Build a Document Classification Workflow with Orkes Conductor
This tutorial demonstrates how to build a document classification workflow using AI tasks in Orkes Conductor. The workflow processes a text-based PDF and classifies it into predefined categories such as W2, driver’s license, paystub, employment verification letter, or mortgage application.
In this tutorial, you will:
- Integrate the required AI models with your cluster. OpenAI will be used in this tutorial.
- Create a prompt to classify the document content.
- Create a workflow to classify text-based PDFs.
- Run the workflow and verify classification results.
To follow along, ensure you have access to the free Orkes Developer Edition.
The document classification workflow
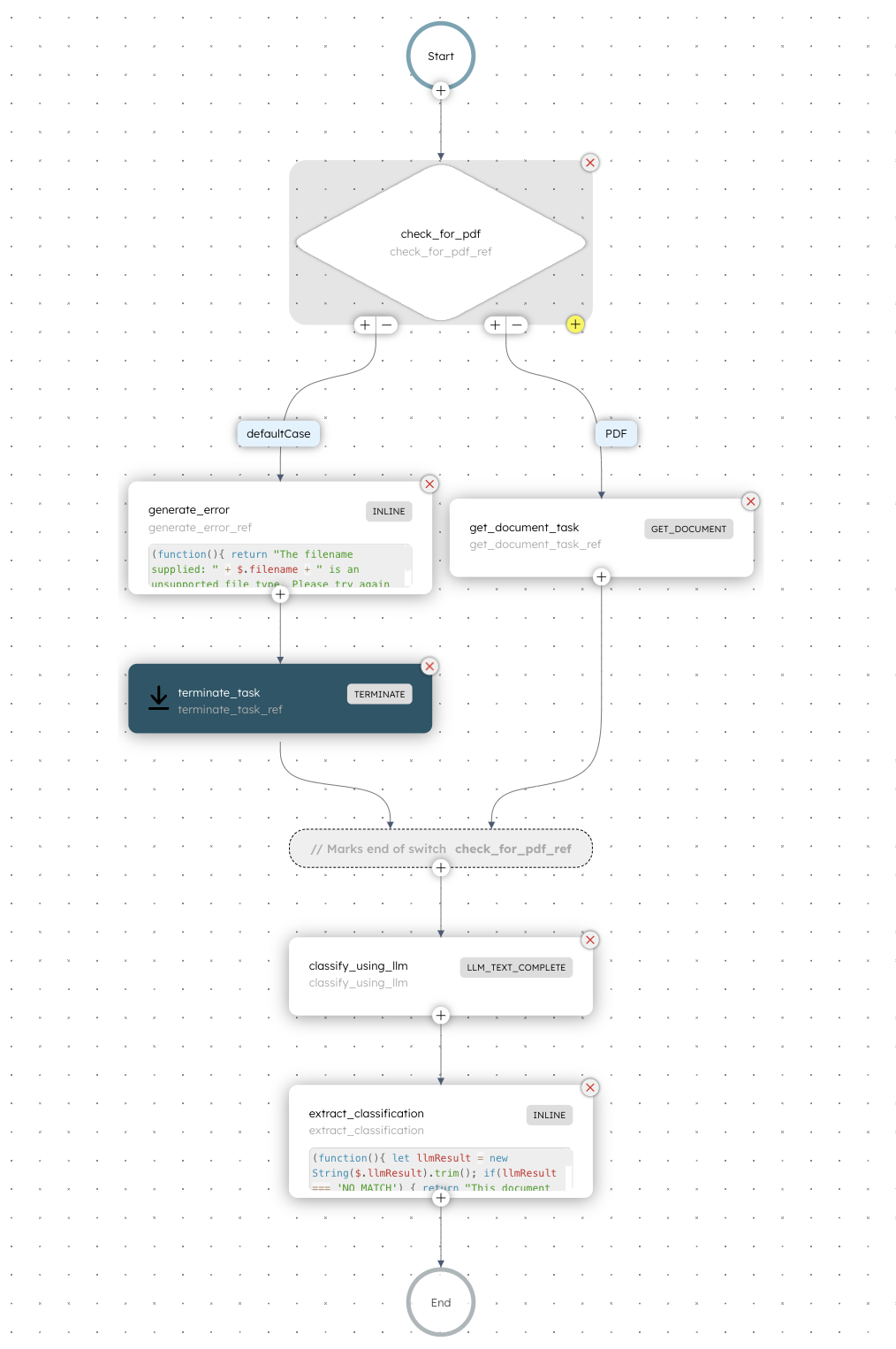
Here is the document classification workflow that you’ll build in this tutorial:
Workflow input:
- document_url: The HTTP URL of the document file to classify. The workflow supports PDFs that contain scanned images, such as scanned passports or IDs. Text is extracted using OCR before classification.
