ANNOUNCEMENTS PRODUCT
Harness the Power of Gen AI in Your Applications - Introducing AI Orchestration and Human Tasks in Orkes Conductor

Dilip Lukose
CPO
Last updated: November 2, 2023
November 2, 2023
12 min read








Join thousands of developers building the future with Orkes.
Innovations in the Generative AI landscape are unfolding at a phenomenal pace. Powerful large language models (LLMs), both open source and proprietary, are now available through providers such as Open AI, Hugging Face, Azure, GCP, AWS, and more that open new avenues for technology to impact our lives.
This is exciting news for developers who are building applications of all kinds - they now have the power of language models to help them innovate and modernize their applications. We hear this excitement every day when we talk to our community, customers, and partners.
However, there are big gaps that exist when it comes to generative AI powering of applications that are top of the mind for developers:
These questions essentially boil down to one fundamental question that is in the minds of many developers today:
We are committed to our community and customers to provide them with the best application platform, Orkes Conductor, where your workflows can be orchestrated no matter what language or framework is used to build the application’s components. We are excited to add to this the foundational capabilities that can be used to orchestrate interactions with language models, vector databases, and human users in an application’s logic graph. And as with the rest of our enterprise-grade platform, each component is built with security and observability at its core.
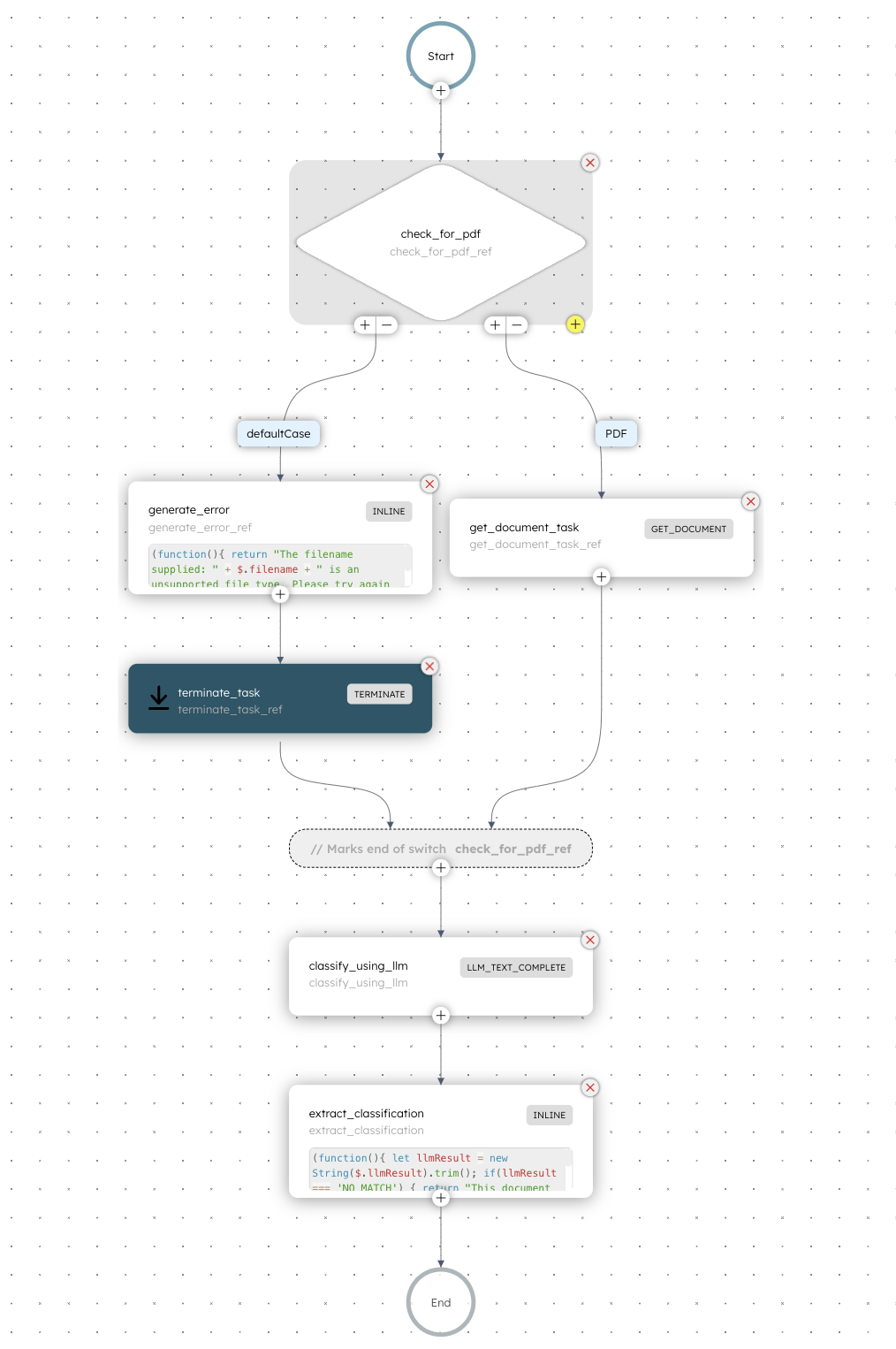
Specifically, we are launching the below features. We also have an AI orchestration quickstart guide that shows how to use these new features to easily build a Document Classifier application.
