Handling Failures
Orkes Conductor automatically handles transient workflow and task failures without the need to write custom code. Various failure-handling configurations can be set ahead of time, which will take effect during execution.
For tasks, you can configure the following resilience parameters in its task definition:
- Retries
- Timeouts
For workflows, you can configure the following resilience parameters in its workflow definition:
- Timeouts
- Compensation flows (known as failure workflow in Conductor)
To deal with workflow failures post-execution, refer to Debugging Workflow Executions.
Message delivery guarantees
Conductor guarantees at least once message delivery, meaning all messages are persistent and will be delivered to task workers one or more times. In the event of failure, the message will be delivered more than once. This semantics ensures that:
- If a workflow has started, it will run to completion as long as all its tasks are completed.
- If a task worker fails due to restarts, crashes, or other issues, the message will be redelivered to another worker node that is alive and responding.
Task retries
Automatic retries are a key strategy for handling transient task failures. If a task fails to complete, the Conductor server will make it available for polling again after a specified duration.
Retry configuration
You can configure retry behavior for tasks in its task definition. The parameters for defining a task’s retry behavior are:
- Retry count
- Retry delay seconds
- Retry logic
- Backoff scale factor
| Parameter | Description | Required/ Optional |
|---|---|---|
| retryCount | The number of retry attempts if the task fails. Default value is 3. | Optional. |
| retryDelaySeconds | The time (in seconds) to wait before each retry attempt. This provides time for the task service to recover from any transient failure before it is retried. Default value is 60. | Optional. |
| retryLogic | The policy that determines the retry mechanism for the tasks. Supported values:
| Optional. |
| backoffScaleFactor | The value multiplied with retryDelaySecondsto determine the interval for retry. Default value is 1. | Optional. |
Example
// task definition
{
"name": "someTaskDefName",
...
"retryCount": 3,
"retryLogic": "FIXED|EXPONENTIAL_BACKOFF|LINEAR_BACKOFF",
"retryDelaySeconds": 1,
"backoffScaleFactor": 1
}
Example retry behavior
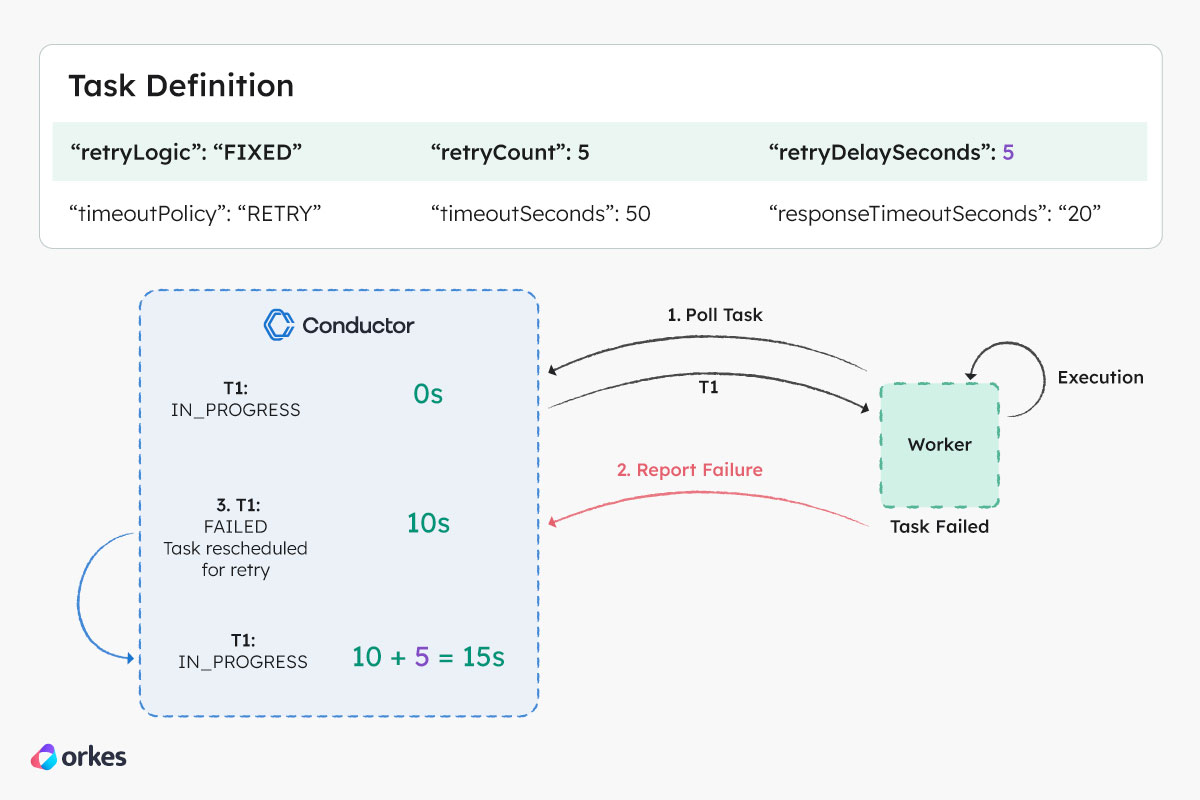
Based on the retry configuration in the above figure, the following sequence of events will occur in the event of a retry:
- Worker (W1) polls the Conductor server for task T1 and receives the task.