Workflow logic:
- The workflow begins with a Switch task that checks whether the input URL ends with .pdf using an ECMAScript expression.
- If the input file is not a PDF:
- An Inline task generates an error message about the unsupported file type.
- A Terminate task terminates the workflow with an error message on the unsupported file type.
- If the input file is a PDF:
- An LLM Get Document task retrieves the content of the PDF document.
- An LLM Text Complete task classifies the document as a W2, driver's license, paystub, employment verification letter, or mortgage application. This task determines the file type using an AI prompt in Conductor.
- An Inline task that extracts and formats the classification result based on the previous LLM Text Complete task’s output. It also returns a message indicating the category to which the document type has been classified.
Step 1: Integrate the model provider for document classification
To begin with, we will use OpenAI’s gpt-4o model to service the document classification workflow. Add an OpenAI integration to your Conductor cluster, then add the required gpt-4o model.
Add OpenAI integration
To add an OpenAI integration:
- Get your OpenAI API Key from OpenAI’s platform.
- Go to Integrations from the left navigation menu on your Conductor cluster.
- Select + New integration.
- Create the integration by providing the following mandatory parameters:
- Integration name: “openAI”
- API Key: <YOUR_OPENAI_API_KEY>
- Description: “OpenAI Integration”
- Ensure that the Active toggle is switched on, then select Save.
The OpenAI integration is added. The next step is to add a specific model.
Add gpt-4o models
To add the gpt-4o model:
- In the Integrations page, select the + button next to your newly-created OpenAI integration.
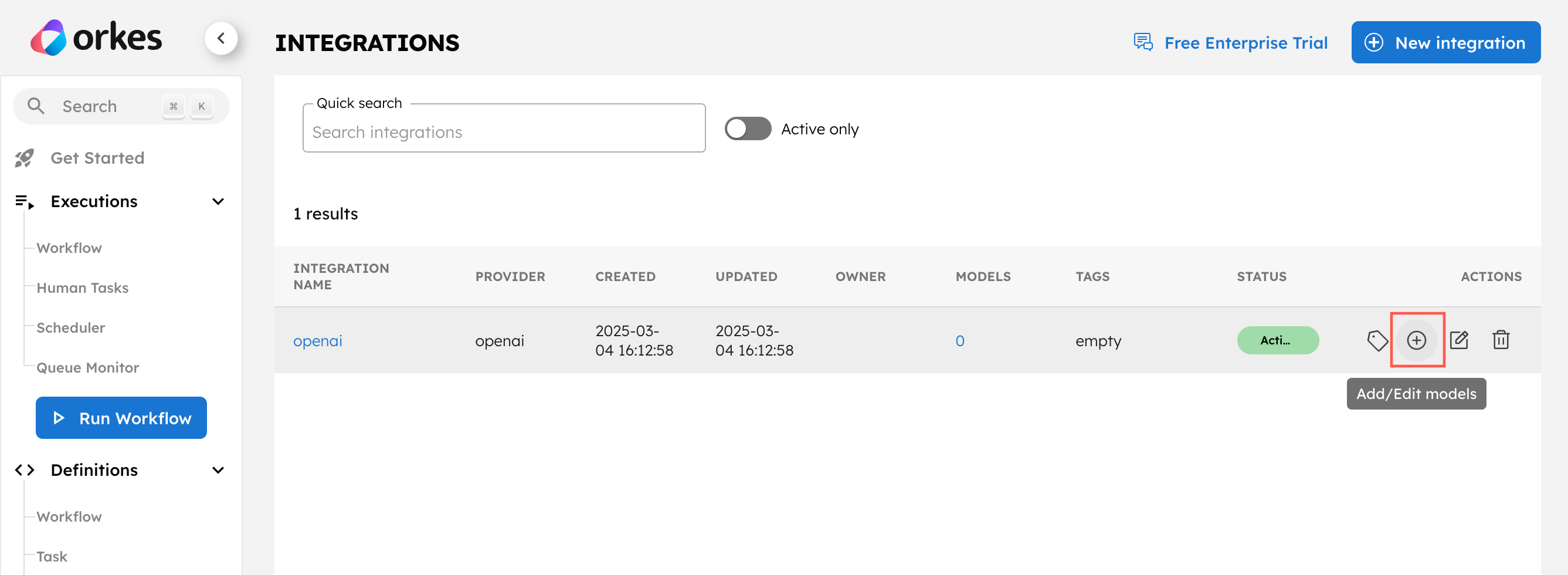
- Select + New model.