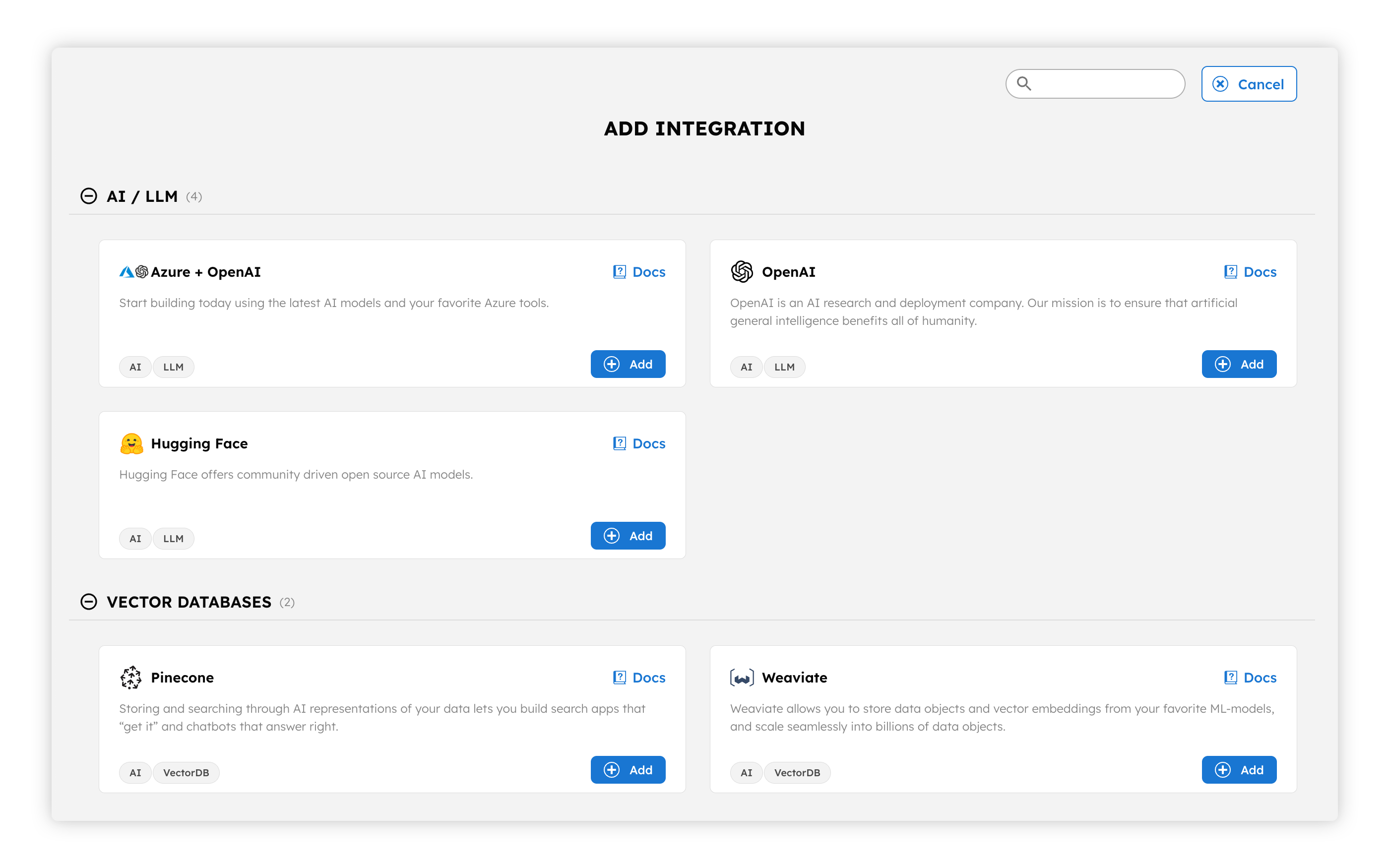
Orkes Conductor now supports integrating with our growing list of model providers, such as Open AI, Hugging Face, Azure Open AI, Vertex AI and the models they host. These can then be natively used as building blocks in your application, whether to do a text-complete task in response to a prompt or to generate embeddings for text or documents that can then be stored in a vector database. Similarly, Orkes Conductor now supports integrating with vector database providers such as Pinecone and Weaviate to not only store embeddings but also to search a vector space for similar embeddings when a particular input is provided as an embedding, a string of text, or a document.
Any integrations added to your Orkes Conductor cluster can be managed through the granular role-based access control capabilities Orkes provides. If you have a model that should only be used by your finance team, or if you have a vector database that has sensitive company data stored as embeddings, you can decide which teams have access to those and what type of access they have.
Building the right prompts, testing them out, tuning them iteratively, and protecting them as a core intellectual property of an organization - these are some requests we’ve received from our customers when it comes to leveraging LLMs. We listened, and Orkes Conductor now has a full suite of prompt building, testing, and management capabilities. Dedicated prompt engineers or developers who are also building the prompts that gen-AI power their applications can now create and test those prompts in a highly visual way in Orkes Conductor.
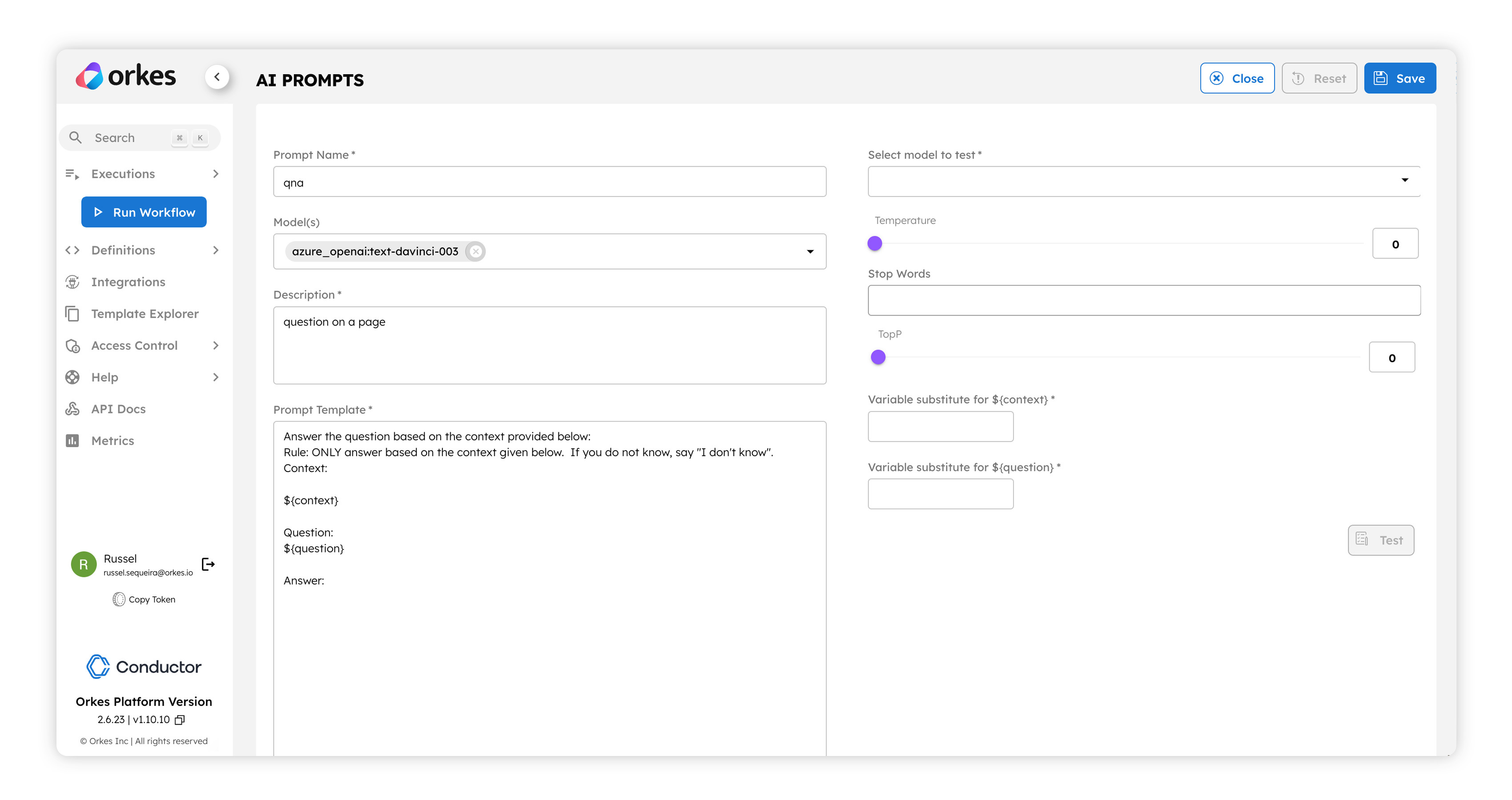
One key feature of these prompts is that they can be templated by adding variables, which can then be filled in at runtime with the data coming through your application graph. For example., if you are building an application (or modernizing an existing one) that is analyzing your company’s sales data, you could have a prompt with variables country and month-year, as shown in the example below.