- After processing the task, the worker determines that the task execution is a failure and reports to the server with a
FAILEDstatus after 10 seconds. - The server will persist this failed execution of T1.
- A new task execution T1 is created and scheduled for polling. Based on the retry configuration, the task will be available for polling after 5 seconds.
Task timeouts
A task timeout can occur if:
- There are no workers available for a given task type. This could be due to longer-than-expected system downtime or a system misconfiguration.
- The worker receives the message but dies before fully processing the task, so the task never completes.
- The worker has completed the task but could not communicate with the Conductor server due to network failures, the server being down, or other issues.
Timeout configuration
You can configure timeout behavior for tasks in its task definition to handle the various abovementioned cases. The parameters for a task’s timeout behavior are:
- Response timeout seconds
- Timeout seconds
- Poll timeout seconds
- Timeout policy
| Parameter | Description | Required/ Optional |
|---|---|---|
| responseTimeoutSeconds | The maximum duration in seconds that a worker has to respond to the server with a status update before it gets marked as TIMED_OUT. When configured with a value > 0, Conductor will wait for the worker to return a status update, starting from when the task was picked up. If a task requires more time to complete, the worker can respond with the IN_PROGRESS status. Default value is 600. | Optional. |
| timeoutSeconds | The maximum duration in seconds for the task to reach a terminal state before it gets marked as TIMED_OUT. When configured with a value > 0, Conductor will wait for the task to complete, starting from when the task was picked up. Useful for governing the overall SLA for completion. Default value is 3600. | Optional. |
| pollTimeoutSeconds | The maximum duration in seconds that a worker has to poll a task before it gets marked as TIMED_OUT. When configured with a value > 0, Conductor will wait for the task to be picked up by a worker. Useful for detecting a backlogged task queue with insufficient workers. Default value is 3600. | Optional. |
| timeoutPolicy | The policy for handling timeout. Supported values:
| Optional. |
To configure tasks that never timeout, set timeoutSeconds and pollTimeoutSeconds to 0.
Example
// task definition
{
"name": "someTaskDefName",
...