- Enter the Model Name as “gpt-4o” and an optional description like “OpenAI’s gpt-4o model”.
- Ensure that the Active toggle is switched on and select Save.
The integration is now ready to use. The next step is creating an AI prompt template that classifies the documents using this integration.
Step 2: Create the AI prompt for document classification
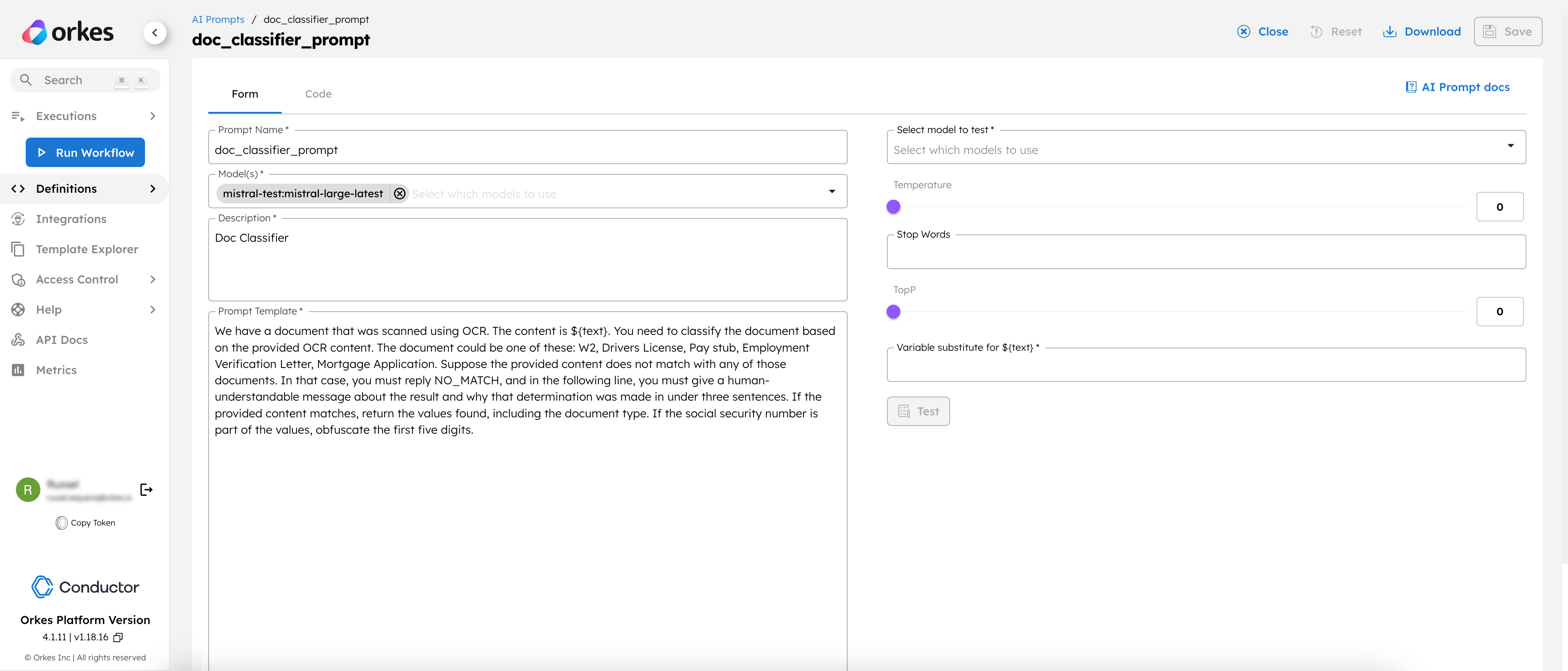
To create an AI prompt:
- Go to Definitions > AI Prompts from the left navigation menu on your Conductor cluster.