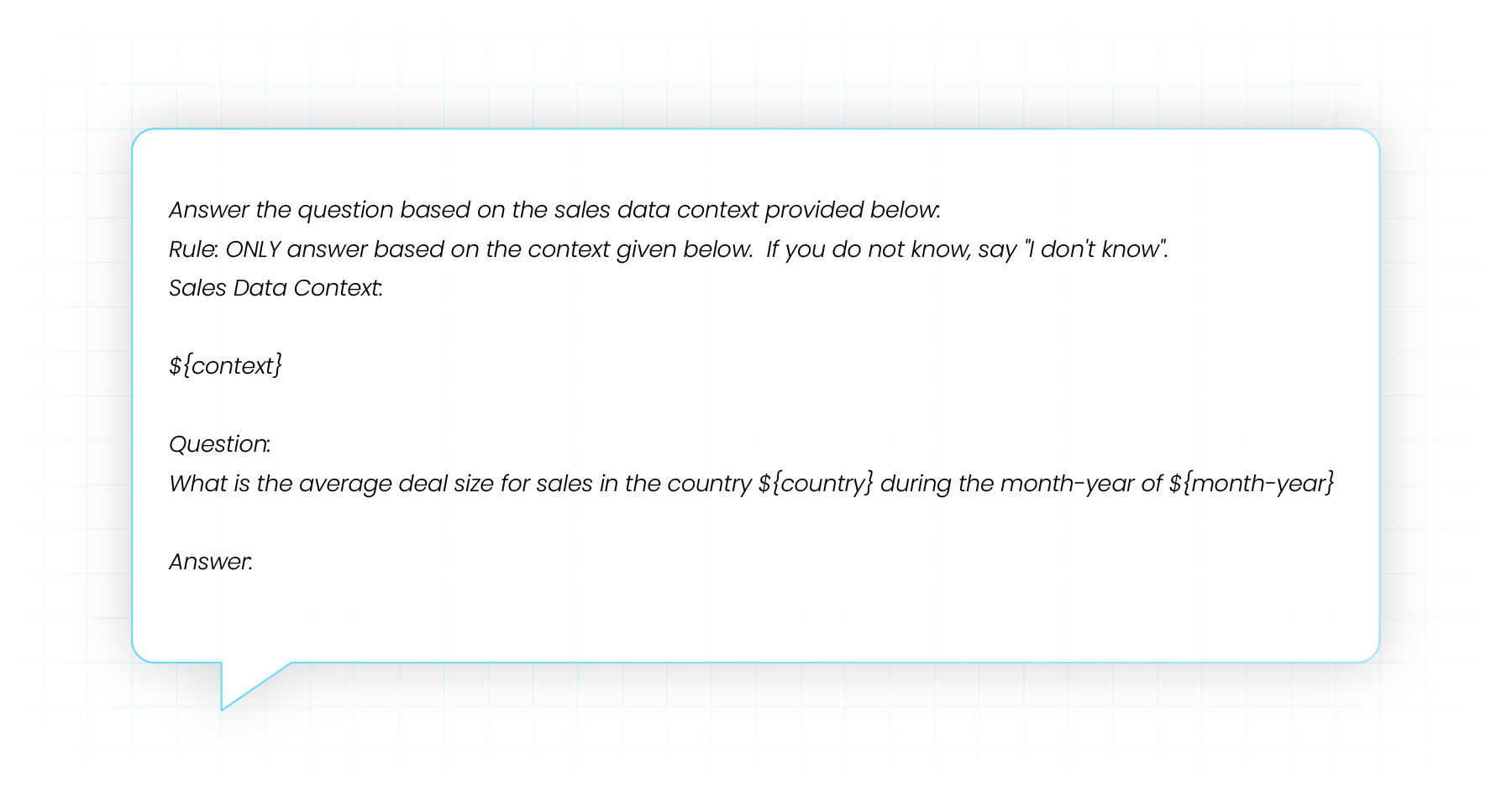
These variables that were defined during the definition time of the prompt will be replaced at runtime with actual values that are part of a specific execution instance of the workflow where this prompt is used to convey a text-complete request to a model. For example, the workflow might be kicked off to analyze the sales data for Australia for June-2023 - the prompt template’s variables will be assigned these values, resulting in a fully formed prompt that can then be sent to a model.
When you define a prompt, you can also decide which models that are integrated with the Orkes Conductor cluster can be used with it. For example, suppose you are defining a prompt that has sensitive information. In that case, you can choose to have it used only with models from providers that guarantee data protection (and not with a publicly available model). You can take this security aspect of prompt management even further when it comes to sharing and re-usability. Every prompt can be access controlled so that the prompt creator (or an admin) can decide which teams have access to this prompt and what level of access they have (e.g., Team A can execute the prompt in their workflows, but they cannot update or delete the prompt).
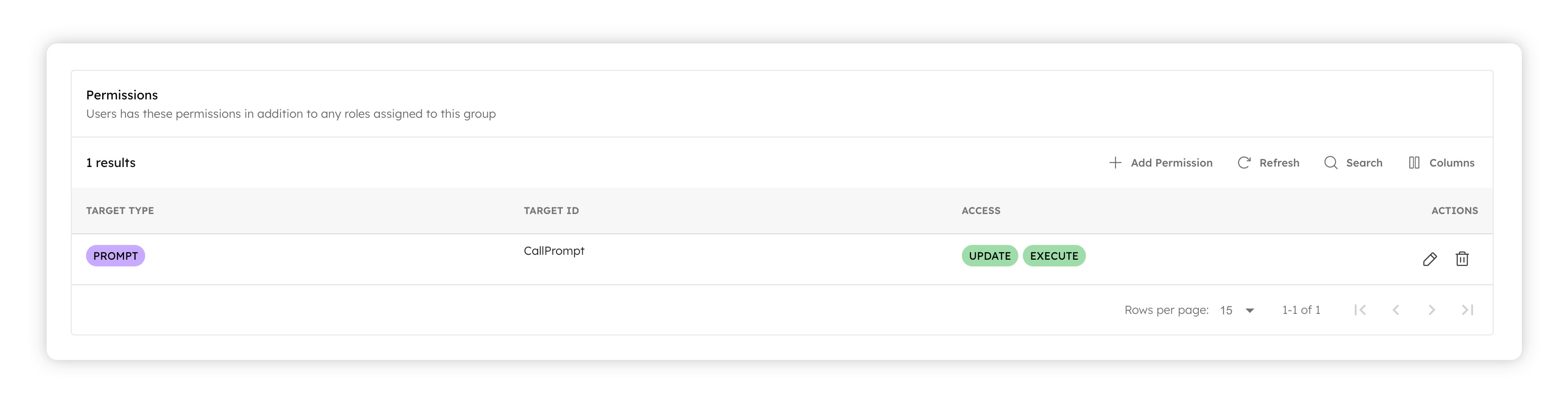
With these direct integrations from various model providers and vector database providers, along with comprehensive, prompt creation and management capabilities, you are now ready to use these in gen-AI powering your applications! And Orkes Conductor makes it easy with the introduction of new System Tasks to add model interactions and vector database usages into your application.
A quick primer on System Tasks: System Tasks are task types specialized for a particular capability (e.g., calling HTTP endpoints, writing an event to a queue). You can add them visually or using code in your workflow. When those are scheduled as part of a workflow execution, the Orkes Conductor cluster will run those tasks. In other words, you do not need to write external workers and manage them. More information about System Tasks can be found here.
This system task allows you to send a prompt to a text completion model and receive the answers. When configuring this system task, you can decide which model to use (as long as you have access to it), which prompt template to use (again, as long as you have access to it), and what variables in the workflow should be wired up to replace the variables in the prompt template. As with any task in Conductor, you can use the output of this task at any point further in that workflow execution.