"retryCount": 3,
"retryLogic": "FIXED|EXPONENTIAL_BACKOFF|LINEAR_BACKOFF",
"retryDelaySeconds": 1,
"backoffScaleFactor": 1
}
Example timeout behavior
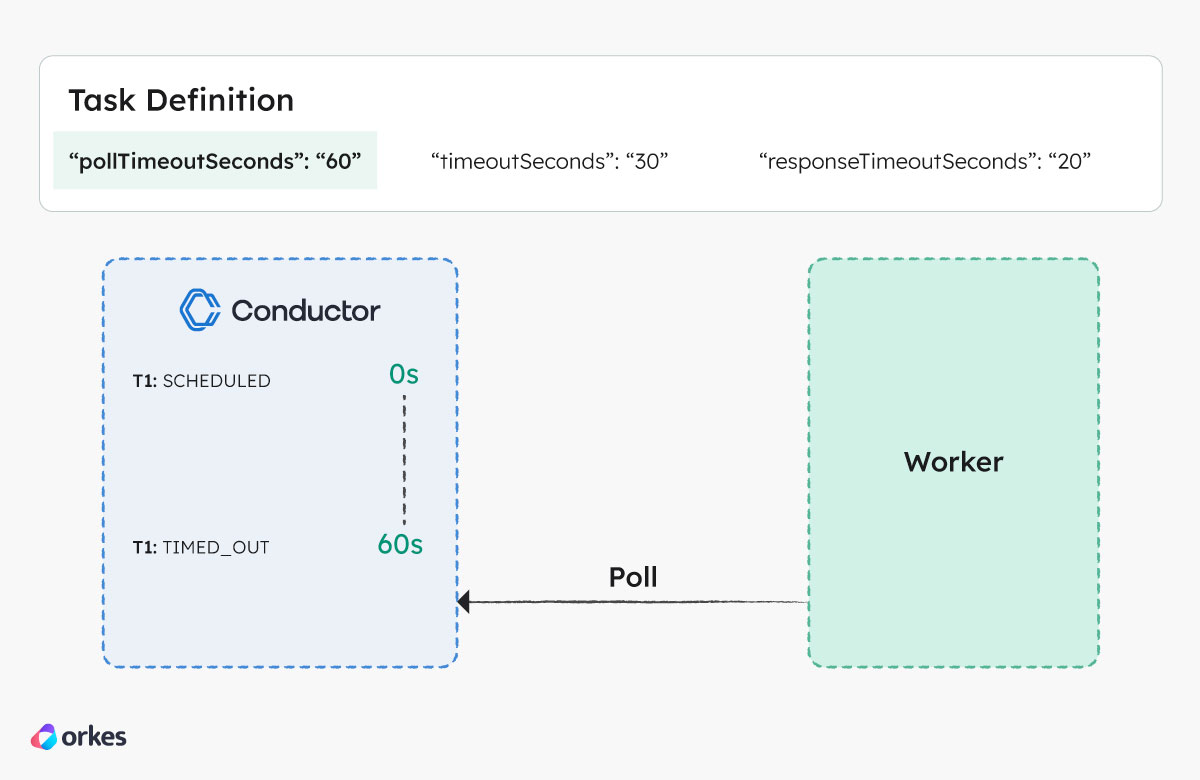
Poll timeout
In the figure below, task T1 isn’t polled by the worker within 60 seconds, so Conductor marks it as TIMED_OUT.
Response timeout
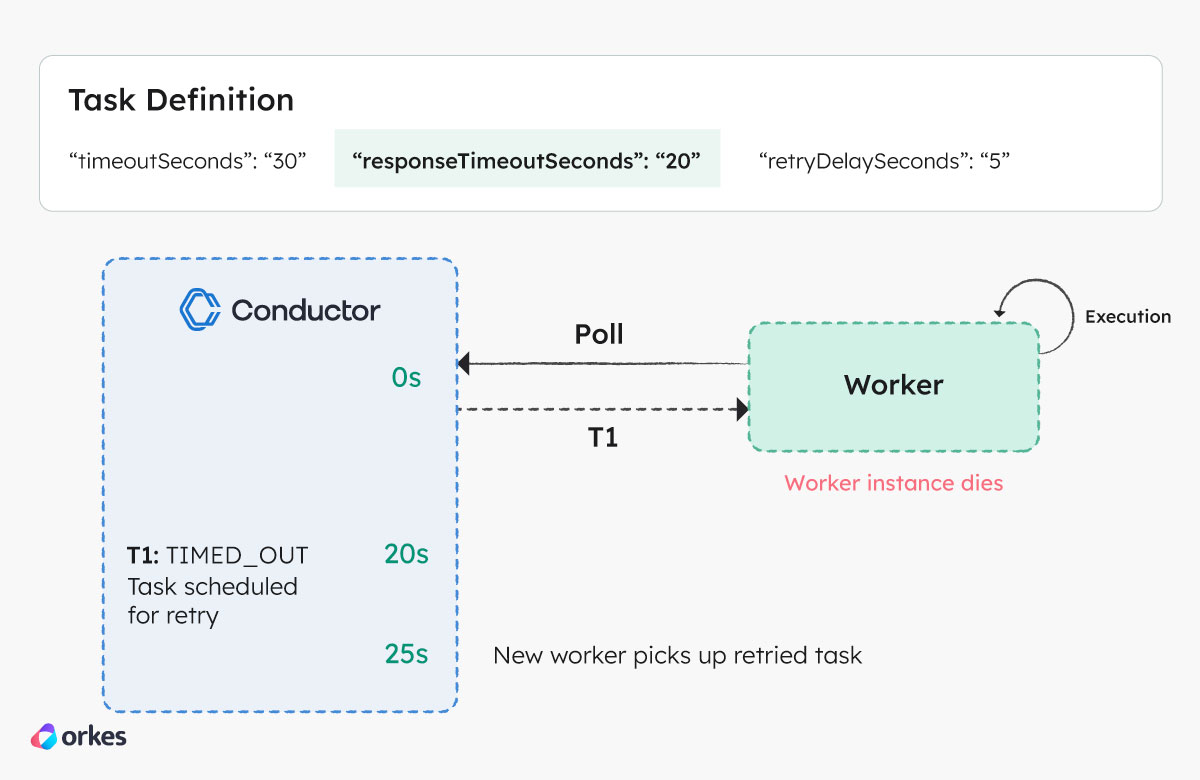
Based on the timeout configuration in the above figure, the following sequence of events will occur in the event of a delayed worker response:
- At 0 seconds, the worker polls the Conductor server for task T1 and receives it. T1 is marked as IN_PROGRESS by the server.
- The worker starts processing the task, but the worker instance dies during the execution.
- At 20 seconds (T1’s
responseTimeoutSeconds), the server marks T1 as TIMED_OUT since the worker has not updated the task within the configured duration. - A new instance of task T1 is scheduled based on the retry configuration.
- At 25 seconds, the retried instance of T1 is available for polling after the
retryDelaySecondsset to 5 has elapsed.
Timeout
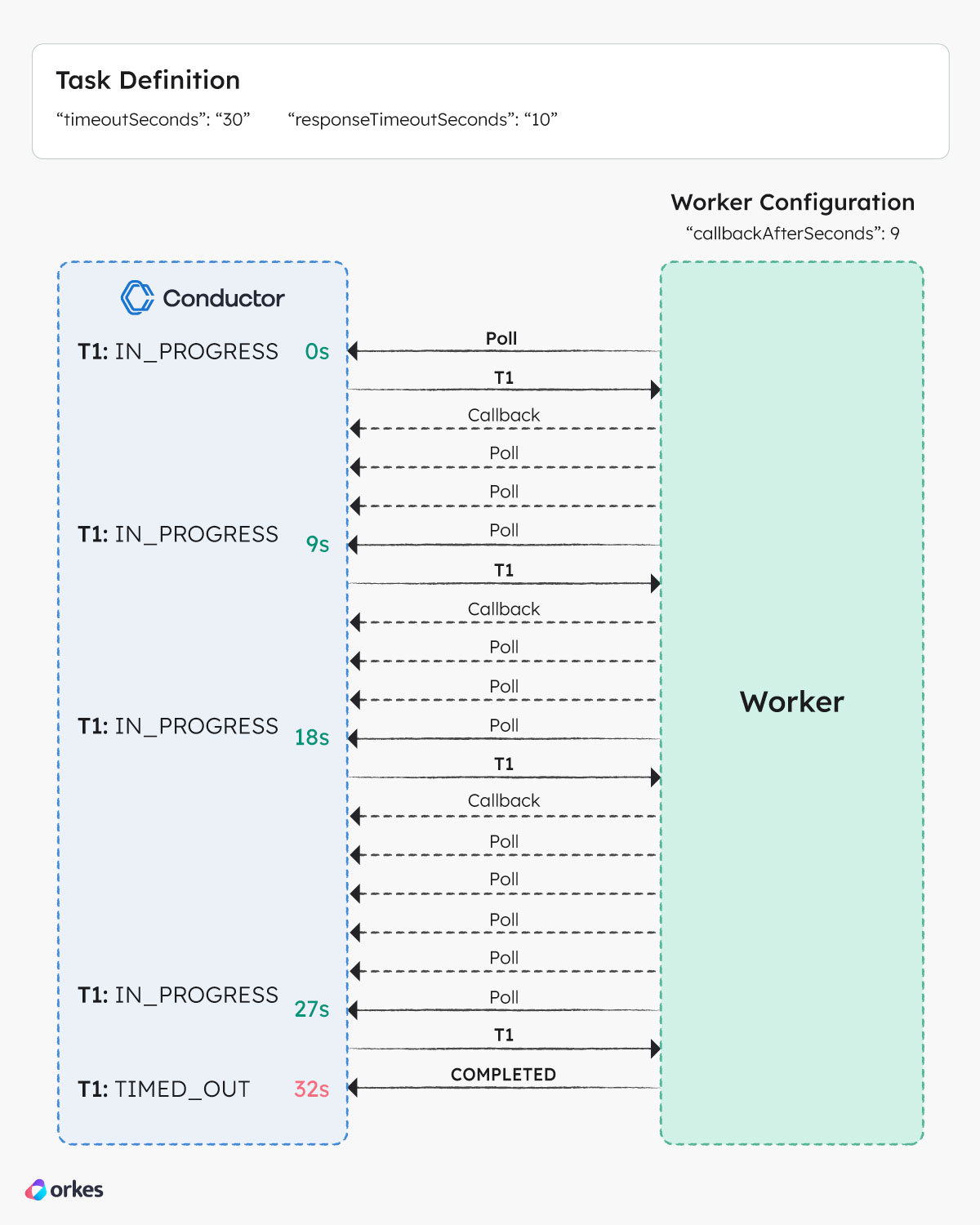
Based on the timeout configuration in the above figure, the following sequence of events will occur when a task cannot be completed within the given duration:
- At 0 seconds, a worker polls the Conductor server for task T1 and receives the task. T1 is marked as IN_PROGRESS by the server.
