Using Vector Databases
This guide provides an overview of vector databases and how Orkes Conductor makes it easy to use them for AI tasks in workflows.
If you are already familiar with vector databases, skip the overview and proceed to the configuration steps.
Overview: Vector databases
A vector database is a type of database specifically designed to store and query vectors or multidimensional data. Vectors are mathematical entities with an ordered set of numerical values, often representing points or data in a multidimensional space.
Embeddings
An embedding is a representation of input data converted into an array of numbers known as vectors. This combination of numbers represented as a vector acts as a multidimensional map that can be used to find its similarity to other embeddings. A language model typically generates embeddings from an input and stores them in a database.
Namespaces
A namespace is a logical grouping or category of embeddings within a vector database. They are used to segregate different types of data or embeddings. It helps organize and manage diverse embeddings for more efficient storage and querying.
Indexes
Indexes are hierarchical structures built on embeddings in a vector database to optimize retrieval and query performance, similar to tables in a relational database. Indexes help you quickly locate and retrieve embeddings based on their similarity to a given query vector. Vendors use different terminology, Pinecone / Postgres Vector Database / Mongo Vector Database refers to them as "indexes," while Weaviate calls them "collections."
Configuring vector databases
- An AI model generates an embedding to store data in a vector database. To facilitate this process, you must also integrate an AI model provider of your choice.
Here is an overview of using vector databases in Orkes Conductor:
- Choose a vector database provider.
- Integrate your chosen vector database with your Orkes Conductor cluster.
- Set access limits to the vector database to govern which applications or groups can use it.
- Use a vector database in your workflow by adding an AI task and configuring it for the chosen vector database.