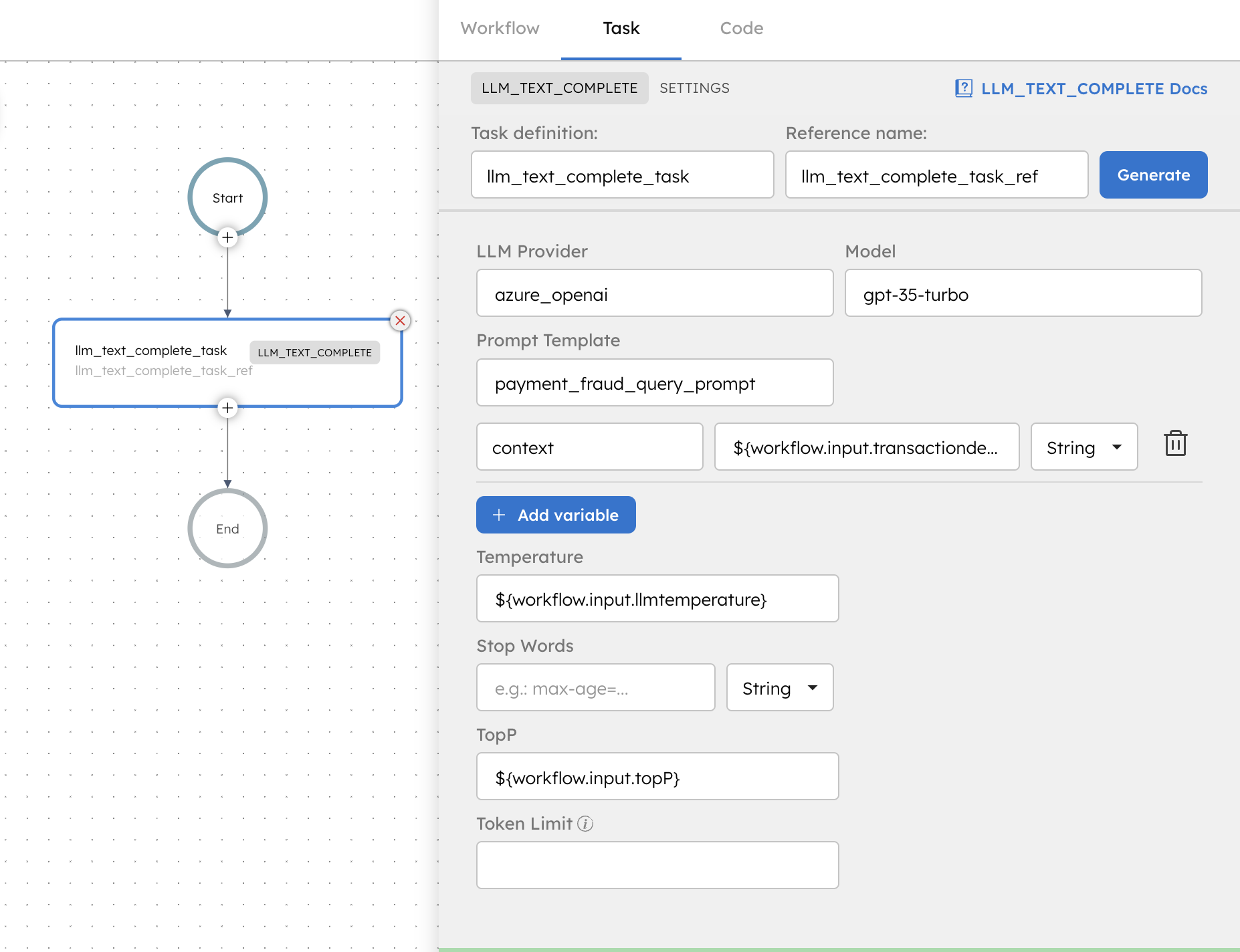
Additionally, every interaction between Orkes Conductor and a model can be consumed as a stream published to a queue using the Change Data Capture feature. This provides comprehensive and auditable governance that is important when using language models for enterprise applications.
Use this system task to convert a given text into a vector embedding using an embedding model from a provider that was previously added as an integration. The embedding obtained back from this system task can then be stored in a vector database or used as input to search for similar vectors in a vector database.
This system task can be used to provide an embedding as an input and get back a list of similar embeddings that have been previously generated or stored by the model.
This system task is used to do two things: convert a text into vector embeddings and store it in a vector database. In addition to the text you want to vectorize and store, you also need to specify, from the list of added integrations that you have access to, the embedding model to use and the vector index (in the case of Pinecone) / class (in the case of Weaviate) to store the embeddings.
This system task is similar to the LLM Index Text one, but instead of providing the text, here you can point to an entire document of the types listed below and Orkes Conductor will fetch it, chunk it, create embeddings (using the embedding model specified) and store them in the vector database specified. This is an easy and fast way to process huge amounts of data for later retrieval.
Currently, supported media types are:
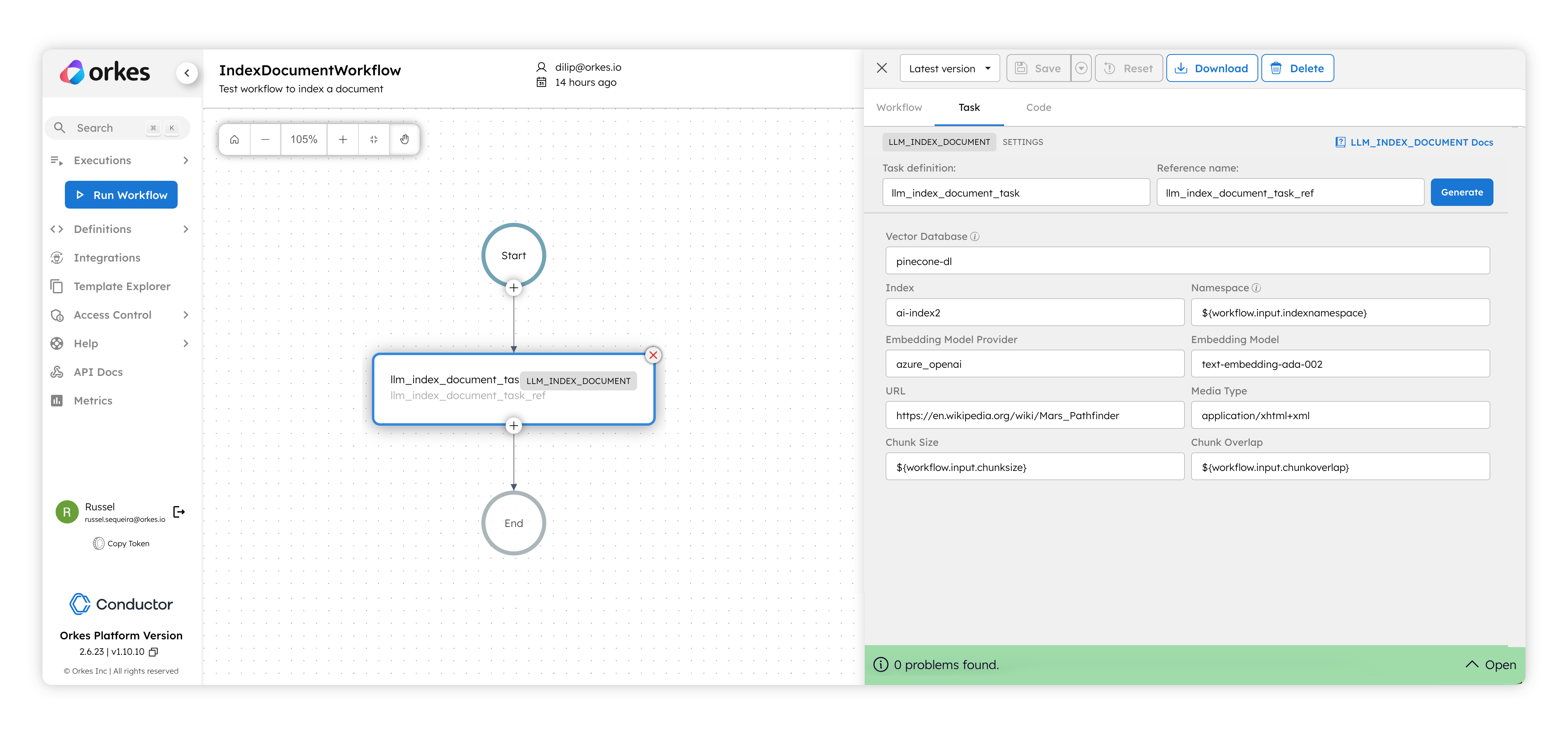
This system task is used to input a document and retrieve a list of documents that are similar to it from a vector database. It will first generate the embeddings of the input document using an embedding model, use that to search the vector database index specified and provide back the matching documents. The input can be provided as a URL while defining the workflow, or you can wire the URL from the workflow inputs.