- The worker starts processing the task, but is unable to complete it within the response timeout. The worker updates the server with T1 set to an IN_PROGRESS status and a callback of 9 seconds (part of worker configuration).
- The server puts T1 back in the queue but makes it invisible and the worker continues to poll for the task but does not receive T1 for 9 seconds.
- After 9 seconds, the worker receives T1 from the server but is still unable to finish processing the task. As such, the worker updates the server again with a callback of 9 seconds.
- The same cycle repeats for the next few seconds.
- At 30 seconds (T1 timeout), the server marks T1 as TIMED_OUT because it is not in a terminal state after first being moved to IN_PROGRESS status. The server schedules a new task based on the retry count.
- At 32 seconds, the worker finishes processing T1 and updates the server with a COMPLETED status. The server ignores this update since T1 has already been moved to a terminal status (TIMED_OUT).
Workflow timeouts
A workflow can be configured to timeout in situations where:
- The workflow has been running longer than expected and has not been completed within the defined time frame.
- An external dependency required by the workflow is unresponsive or taking too long to respond.
- Business logic requires the workflows to be completed within a strict time limit to maintain efficiency.
Timeout configuration
You can configure the timeout behavior for the workflow using its workflow definition. The parameters for a workflow’s timeout behavior are:
- Timeout seconds
- Timeout policy
| Parameter | Description | Required/Optional |
|---|---|---|
| timeoutSeconds | The timeout, in seconds, after which the workflow will be set as TIMED_OUT if it hasn't reached a terminal state. Set to 0 for no timeouts. | Required. |
| timeoutPolicy | The policy for handling workflow timeout. Supported values:
| Required. |
Example
// workflow definition
{
"name": "someWorkflow",
"timeoutPolicy": "TIME_OUT_WF",
"timeoutSeconds": 1800
}
Workflow compensation flows
A compensation flow can be configured to take place when a workflow reaches a non-successful terminal state such as FAILED, TIMED_OUT, or TERMINATED. Known as a failure workflow in Conductor, this failure workflow must be created in Conductor and added to the main workflow definition.
When triggered, the failure workflow receives the following details as input:
workflowId: The ID of the failed workflow.reason: The reason for failure.failureStatus: The terminal status of the failed workflow (FAILED, TIMED_OUT, or TERMINATED).failureTaskId: The ID of the task that caused the failure, if applicable.failedWorkflow: The complete workflow object, including all task details.
This enables you to implement compensating logic to handle the failure.
