the embeddings.
- In Search Parameter, enter the Query, Max Results, and Dimensions.
Examples
Here are some examples for using the LLM Search Index task.
Using an LLM Search Index task in a workflow
See an example of building a document retrieval workflow using Orkes Conductor.