Currently, supported media types are:
This system task is used to search for similar embeddings for a given text query. The query can be a natural language question and it will be used to find embeddings that are similar to its embedding equivalent. This system task also requires specifying which embedding model and vector database index/class integration needs to be used.
One important point to remember is that the query being provided and the search space vectors need to have been embedded in the same model. If you use different embedding models and you are using Pinecone, you can leverage the namespace construct in Pinecone to keep embeddings from different providers separated. The LLM Search Index system task can then be configured to use a specific namespace for the search.
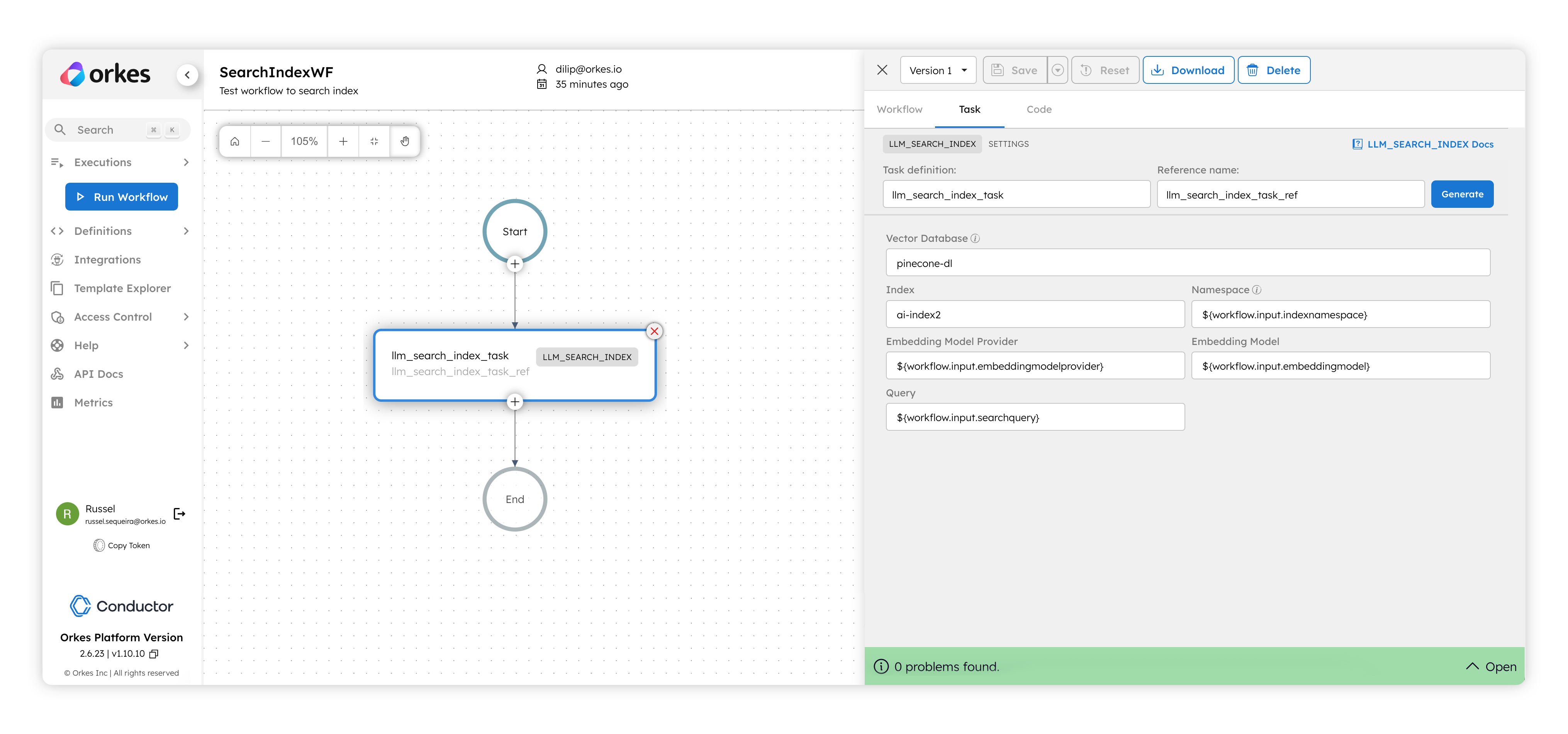
One thing you might notice in the above system task configuration panel is that the embedding model provider and the model is a dynamic variable. This is something Orkes Conductor fully supports when using any integrations in workflows - providing the integration names dynamically during workflow execution time.
The same applies to AI prompt templates used in workflows; they can also be dynamically set, and the associated variables in the template can be similarly set at workflow execution time.
All the role-based access control (RBAC) rules will still be observed, and you get the flexibility you need when building applications that need to behave differently based on the context of a particular instance of execution.