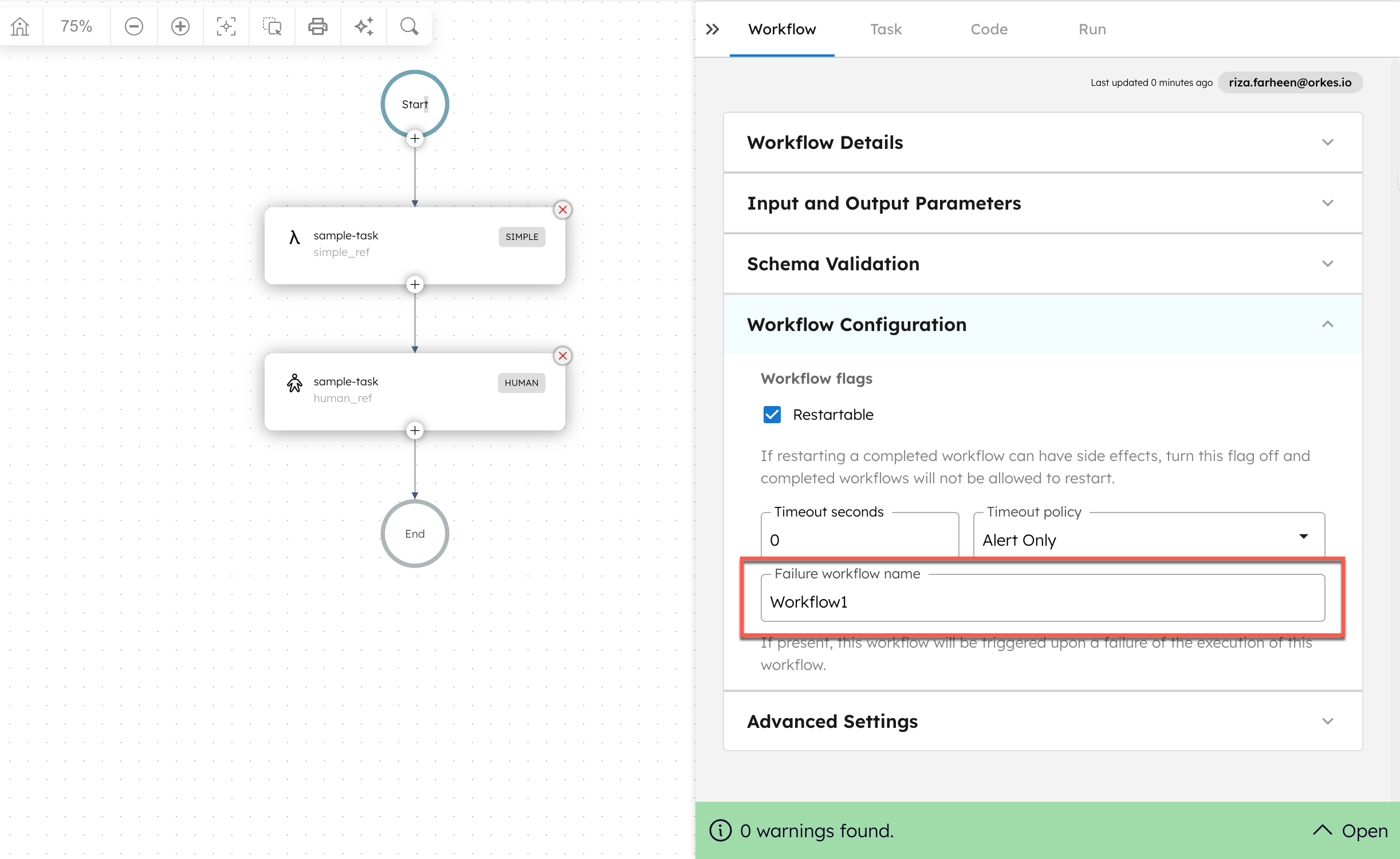
Setting a failure workflow
You can set a failure workflow for a workflow in its workflow definition. Before setting the failure workflow, ensure it has been created in Conductor.
To set a failure workflow:
- Go to Definitions > Workflow.
- Select the workflow that you want to add a failure workflow to.
- In the Workflow tab on the right, scroll down to Execution Parameters > Failure/Compensation > Failure/Compensation workflow name, and select the failure workflow from the dropdown box.
- Select Save > Confirm save.
Example
// workflow definition
{
...
"failureWorkflow": "<name of the workflow that will run upon failure>"
}