Step 1: Choose a vector database provider
The following vector database providers are available for integration with Orkes Conductor:
Review the provider’s official documentation to determine which database suits your use case.
Step 2: Integrate a vector database provider
Before using a vector database in a workflow, you must integrate it with your Orkes Conductor cluster.
To integrate a vector database provider:
- Go to Integrations > Connections and Resources from the left navigation menu on your Conductor cluster.
- Select + New integration.
- In the Vector Databases section, select + Add to integrate your preferred database provider.
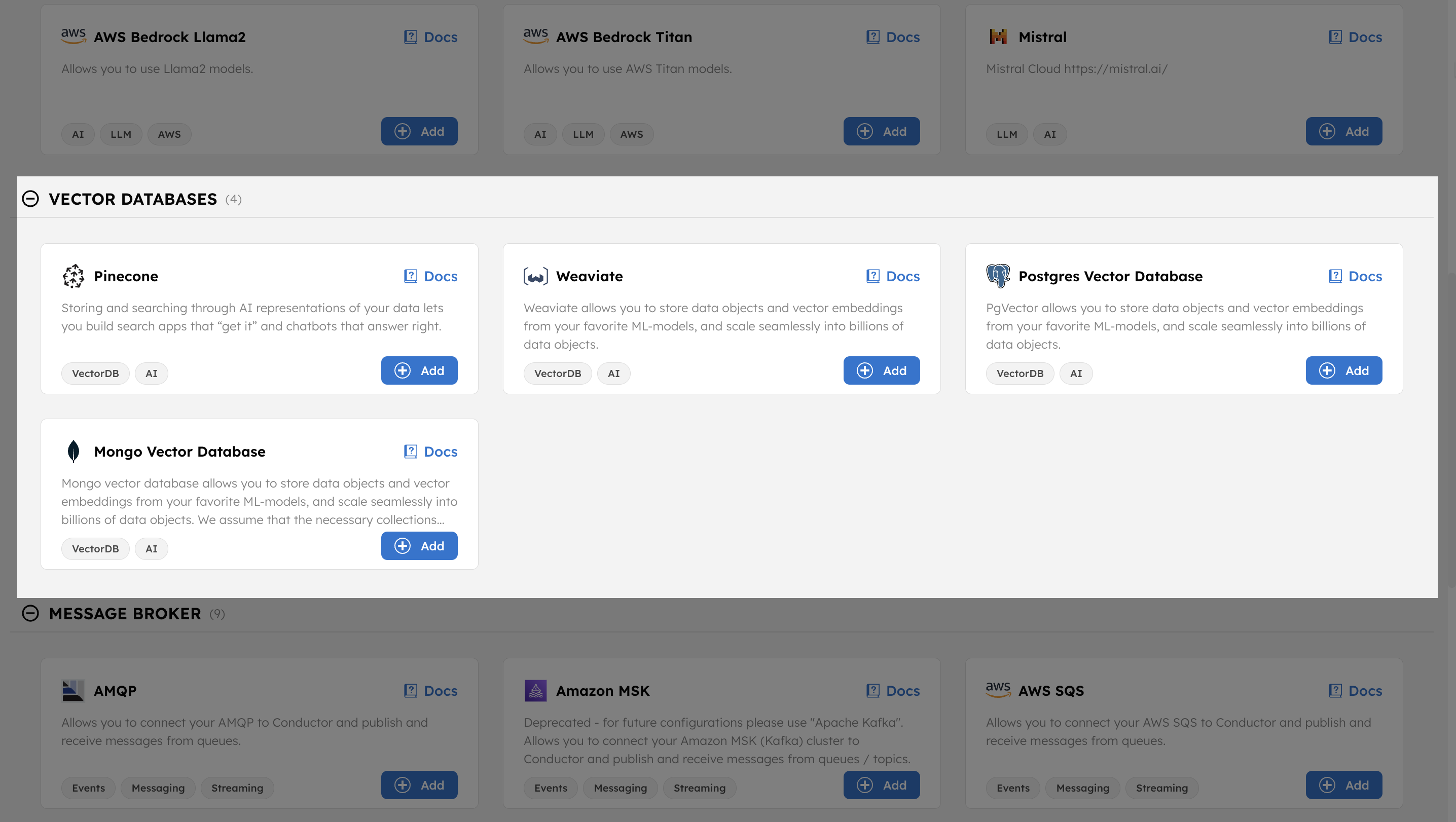
- Enter the required parameters for the chosen provider.
The integration configuration differs with each provider. For detailed steps on integrating with each provider, refer to Vector Database Integrations.
- (Optional) Toggle the Active button off if you don’t want to activate the integration instantly.
- Select Save.
Add the preferred indexes/collections
Once the vector database integration is added, you can begin adding indexes/collections from the provider.
To add an index/collection:
- In Integrations, select the + icon next to your newly-created integration.
- For Pinecone, Postgres Vector Database, or Mongo Vector Database, select + New Index.
- For Weaviate, select + New Collection.
- Enter the index or collection name and an optional description.
- (Optional) Toggle the Active button off if you don’t want to activate it instantly.
- Select Save.
Step 3: Set access limit for integrations
As best practice, use Orkes’ RBAC feature to govern which user groups or applications can access the database providers.
To provide access to an application or group:
- Go to Access Control > Applications or Groups from the left navigation menu on your Conductor cluster.
- Create a new group/application or select an existing one.
- In the Permissions section, select +Add permission.
- In the Integration tab, select the required vector databases and toggle the necessary permissions.
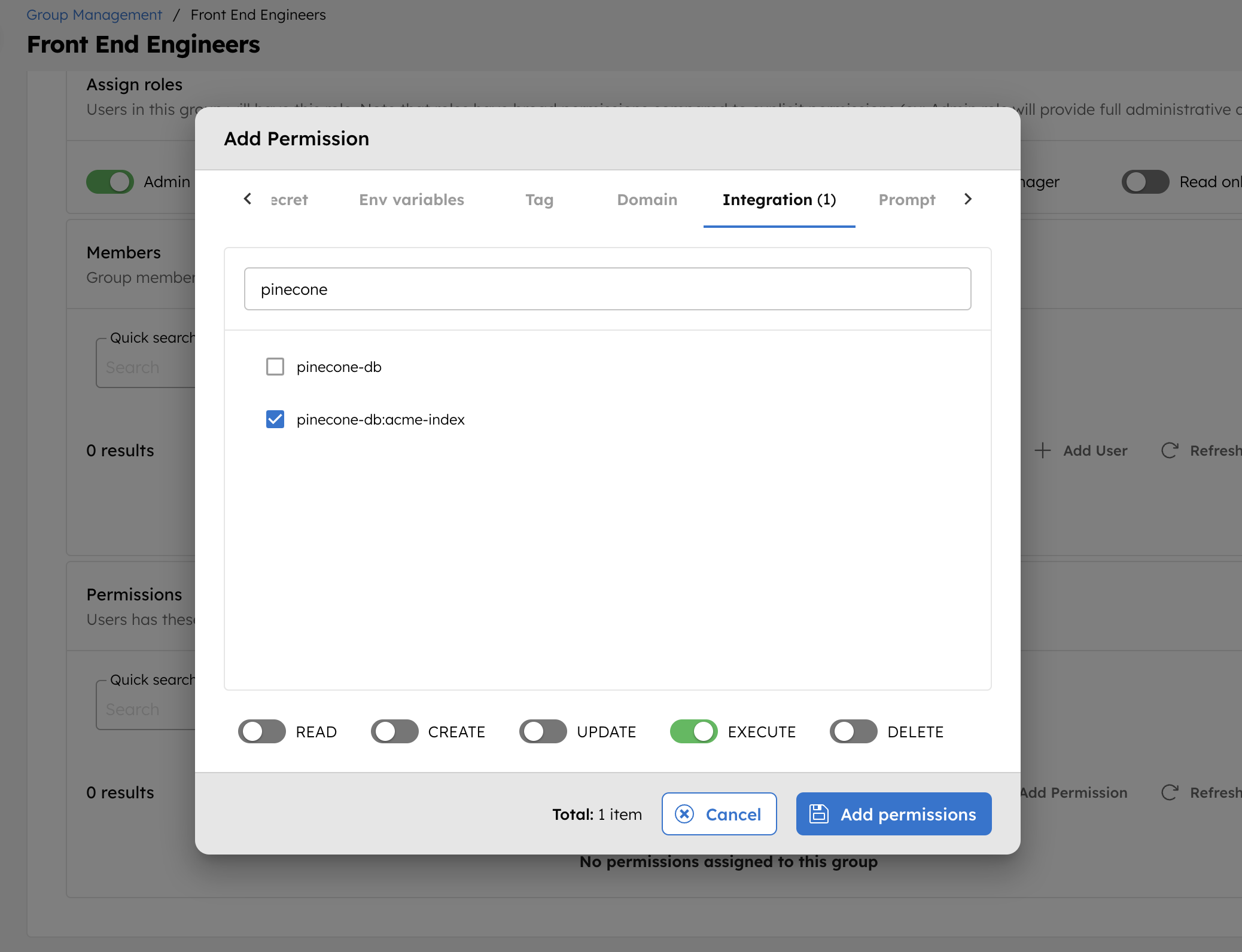
- Select Add Permissions.
The group or application can now access the vector databases according to the configured permissions.
Step 4: Use vector databases in workflows
Vector databases can be used in workflows with the following AI tasks:
To use a vector database in workflows:
- Go to Definitions > Workflow from the left navigation menu on your Conductor cluster.
- Select + Define workflow.
- In the visual workflow builder, select Start and add the relevant AI task based on your use case.
- Select the configured vector database and indexes.