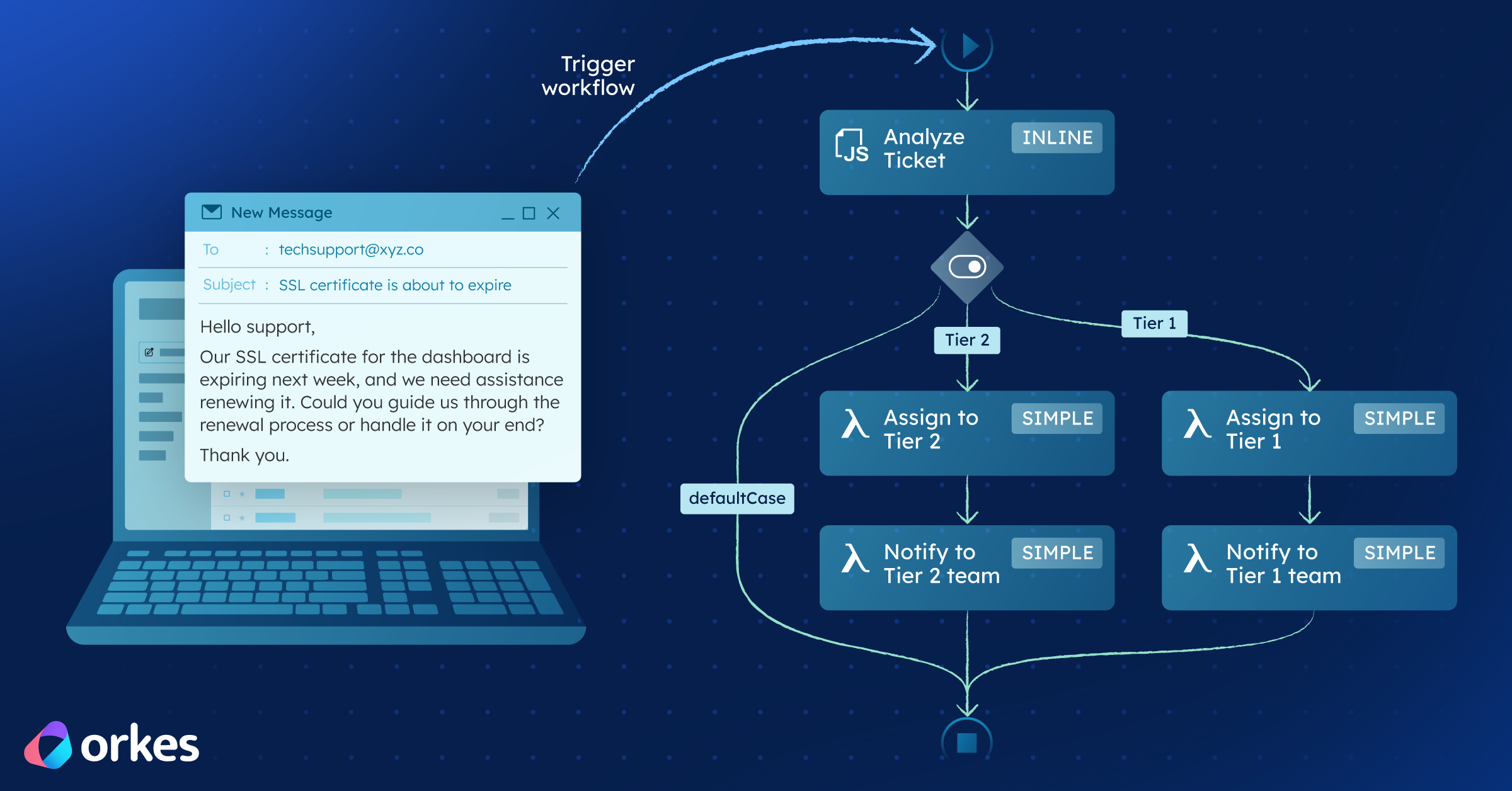
Many real-world business flows tend to have a human decision-maker or insight provider in their flow. Take the example of a mortgage processing workflow. There are multiple backend application components, such as checking a credit score, that can be fully automated. But there will also be some steps that need a human in the loop - e.g., if the amount to be approved is above a certain threshold, it requires a supervisor to sign off.
Typically, these human actions are handled in a separate stack and are wired up in different ways to talk to the rest of the backend processes. This tends to be brittle and goes against the way the business logic is organized, where human tasks belong right there in the core workflow along with other tasks. Furthermore, managing two stacks typically slows down the innovation velocity of engineering teams and fragments the observability experience.
Orkes Conductor solves this problem by providing native support for having human actors in the loop through a new set of constructs.
This is a new system task that can be added to a workflow to represent a human actor doing a task. During definition time, the developer can specify the responsibility chain for this task. The first person in that chain gets assigned this task, and if they do not complete it in the time specified, it will be reassigned to the next person in the chain, and this keeps going until the task is either completed or times out.
The human actors in this context can be a user or a group in that Orkes Conductor cluster, in which case Orkes ensures that only the right person gets this task assigned. When they log in to Orkes Conductor, they can go to the Tasks Inbox in the UI and see the list of tasks they can pick up and act on. If the human actors are external to the Orkes Conductor cluster, then external IDs provided for task assignment will be managed and verified by an external system, which will use Orkes Conductor APIs to read assignments and update status.
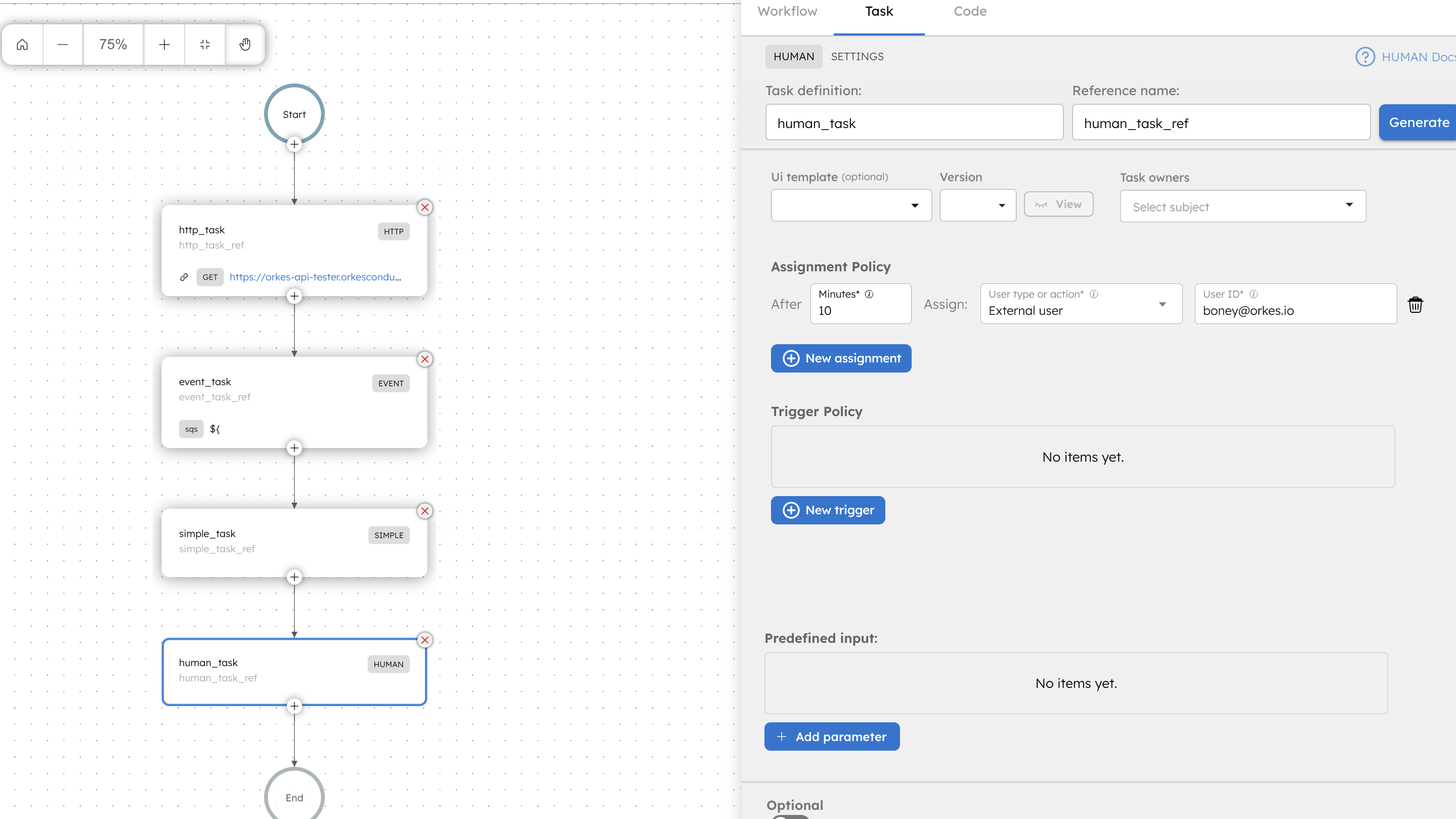
Within a human task, there are multiple sub-states that Orkes Conductor maintains and manages. When a workflow execution schedules a human task, it starts with the assigned state and is associated with an individual or a group.