- Select + Add AI prompt.
- In Prompt Name, enter a unique name for your prompt, such as doc_classifier_prompt.
- In Model(s), select the integration you added in the previous step. The UI drop-down lists the integration along with the model names. Make sure to choose the right one.
- Enter a Description of what the prompt does. For example: “The AI prompt to classify documents.”
- In Prompt Template, enter your prompt, which will classify the document into appropriate categories. For example:
We have a document that was scanned using OCR. The content is ${text}. You need to classify the document based on the provided OCR content. The document could be one of these: W2, Drivers License, Pay stub, Employment Verification Letter, or Mortgage Application. Suppose the provided content does not match with any of those documents. In that case, you must reply NO_MATCH, and in the following line, you must give a human-understandable message about the result and why that determination was made in under three sentences. If the provided content matches, return the values found, including the document type. If the social security number is part of the values, obfuscate the first five digits.
Here, we have defined ${text} as a variable derived from the previous tasks' output. This will become clearer once we incorporate this prompt into the workflow.
- Select Save > Confirm save.
This saves your prompt.
Step 3: Create the document classification workflow
With the integration and prompt ready, let’s create the workflow.
To create a workflow:
- Go to Definitions > Workflow and select + Define workflow.
- In the Code tab, enter the following JSON:
{
"name": "document_classifier",
"description": "LLM Powered PDF Document Classification Workflow",
"version": 1,
"tasks": [
{
"name": "check_for_pdf",
"taskReferenceName": "check_for_pdf_ref",
"inputParameters": {
"url": "${workflow.input.document_url}"
},
"type": "SWITCH",
"decisionCases": {
"PDF": [
{
"name": "get_document_task",
"taskReferenceName": "get_document_task_ref",
"inputParameters": {
"url": "${workflow.input.document_url}",
"mediaType": "application/pdf"
},
"type": "GET_DOCUMENT"
}
]
},
"defaultCase": [
{
"name": "generate_error",
"taskReferenceName": "generate_error_ref",
"inputParameters": {
"expression": "(function(){ \n\n return \"The filename supplied: \" + $.filename + \" is an unsupported file type. Please try again with a .pdf file\";\n})();",
"evaluatorType": "graaljs",
"filename": "${workflow.input.document_url}"
},
"type": "INLINE"
},
{
"name": "terminate_task",
"taskReferenceName": "terminate_task_ref",
"inputParameters": {
"terminationStatus": "TERMINATED",
"terminationReason": "Unsupported file type",
"workflowOutput": {
"result": "${generate_error_ref.output}"
}
},
"type": "TERMINATE"
}
],
"evaluatorType": "graaljs",
"expression": "$.url.toLowerCase().trim().endsWith(\"pdf\") ? \"PDF\" : \"NOT_SUPPORTED\";"
},
{
"name": "classify_using_llm",
"taskReferenceName": "classify_using_llm",
"inputParameters": {
"promptName": "<YOUR-PROMPT>",
"promptVariables": {
"text": "${get_document_task_ref.output.result}"
},
"llmProvider": "<YOUR-LLM-PROVIDER>",
"model": "<YOUR-LLM-MODEL>"
},
"type": "LLM_TEXT_COMPLETE"
},
{
"name": "extract_classification",
"taskReferenceName": "extract_classification",
"inputParameters": {
"expression": "(function(){ \n let llmResult = new String($.llmResult).trim();\n if(llmResult === 'NO_MATCH') {\n return \"This document couldn't be classified by the LLM\";\n }\n return \"LLM classified this document as: \" + llmResult;\n})();",
"evaluatorType": "graaljs",
"llmResult": "${classify_using_llm.output.result}"
},
"type": "INLINE"
}
],
"inputParameters": [
"document_url"
],
"schemaVersion": 2
}
- Select Save > Confirm.