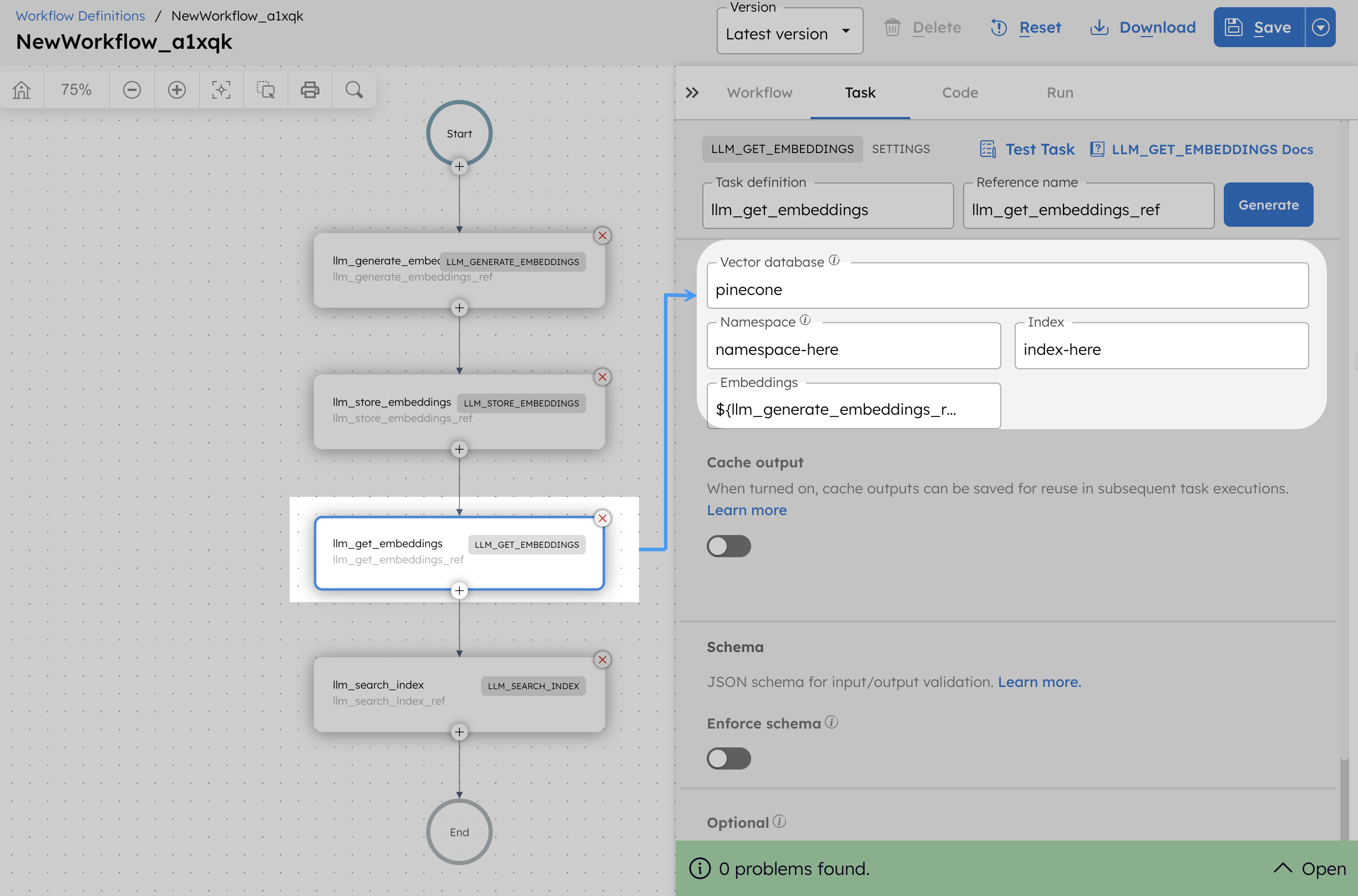
- Configure the remaining task parameters.
Refer to the AI Task Reference for more details on configuring the task parameters.
- Select Save > Confirm.
Examples
AI tutorials
Explore the AI tutorials section for step-by-step, end-to-end examples that use different AI tasks and vector database integrations.