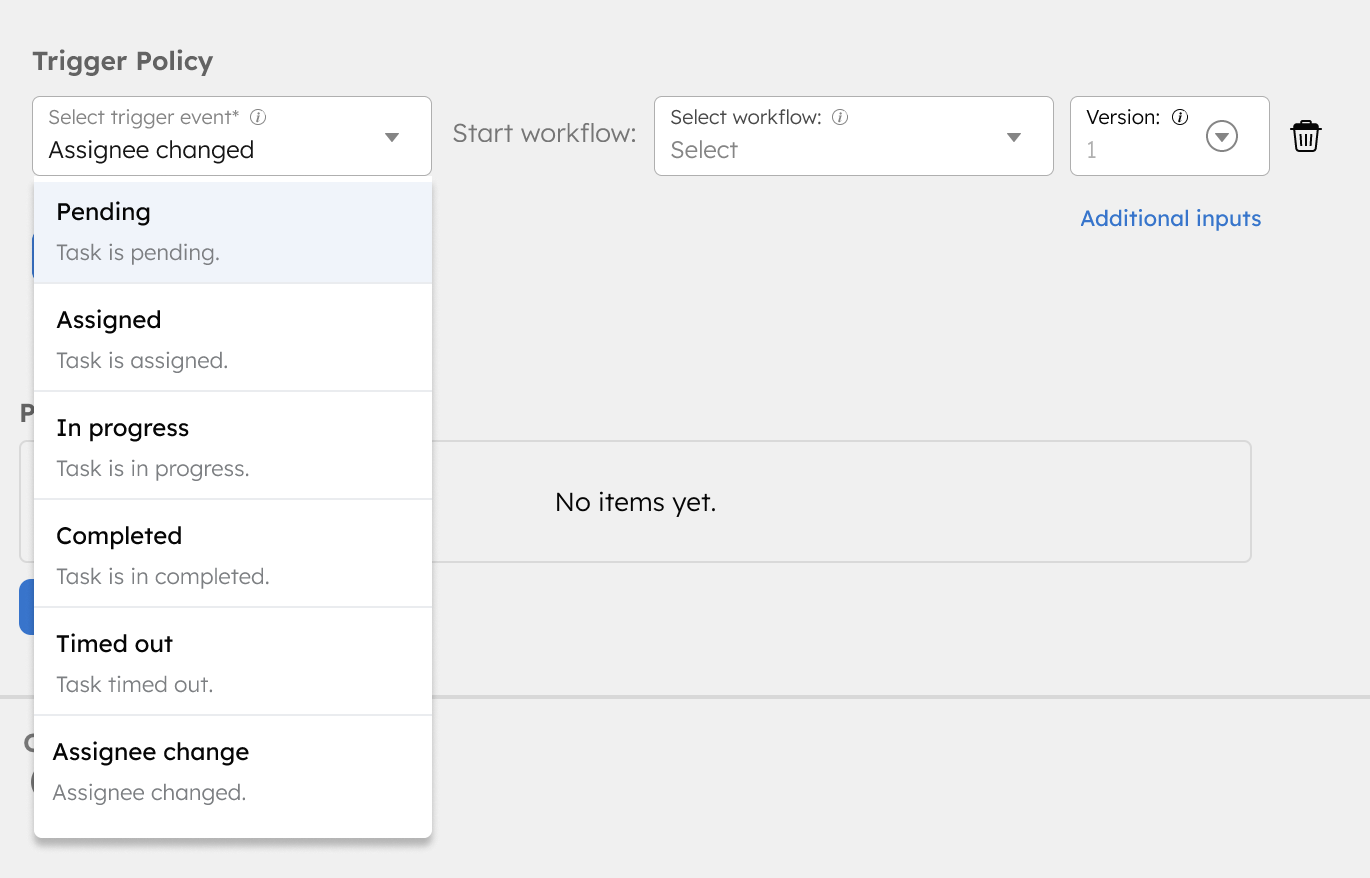
A powerful feature of the human task system task is the ability to trigger workflows based on state changes in an active human task. For example, if the assignment times out and goes to the next person in the assignment chain, a trigger can be defined to start a workflow that sends an email to the new assignee. The following triggers are supported now.
In most cases, a human task is performed by updating a form that is presented to the human actor. This can be an approval document that lists all the relevant details collected from different data values in the workflow execution, or it can be a form to which a human actor can add more data into the workflow. Orkes Conductor provides native forms that you can visually design in the UI. As with everything else in Orkes Conductor, provide secure sharing and re-usability by leveraging the native role-based access control feature.