- After saving, update the LLM Text Complete task with your actual values:
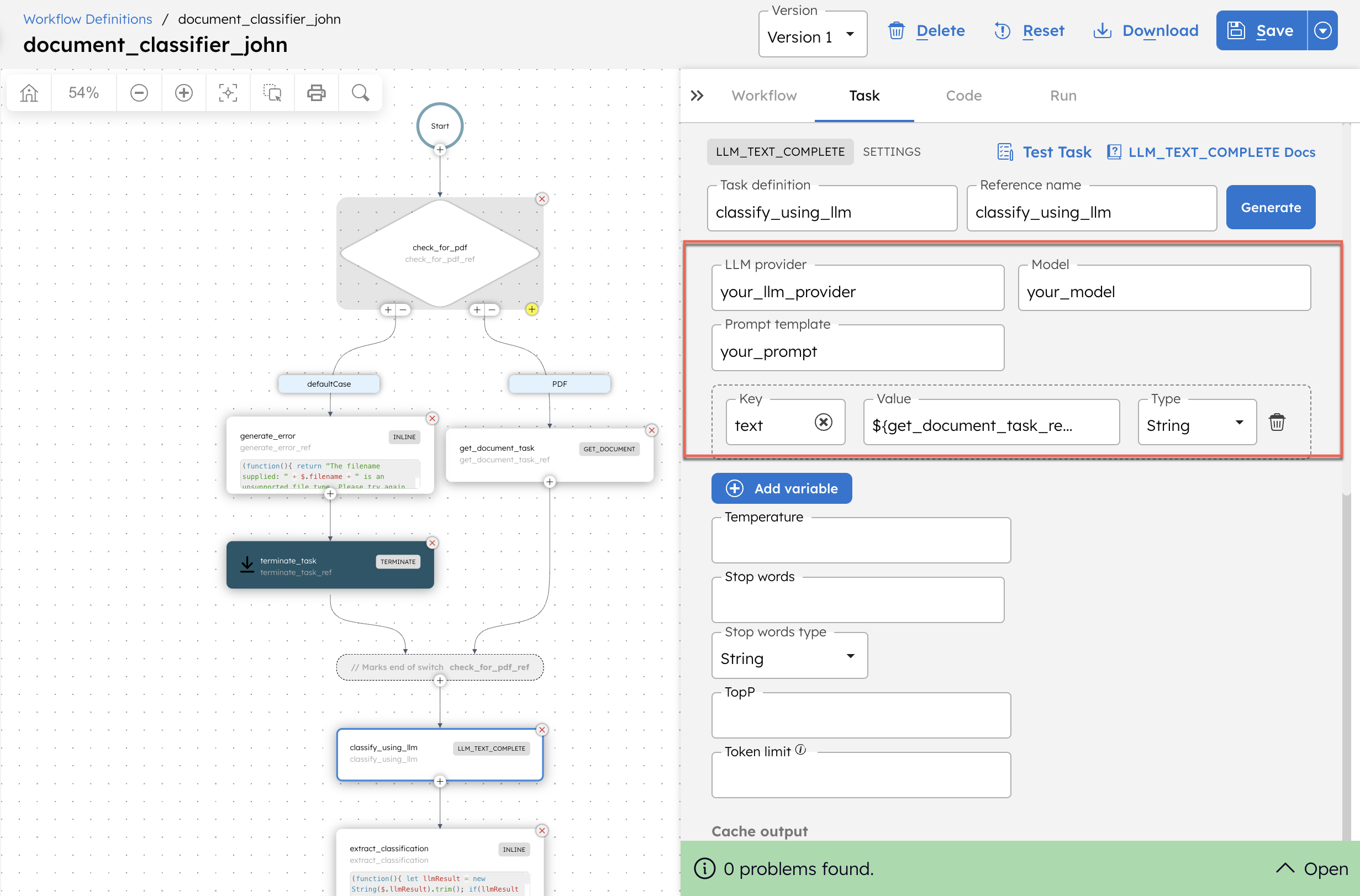
- In LLM provider, replace <YOUR-LLM-PROVIDER> with your OpenAI integration name created in Step 1.
