Agentic Research Assistant
This template is only available in the Developer Edition on Launch Pad.
This agentic research template generates either a literature review or a research gap report based on the user query. Powered by LLMs, the workflow identifies the user’s intent from the query and compiles the latest research findings with search grounding.
An agentic research assistant can speed up the discovery process in academic research. Within minutes, researchers can gain a deeper understanding of a specific field, freeing up time to design their research thesis.
This template serves as a quickstart for building agentic workflows. You can use this as a basis to understand the design patterns involved in an agentic workflow and extend it with your own data sources and control flow.
Conductor features used
This template utilizes the following Conductor features:
- Set Variable task
- Fork/Join task
- Switch task
- Terminate task
- Do While task
- Inline task
- Dynamic Fork task
- LLM Text Complete task
- AI Prompt Template
- Worker task (Simple)
How to use the template
- Import the template from Launch Pad.
- Configure AI/LLM integrations and models.
- Configure AI prompts.
- Set up a worker for report generation.
- Run workflow.
The agentic research template uses AI models. Ensure that you have API keys for the following model providers:
Step 1: Import the template
The agentic research template is only available in the Developer Edition on Launch Pad.
To import the template:
- Go to Developer Edition > Launch Pad on the left navigation menu.
- In Pre-built Workflow Templates, select Agentic Research, and then choose Use Template.
- Select Import.
- In Required Integrations, select or create an integration for the following services:
- (If creating a new integration) Select Create integration from the dropdown list.
- Enter an Integration name.
- In API Key, paste the API key copied from your OpenAI / Perplexity / Anthropic account.
- Enter a Description for the integration.
- Select Save.
- Select Continue Workflow to import the workflow.
The agentic_research workflow is now imported and ready for use.
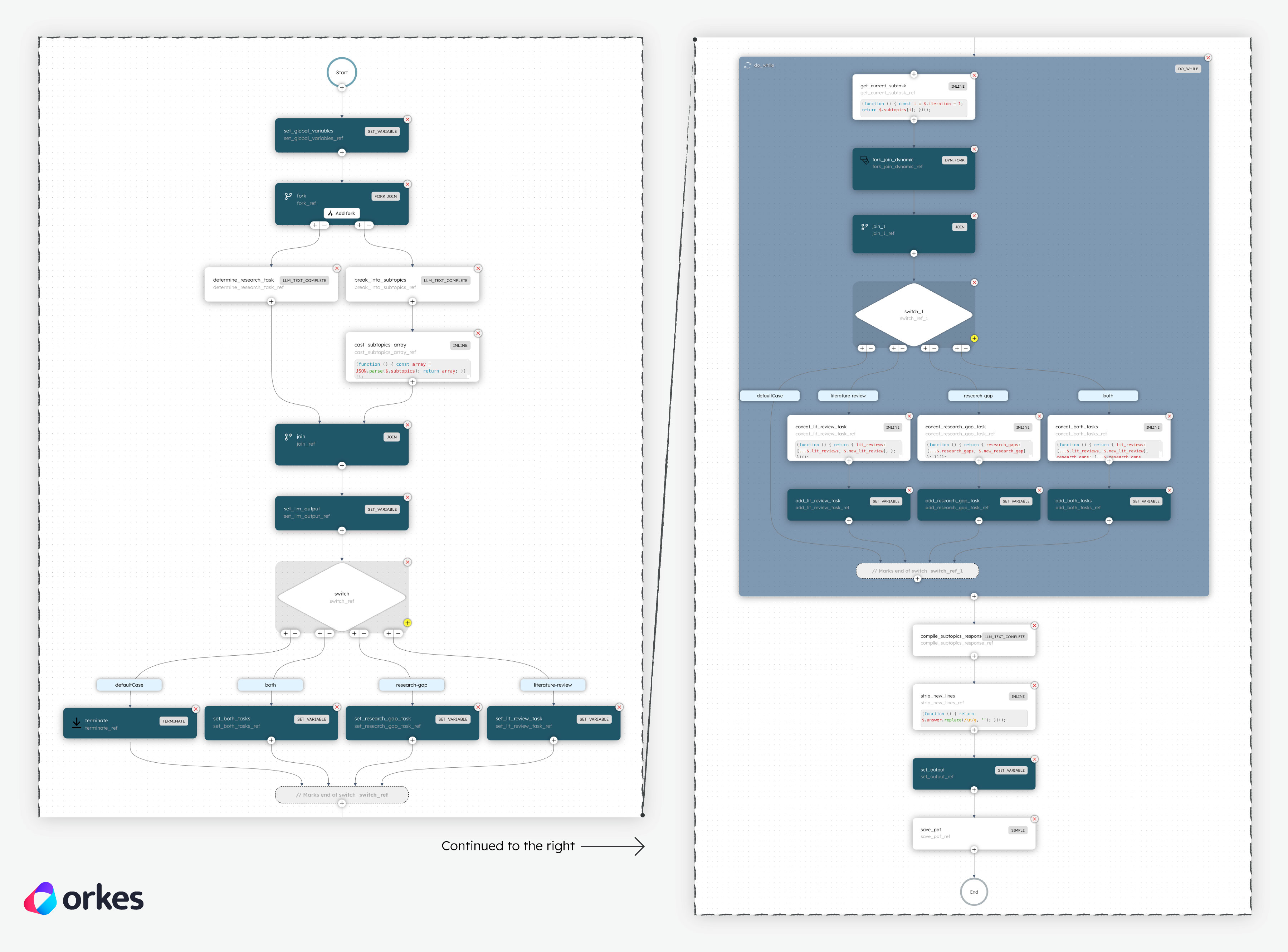
Understand the workflow logic
This section explains the workflow logic and how to execute it.
AI components:
There are five LLM Text Complete tasks in the workflow. Using LLMs, each LLM Text Complete task contributes either to a decision-making node (agentic) or to generating content:
determine_research_task— Determines what task to conduct in the workflow (research-gap, literature-review, both, or none) based on the user’s research question.break_into_subtopics— Identify research sub-topics based on the user’s research question.lit_review_task(used in a Dynamic Fork) — Conduct literature review research.research_gap_task(used in a Dynamic Fork) — Conducts a research gap analysis.compile_subtopics_response— Synthesizes a compiled report based on thelit_review_taskand/orresearch_gap_task.
Workflow inputs:
- question—The research question (“What are the latest findings in neutron stars and what is still unknown?”)
- filename—The file name for the generated .pdf report. (“myReport.pdf”)
Workflow logic:
The workflow begins with a Set Variable task that initializes global workflow variables for convenient retrieval later:
- answer—the final report content, which is an empty string for now.
- question—the user’s initial query.
- lit_reviews—the research from the
lit_review_task(an empty array for now). - research_gaps—the research from the
research_gap_task(an empty array for now).
With the variables declared, the workflow proceeds to identify what task to do next and the list of research sub-topics based on the user’s query using separate LLM Text Complete tasks. A Fork/Join is used to process these tasks in parallel.
Another Set Variable task is used to declare additional global workflow variables based on the LLM evaluation:
- subtopics—the list of sub-topics that will be used for the research.
- decision—the selected task(s) that the workflow will carry out (research-gap, literature-review, both, or none).
If the decision is none, meaning the user query is irrelevant, the workflow will terminate with a Terminate task.
Otherwise, the workflow will continue to a Switch task, which routes to the relevant Set Variable task that prepares the exact configuration of the task(s) to be carried out later. This routing step is in preparation for the Dynamic Fork task later on, which requires the task configuration as input.
Next, a Do While task is used to iterate through each sub-topic and generate its research findings. Inside the loop:
- The Inline task is used to track the iteration counter and set the relevant sub-topic.
- The Dynamic Fork will dynamically call the task(s) set during the prior Switch task.
- The task(s) serve as the core research generation step carried out by LLM Text Complete tasks, which are powered by Perplexity models with web search access.
- If both a literature review and a research gap report are required, the Dynamic Fork will generate two forks to conduct research for both areas in parallel. Likewise, if only one task is required, the Dynamic Fork will generate one fork.
- Another Switch task and Set Variable task combination is used to concatenate each sub-topic’s research findings into a single array, which can be accessed and updated with the previously-declared
lit_reviewsand/orresearch_gapsvariables.
Finally, once the research is completed, another LLM Chat Complete task is used to synthesize the sub-topics’ findings into a formatted report that answers the user’s original question. A custom Worker task is used to generate a .pdf file that downloads directly to the user’s desktop for convenient access.
Step 2: Configure AI/LLM models
To use the LLM Text Complete tasks, you must set up the following models for the AI/LLM integrations imported in Step 1:
- OpenAI–gpt-4o (for
determine_research_taskandbreak_into_subtopics) - Perplexity—sonar (for
lit_review_taskandresearch_gap_taskin the Dynamic Fork) - Anthropic—claude-3-7-sonnet-20250219 (for
compile_subtopics_response)
There is a limit of 5 models on Developer Edition.
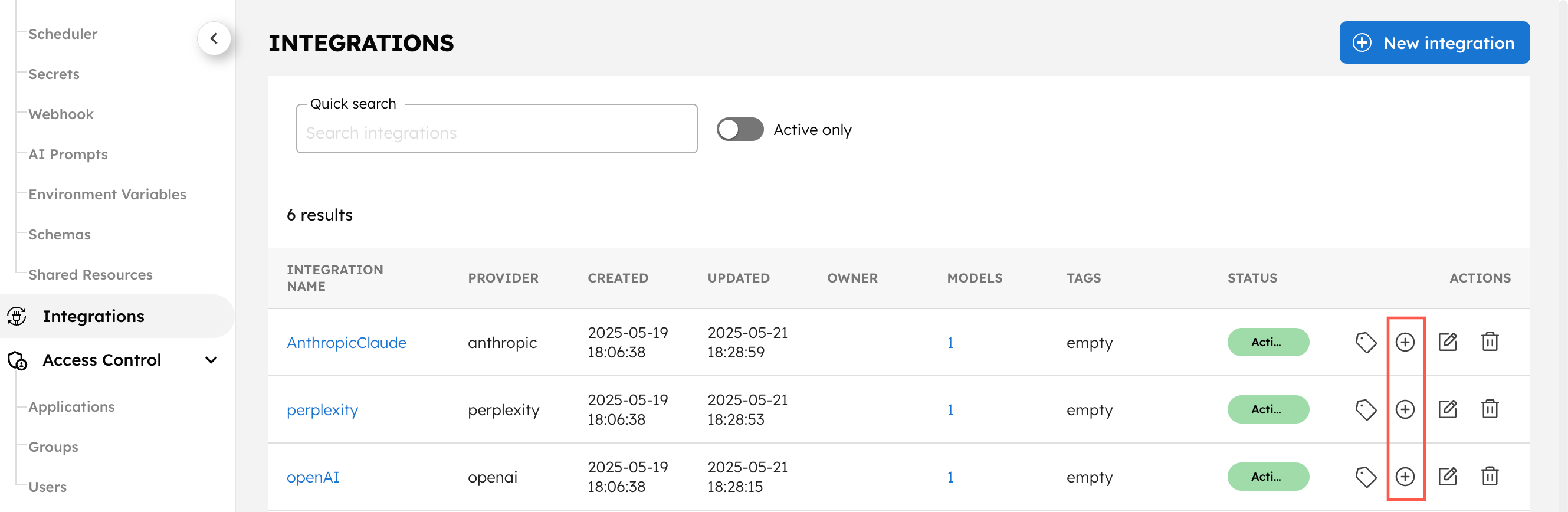
To add a model to your integration:
-
Go to Integrations on the left navigation menu.
-
For each integration, select the + icon (Add/Edit models), then select + New model.
-
Add the following Model name for the corresponding integration:
- OpenAI–gpt-4o
- Perplexity—sonar
- Anthropic—claude-3-7-sonnet-20250219
-
Ensure that the Active toggle is switched on and select Save.
The AI/LLM models are now ready to use.
Step 3: Configure AI prompts
To use the LLM Text Complete tasks, you must set up the AI prompts. The five prompts required for the agentic_research workflow have already been imported during Step 1:
- query_task_decision
- break_into_subtopics
- literature_review_task
- research_gap_task
- compile_subtopic_responses
The prompt determines subsequent tasks (research-gap, literature-review, both or none) based on the user's query.
You are an academic research agent.
Given the user's request, identify what kind of research task they want to perform:
Options:
- literature-review - if they are asking for a summary of existing knowledge
- research-gap - if they want to identify what is still unknown or under-researched
- both - if they want both a literature review and to find gaps
- none - if the query doesn't request any research
User query: "${user-query}"
Output only one of: "literature-review", "research-gap", "both", or "none"
Ex. 1
Query: What are the latest findings in child development psychology?
Output: literature-review
Ex. 2
Query: What is still unknown about neutron stars?
Output: research-gap
Ex. 3
Query: What do we know and don't know about black holes?
Output: both
Ex. 4
Query: Write me a Haiku!
Output: none
The prompt breaks a research query into distinct sub-topics.
You are an academic research agent. Your task is to identify relevant and specific sub-topics within the field mentioned in the user's query:
"${user-query}"
Make sure:
- If the query is broad, generate a diverse but representative set of sub-topics (up to 5).
- If the query is narrow or specific, output only the most relevant sub-topics (fewer than 5 is fine).
- Sub-topics must directly align with the focus of the query—avoid generalities.
- Only output a JSON-style array of topic strings.
Ex. 1
Input: "What are the latest findings in child development psychology?"
Output: ["cognitive development", "emotional and social development", "language acquisition", "attachment and parenting styles", "impact of technology on development"]
Ex. 2
Input: "What is still unknown about neutron stars?"
Output: ["interior composition and equation of state", "post-merger behavior", "magnetic field dynamics"]
Ex. 3
Input: "What are the implications of microplastics in drinking water?"
Output: ["human health impacts of microplastics", "microplastic contamination pathways", "removal methods in water treatment systems"]
Ex. 4
Input: "I want to know what are the current efforts into the taxonomy of Singapore's fly species."
Output: ["taxonomic classification of Diptera in Southeast Asia", "endemic fly species in Singapore", "molecular phylogenetics of Singaporean flies", "biodiversity surveys and insect sampling methods in urban tropics"]
The prompt conducts a literature review given a sub-topic.
You are an academic research assistant.
Your task is to write a concise literature review for the following topic:
"${sub-topic}"
Follow these instructions carefully:
🔍 Use Only Verifiable Information
- Base your summary solely on reliable academic sources.
- If no credible information is available on a point, do not make assumptions or generalizations. It is better to omit than speculate.
📚 Ground the Review in Real Citations
- As much as possible, include author names, publication years, or study titles.
- If such details are not available, clearly state the lack of citation rather than inventing examples.
✍️ Tone and Style
- Write in a concise, academic, and readable tone.
- Highlight foundational theories, well-known studies, and recent developments in the field.
- Do not overstate the certainty of findings; reflect the nuance and debate present in the literature.
🧠 Structure and Focus
- Focus on summarizing what is well-understood or frequently studied.
- If relevant, note key gaps or disagreements in the research.
Example Inputs and Expected Outputs:
Sub-Topic 1: "attachment theory"
Output 1: "Attachment theory, developed by John Bowlby in the mid-20th century, posits that early emotional bonds between children and caregivers are critical for psychological development. Mary Ainsworth's "Strange Situation" study (1978) identified attachment styles such as secure, avoidant, and anxious. Recent literature explores how attachment patterns persist into adulthood (Mikulincer & Shaver, 2016) and how cultural contexts influence attachment behavior. Neurobiological research has also linked secure attachment to lower stress reactivity in infants."
Sub-Topic 2: "neutron star mergers and gravitational waves"
Output 2: "Neutron star mergers are a key source of gravitational waves, as confirmed by the landmark detection of GW170817 in 2017 by LIGO and Virgo. These events provide insight into the r-process nucleosynthesis responsible for heavy elements like gold and platinum. Literature since 2018 has focused on electromagnetic counterparts (e.g., kilonovae), constraints on the neutron star equation of state, and the role of binary evolution in producing merger progenitors. Current research emphasizes multi-messenger astronomy and refining mass-radius measurements through future observations."
Sub-Topic 3: "quantum computing in early childhood education"
Output 3: "There is currently limited peer-reviewed literature directly addressing the use of quantum computing in early childhood education. While quantum computing is an emerging field in computer science and physics, its application in K–12 education—particularly among early learners—has not been widely explored. Existing studies on quantum education primarily focus on undergraduate and graduate-level curricula (e.g., Singh et al., 2020) or public engagement strategies. Future interdisciplinary research could examine how simplified quantum concepts might be introduced in age-appropriate educational contexts, but as of now, this remains an underexplored area in the academic literature."
Tips for Strong Literature Review:
- Be specific about the tone: "concise," "academic," "grounded in research"
- Encourage citations and publication dates to increase trust
- Prompt for recent and foundational work
- If using a web-search agent, you can also instruct the model to "retrieve recent peer-reviewed sources" before summarizing
The prompt conducts a research gap analysis given a sub-topic.
You are an academic research assistant.
Your task is to identify verifiable research gaps in the following topic:
"${sub-topic}"
Carefully review the existing body of knowledge and pinpoint areas that remain poorly understood, underexplored, or debated. Focus on:
- Unanswered questions highlighted by recent reviews or studies
- Methodological limitations (e.g., sample size, bias, study design)
- Outdated theories or assumptions challenged by newer work
- Contradictions between major findings or schools of thought
- Population or context-specific gaps (e.g., non-Western settings, underrepresented groups)
Write in an academic yet accessible tone. Each gap should be clearly framed to guide future research efforts.
⚠️ If insufficient peer-reviewed literature exists on the topic, explicitly state that the research field is still emerging or underdeveloped.
As much as possible, reference key authors, study names, or publication years to justify why these gaps persist and why they matter.
Example Inputs and Expected Outputs:
Sub-Topic 1: "attachment theory"
Output 1: "While attachment theory is well-established, several gaps remain. For example, there is limited understanding of how digital communication platforms (e.g., texting, social media) affect attachment formation during adolescence (see Madigan et al., 2018). Cross-cultural validation is also limited; most empirical studies focus on Western contexts, with relatively little research from collectivist cultures (Mesman et al., 2016). Additionally, longitudinal studies tracking the impact of early attachment on adult psychopathology across diverse populations are scarce, hindering broader generalizability."
Sub-Topic 2: "neutron star mergers and gravitational waves"
Output 2: "Despite the breakthrough observation of GW170817 (Abbott et al., 2017), major research gaps persist. One involves the poorly constrained role of magnetic fields in post-merger dynamics, which remain difficult to simulate accurately. Another is the uncertainty around how much mass is ejected during mergers and its impact on r-process nucleosynthesis. Current theoretical models often diverge from observational estimates, particularly regarding kilonova brightness and decay curves (Metzger, 2019)."
Sub-Topic 3: "impact of technology on child development"
Output 3: "While research on screen time is abundant, gaps remain in understanding how different types of digital content—interactive vs. passive—affect cognitive outcomes (Rideout & Robb, 2021). There is also limited research on the influence of AI-generated or algorithmically curated content on children's language and emotional development. Furthermore, few large-scale studies explore how socio-economic disparities mediate access, content quality, and parental mediation practices."
Tips for Strong Research Gap Analysis:
- Analyze limitations in the current research, not just summarize it.
- Use cues like underexplored, contradictory, outdated, or not well understood.
- Encourage it to include why a gap matters (i.e. “this gap impedes X”).
- Mentioning methodological or population-specific gaps often adds depth.
The prompt compiles a report, given a list of literature reviews and/or research gap analysis.
You are an academic research assistant.
You are given information on sub-topics within a broader research field. This information may include:
- A list of literature reviews (summaries of key findings, theories, or recent work)
- A list of research gaps (open questions, underexplored areas, or suggested future research)
You may receive one, the other, or both.
Your task is to generate a single, synthesized literature review that addresses the original research question:
${original_question}
Organize the report according to the information from the subtopics:
- Summarize the key points under a "Literature Review" section (if provided).
- List any identified research gaps under a "Research Gaps" section (if provided).
- If only one type of content is available, include just that.
- Avoid structuring the report by each subtopic, it should be synthesized to the original question.
Your final output should be:
- A cohesive, academic-style report written in a formal tone using all sub-topics
- Focused on synthesizing the provided content to give a holistic view of the research landscape related to the original question
Ensure the output is in HTML format and fully wrapped in appropriate <html>, <head>, and <body> tags. Use the following structure:
1. HTML Structure:
- Use <h1>, <h2>, <h3> tags for headings.
- Use <p> tags for paragraphs.
- Use <ul> and <li> for lists.
Here is the data:
Literature Reviews:
${lit_reviews}
Research Gaps:
${research_gaps}
Generate a synthesized academic report accordingly.
To finish setting up the AI prompts:
- Go to Definitions > AI Prompts.
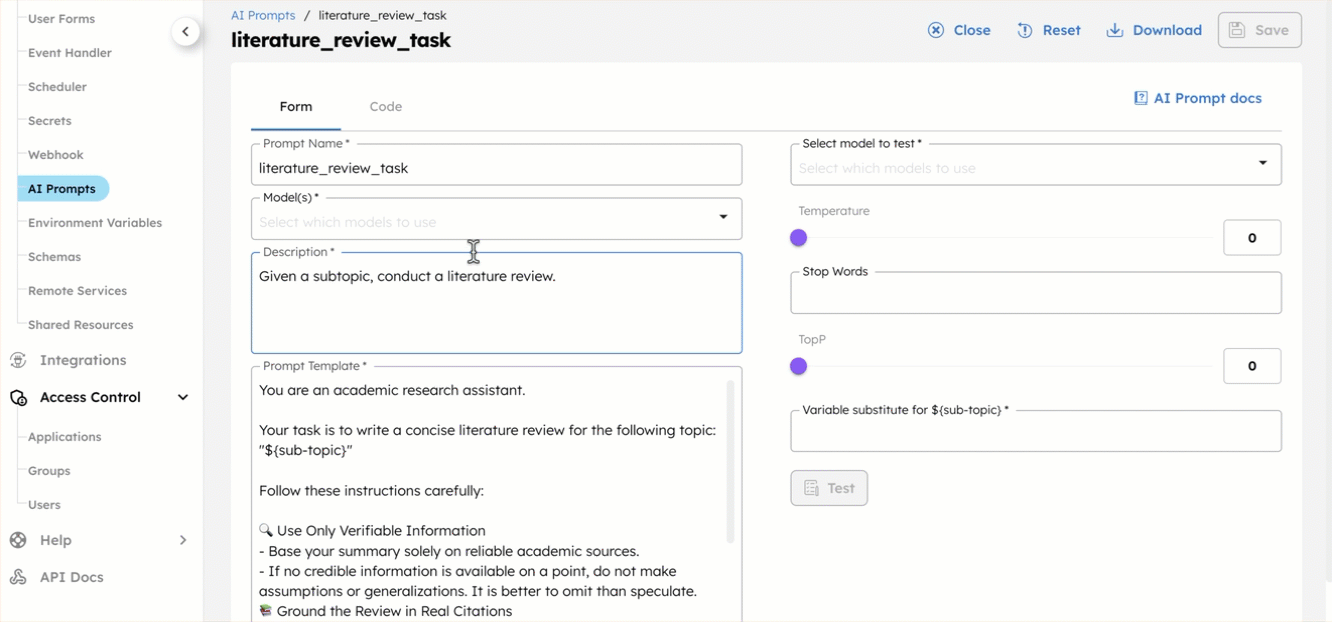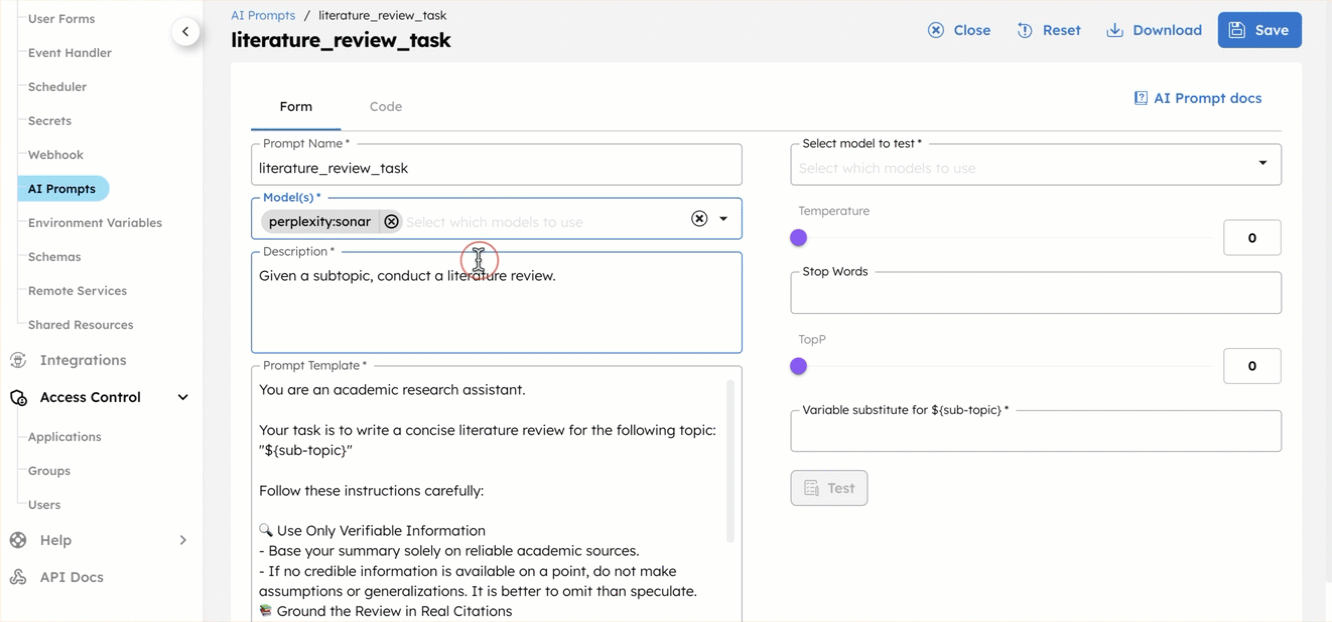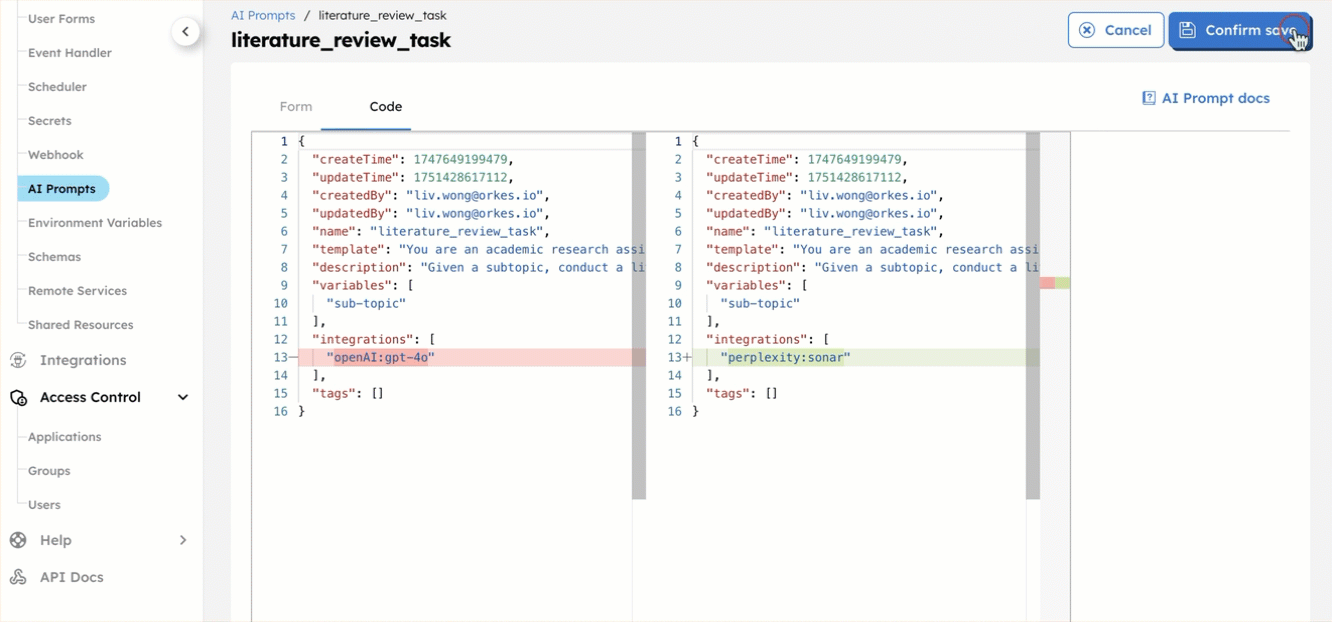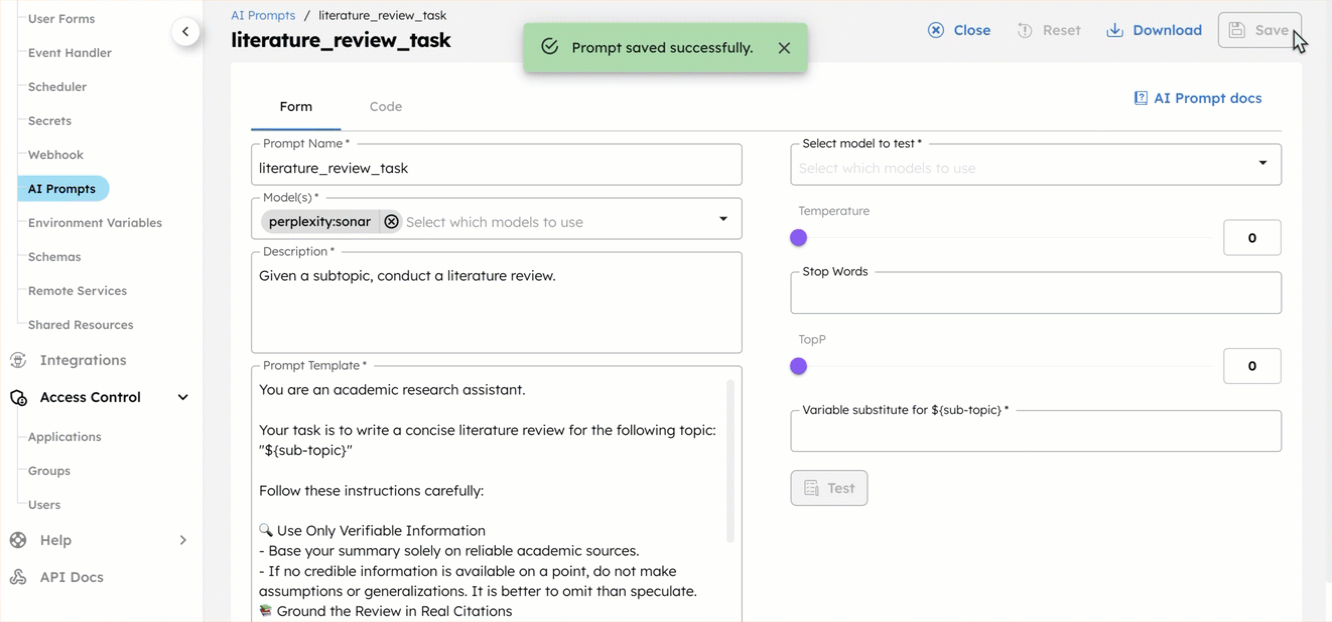
- Select each prompt, add the associated Model(s), then select Save > Confirm save:
- break_into_subtopics—[yourOpenAIIntegration]:gpt-4o
- query_task_decision—[yourOpenAIIntegration]:gpt-4o
- literature_review_task—[yourPerplexityIntegration]:sonar
- research_gap_task—[yourPerplexityIntegration]:sonar
- compile_subtopic_responses—[yourAnthropicIntegration]:claude-3-7-sonnet-20250219
Step 4: Set up custom worker
The final .pdf report is created using a custom Worker task that takes the raw report content and generates a file based on the supplied file name. To use the task, you need to set up a worker locally and connect it to the Conductor server with access credentials.
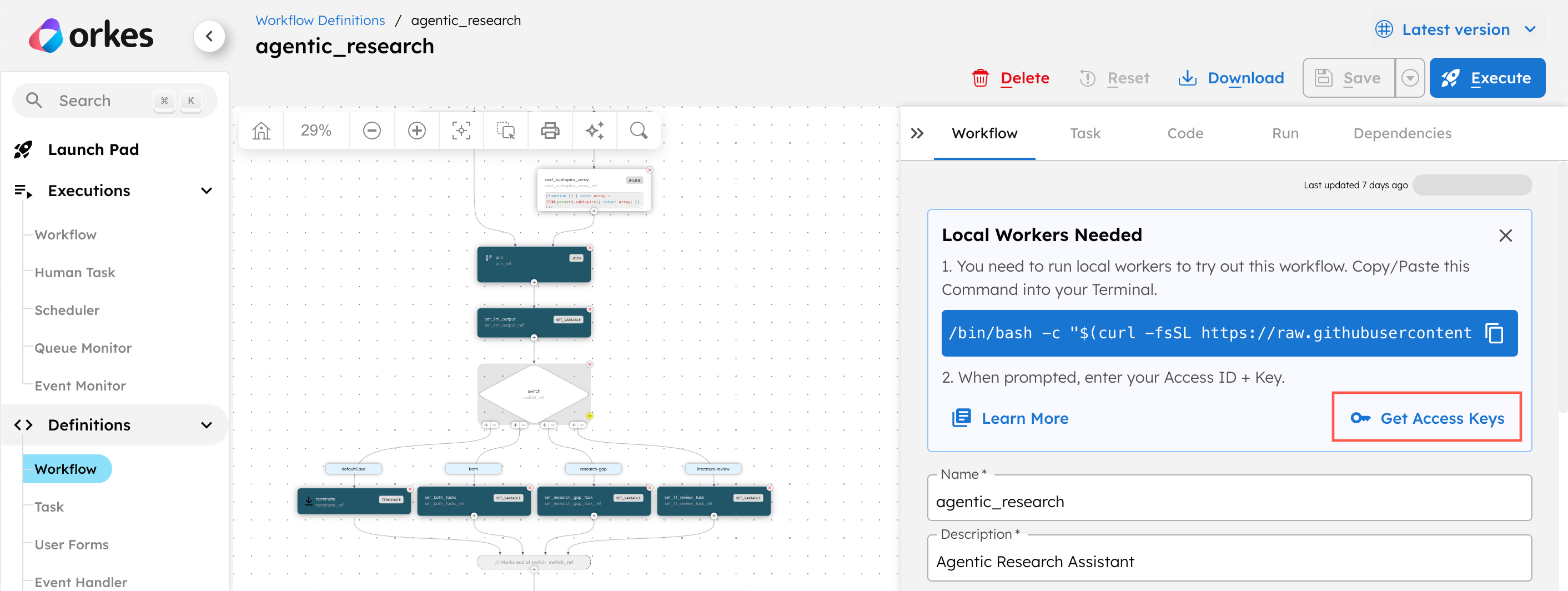
To retrieve the access credentials:
-
Go to Definitions > Workflow and select the
agentic_researchworkflow. -
In the Workflow tab on the right-hand panel, select Get Access Keys.
-
Copy the key ID, secret, and server URL and store them securely.
To set up the worker:
-
Copy the following command into your terminal:
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/conductor-oss/awesome-conductor-apps/refs/heads/agent_research_fix_enh/python/agentic_research/workers/install.sh)" -
Enter the access key ID, secret, and server URL into the terminal when prompted.
This initiates and runs the worker.
Step 5: Run the workflow
With the workflow fully set up, give it a run.
To run the workflow:
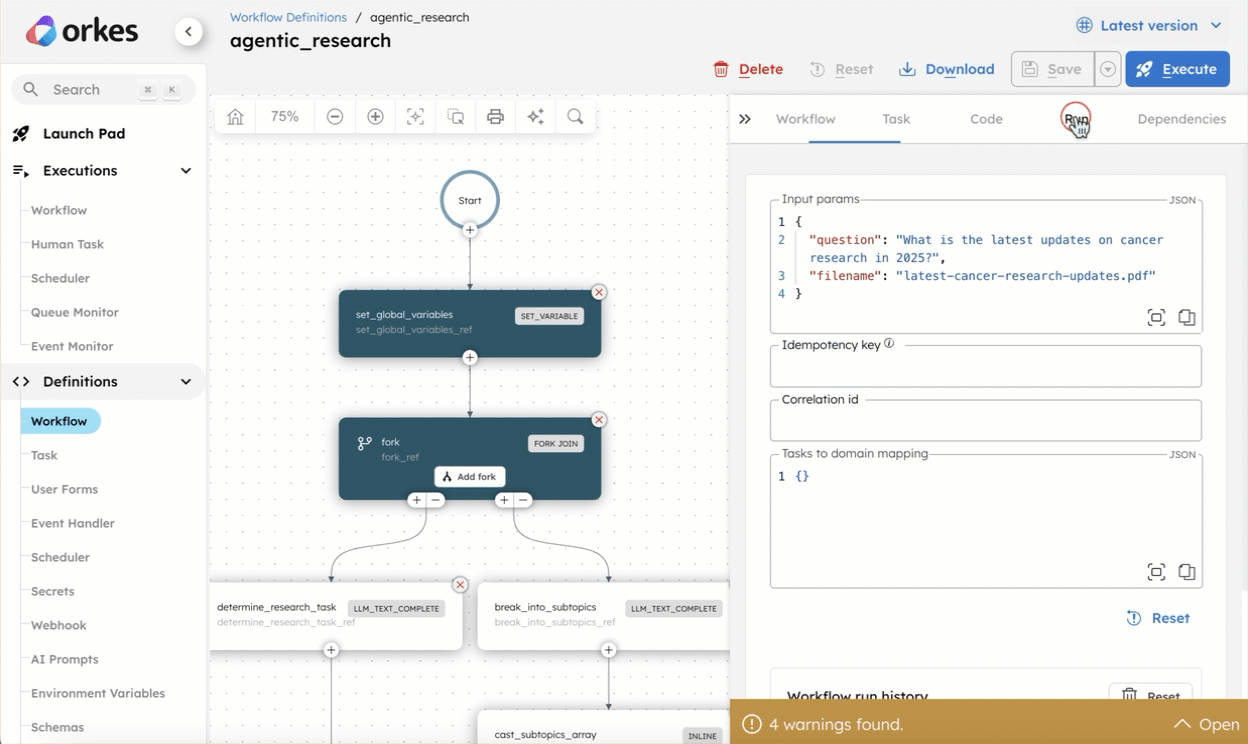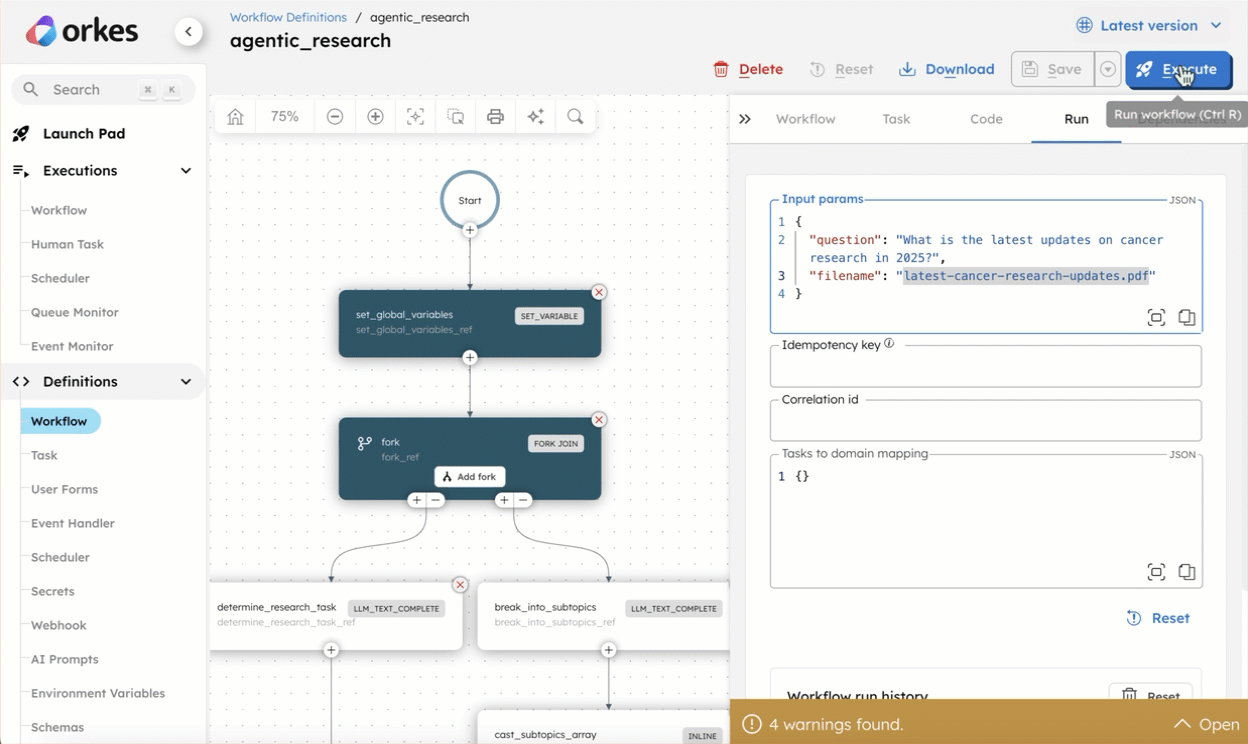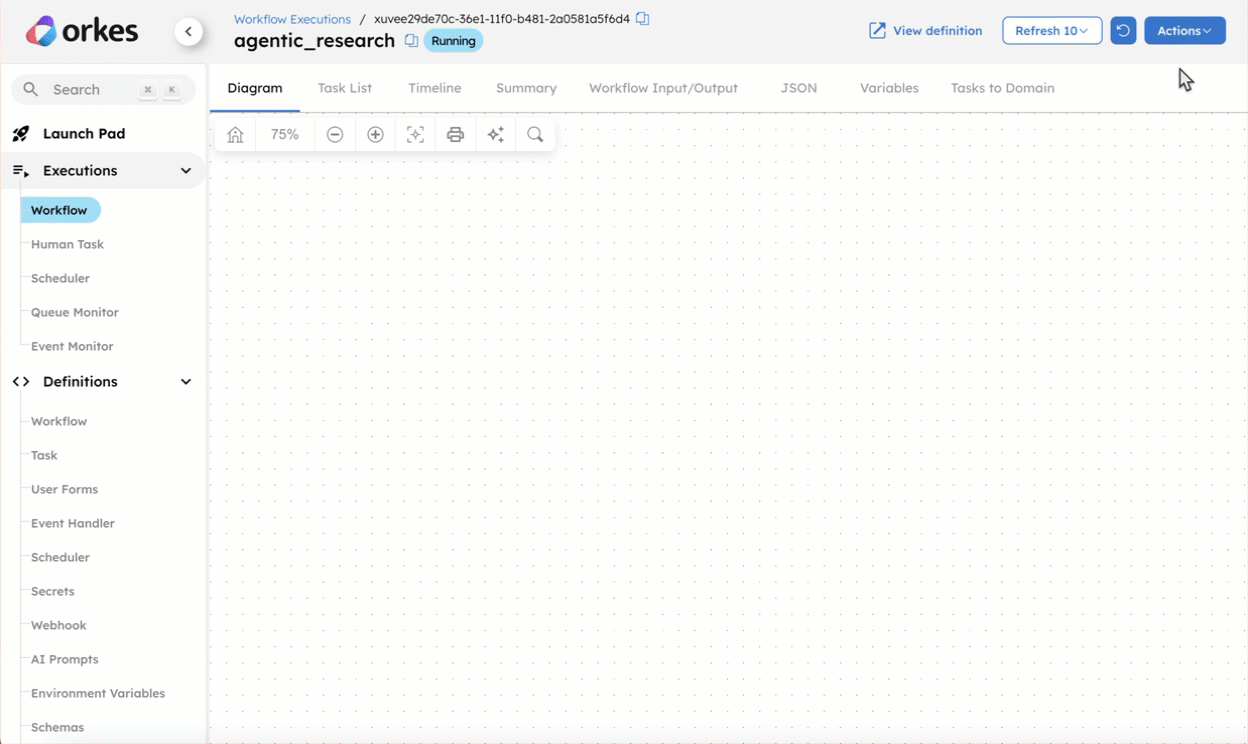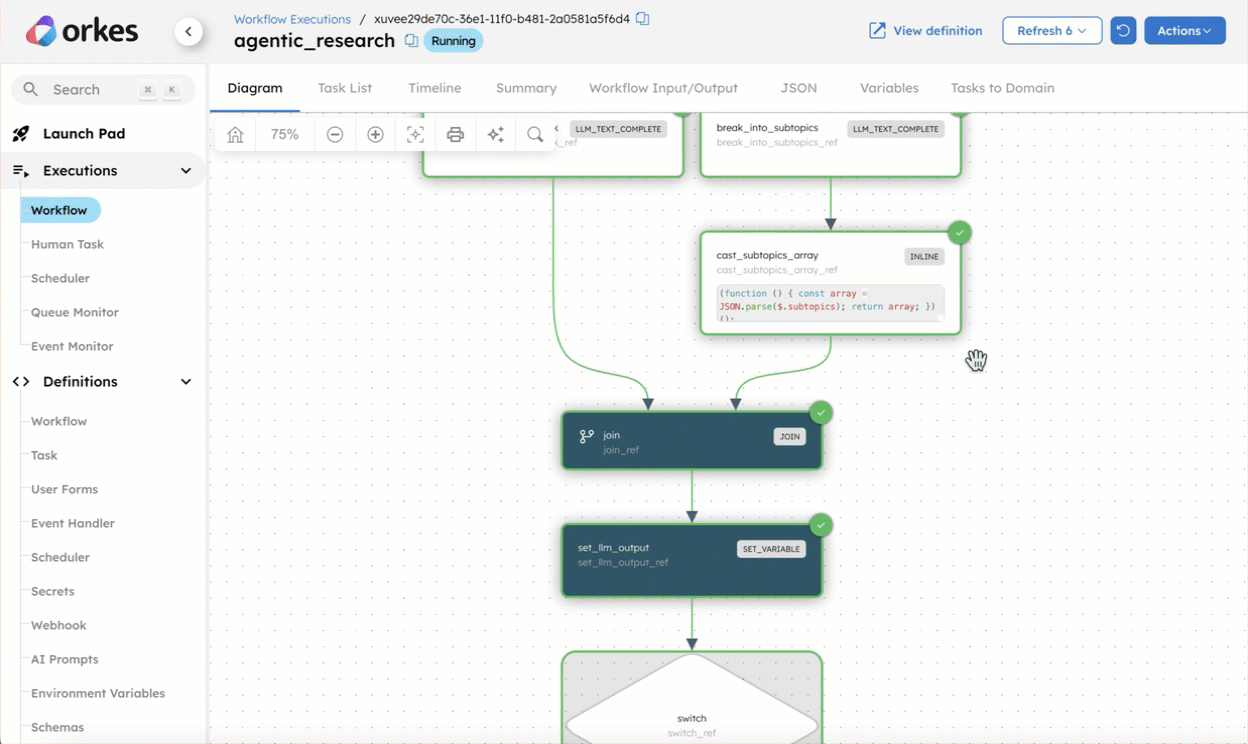
-
From the
agentic_researchworkflow definition, go to the Run tab. -
Enter the Input Params.
Example:
{
"question": "What is the latest updates on cancer research in 2025?",
"filename": "latest-cancer-research-updates.pdf"
} -
Select Execute.
Workflow output
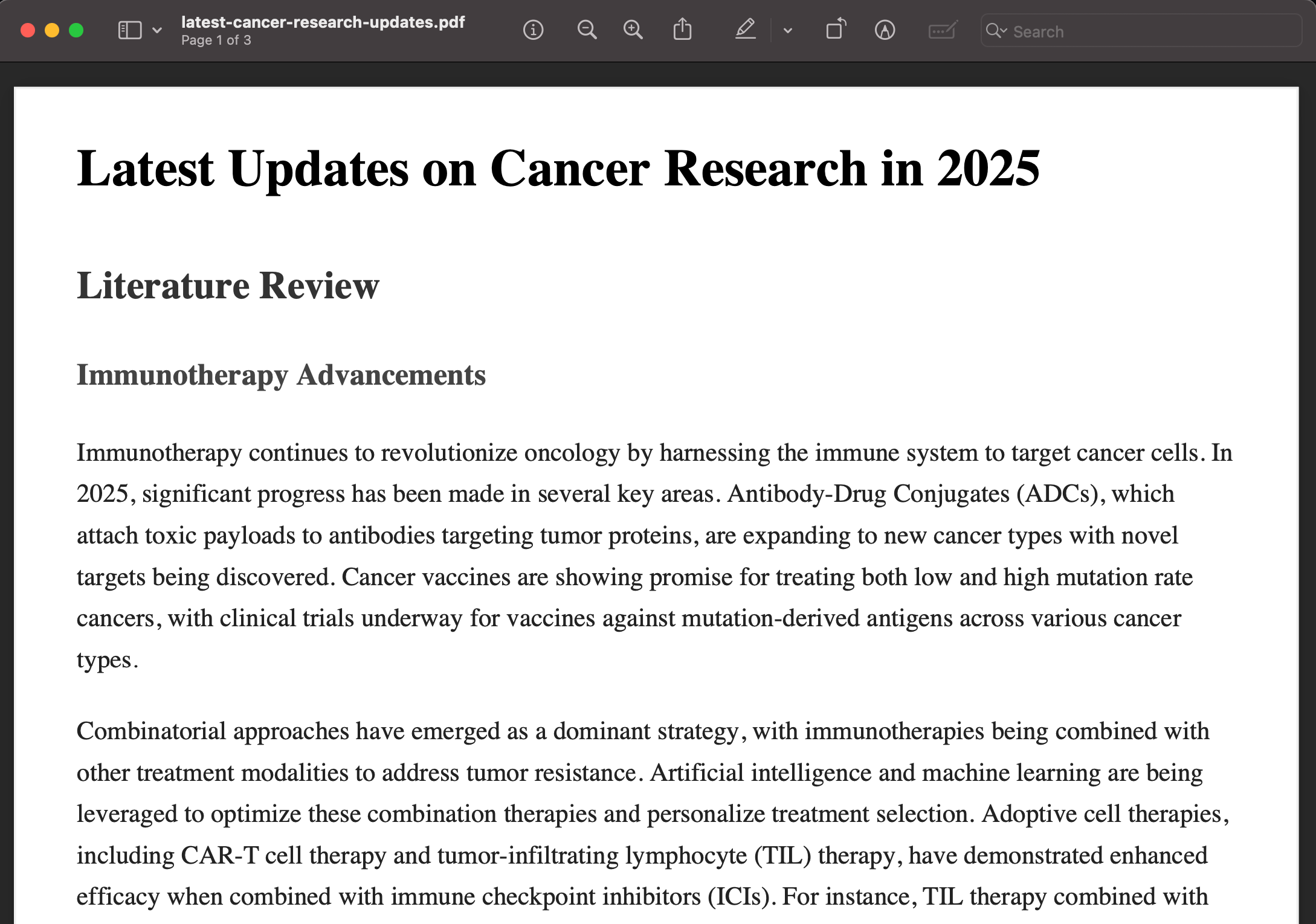
Once the workflow is completed, a .pdf file of the research findings will be downloaded onto your local desktop. You can locate it in /awesome-conductor-apps/python/agentic_research/workers. Open the file to review the research report.
Workflow modifications
This template provides a starting point for customizing the workflow to your needs. You can easily swap out the AI models or modify the AI prompts for better results.
When switching out the AI models, you must modify both the workflow LLM Text Complete task and its corresponding AI prompts before running the workflow.