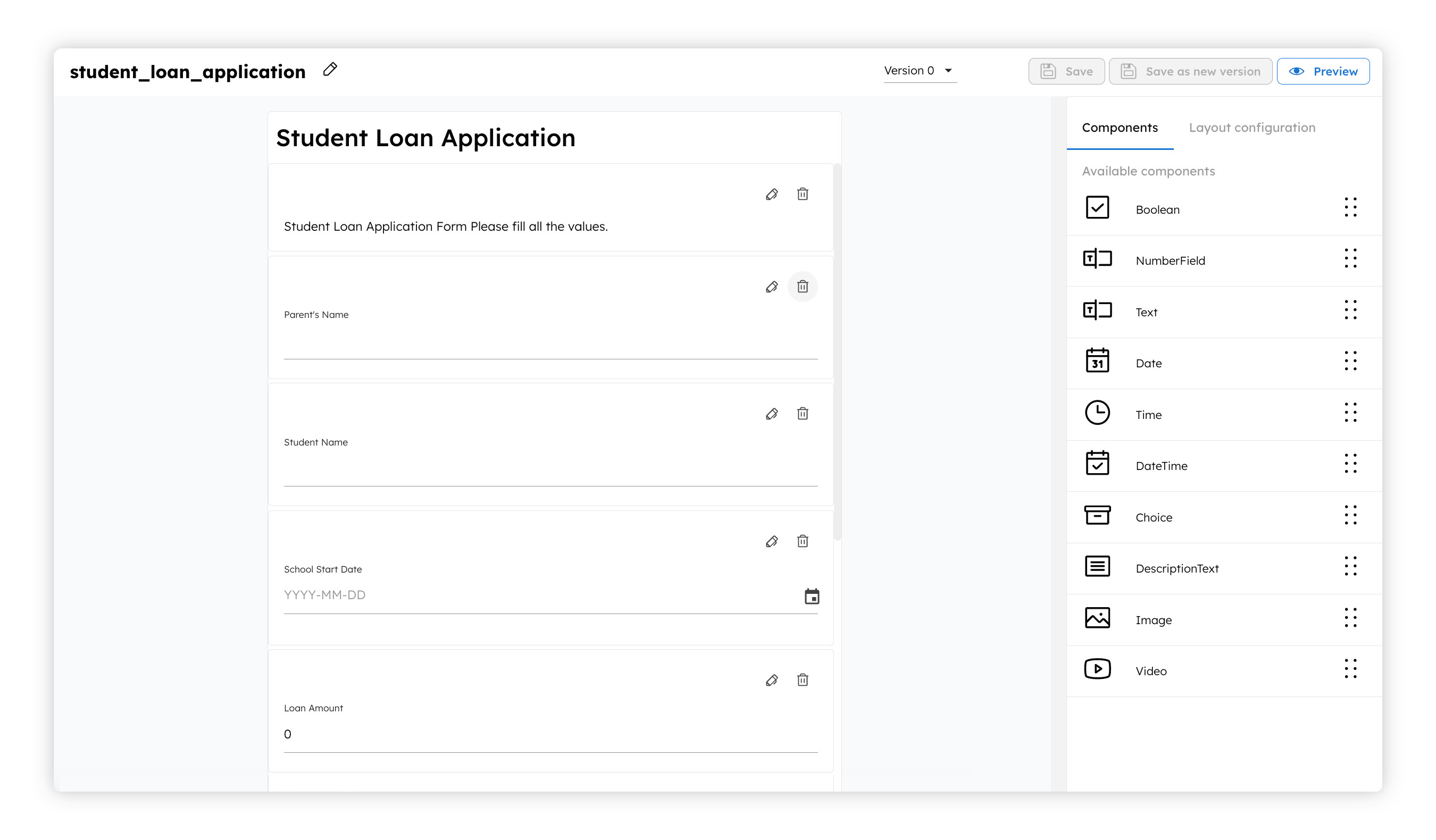
When a form is associated with a human task, it will be shown to a user when they come to the UI to claim tasks and act on them. With the ability to wire up any of the workflow inputs or task output from previous tasks, it is very easy for a developer to build a top visual experience for the human actors while having the dynamic data insertion capabilities needed.
We are excited to launch these two sets of features, AI Orchestration and Human Tasks, not only because they are impactful on their own but also because of how well they work together to empower developers to build impactful experiences.
Orkes Conductor makes this easy for developers by having these foundational components essentially woven into the application’s logic graph instead of building separate stacks. This also allows central observability where the whole application landscape can be observed, debugged, and iterated upon from Orkes. Plus, all of these are built with the same security primitives - role-based access model, single sign-on, change data capture, and secure cloud hosting environments - that come as part of the enterprise-grade Orkes Conductor platform.
The Document Classifier workflow template from the Template Explorer in our free Orkes Developer Edition is a great example to get started with. You can learn more about this example in the docs.
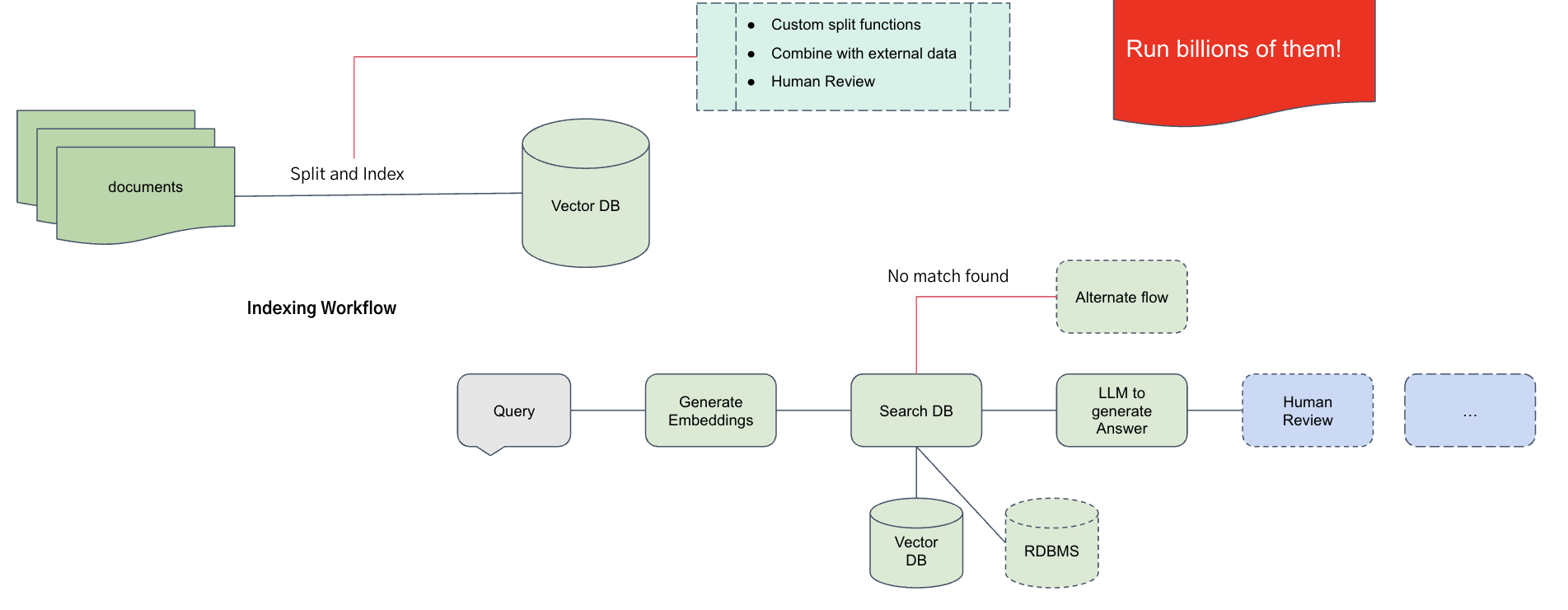
RAG is a popular and effective way to blend in large and private knowledge bases with the nuanced language understanding and text generation capabilities of LLMs. As and when new knowledge or data comes in, it will be added as embeddings into a vector database. And suppose you need to do something with that data (e.g., search that knowledge base for answers that combine insights across the data set vs just returning the matched data sets). In that case, you can query the vector database, retrieve the related data sets, combine that with a prompt to perform the analysis, send it to a model, and obtain back the answers.
With the new AI Orchestration features in Orkes Conductor, you now can:
And with all of these new constructs supported in Orkes Conductor’s role-based access control model, you can securely share and reuse them across your organization. With comprehensive change data capture for any task (including the new ones), you get unprecedented levels of observability and suitability for enterprise scenarios when LLMs are leveraged.
Learn how to do AI Orchestration with Orkes by building a Document Classifier app using this quickstart guide.
If you are looking to try out a proof of concept for your use cases, Orkes AI Orchestration and Human Tasks are now available for you to try out through Developer Edition. Check out the workflow templates available via Template Explorer to make it easy for you to get started.
For more detailed documentation on the AI Orchestration and Human Tasks features, please refer to the docs:
Join our community on Slack to learn from each other and discuss AI Orchestration, Human Tasks, and more! This is also a great place for you to connect with the Orkes team members and provide us with any feedback.
Let's go and Gen AI power applications!
Conductor is an enterprise-grade orchestration platform for process automation, API and microservices orchestration, agentic workflows, and more. Check out the full set of features or get a demo of Orkes Cloud, a fully managed and hosted Conductor service.