- In Model, replace <YOUR-LLM-MODEL> with your integrated model in Step 1.
- In Prompt template, replace <YOUR-PROMPT> with your prompt created in Step 2.
- Make sure to update the promptVariable text parameter as
${get_document_task_ref.output.result}. This is the output of get_document_task, which retrieves the content of the PDF document.
- Select Save > Confirm.
Step 4: Run the workflow
To run the workflow using Conductor UI:
- From your workflow definition, go to the Run tab.
- Enter the Input Params.
// example input params
{
"document_url": "<YOUR-DOCUMENT-URL-IN-PDF-FORMAT>"
}
The document must be accessible via an HTTP URL and end with .pdf.
- Select Execute.
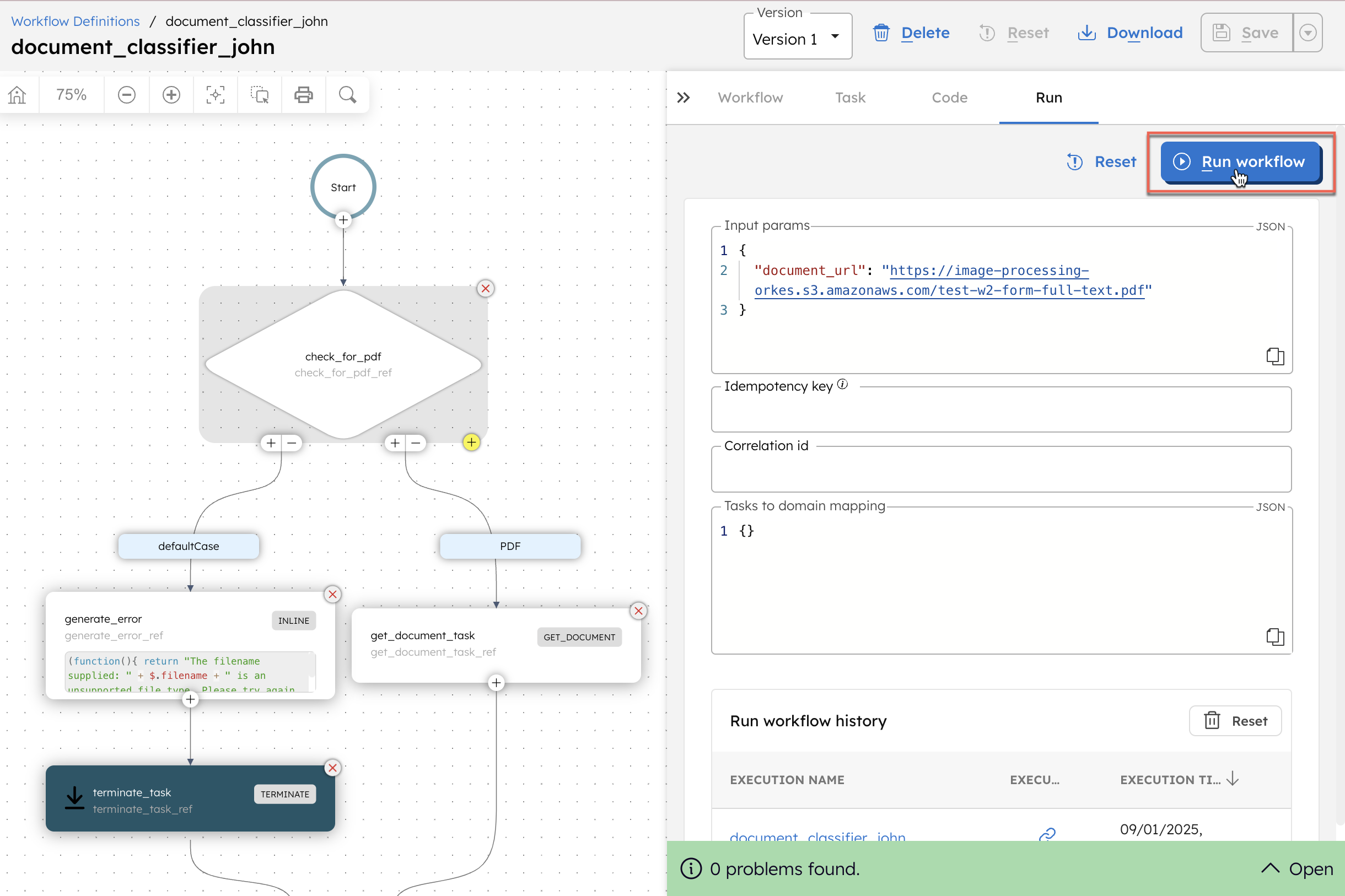
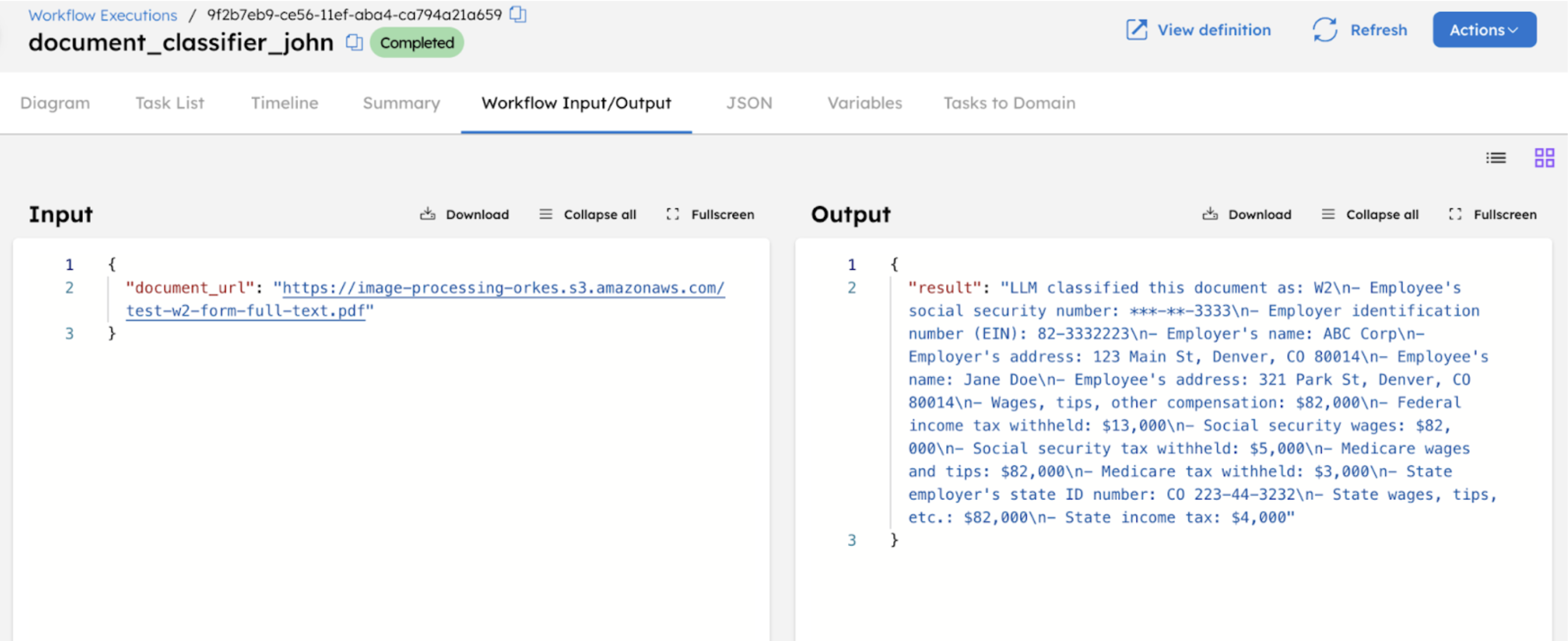
The workflow output will provide the category to which the document is classified. Here is an example output based on a W2 document passed as the input: