Chunk Text
- v5.2.38 and later
The Chunk Text task is used to divide text into smaller segments (chunks) based on the document type. This task is useful for processing large text inputs in parts, such as preparing content for semantic search, text embedding, or summarization.
During execution, the task determines the chunking logic based on the specified document type and splits the text into segments of the defined size. Each chunk is returned as an array element and can be processed by subsequent tasks in the workflow.
Task parameters
Configure these parameters for the Chunk Text task.
| Parameter | Description | Required/ Optional | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| inputParameters.text | The input text to be divided into chunks. | Required. | ||||||||
| inputParameters.chunkSize | The maximum number of characters per chunk. Enter a value between 100 and 10,000 characters. The default and recommended value is 1,024. Note that tokens are approximately 4 characters, so a chunk size of 1,024 characters is roughly 256 tokens. Ensure the chunk size stays within the context window of your embedding or downstream model. | Required. | ||||||||
| inputParameters.mediaType | The document type or content format of the input text. Supported values include:
| Required. |
The following are generic configuration parameters that can be applied to the task and are not specific to the Chunk Text task.
Caching parameters
You can cache the task outputs using the following parameters. Refer to Caching Task Outputs for a full guide.
| Parameter | Description | Required/ Optional |
|---|---|---|
| cacheConfig.ttlInSecond | The time to live in seconds, which is the duration for the output to be cached. | Required if using cacheConfig. |
| cacheConfig.key | The cache key is a unique identifier for the cached output and must be constructed exclusively from the task’s input parameters. It can be a string concatenation that contains the task’s input keys, such as ${uri}-${method} or re_${uri}_${method}. | Required if using cacheConfig. |
Other generic parameters
Here are other parameters for configuring the task behavior.
| Parameter | Description | Required/ Optional |
|---|---|---|
| optional | Whether the task is optional. If set to true, any task failure is ignored, and the workflow continues with the task status updated to COMPLETED_WITH_ERRORS. However, the task must reach a terminal state. If the task remains incomplete, the workflow waits until it reaches a terminal state before proceeding. | Optional. |
Task configuration
This is the task configuration for a Chunk Text task.
{
"name": "chunk_text_task",
"taskReferenceName": "chunkText",
"inputParameters": {
"text": "<YOUR-TEXT-HERE>",
"chunkSize": 1024,
"mediaType": "auto"
},
"type": "CHUNK_TEXT"
}
Task output
The Chunk Text task will return the following parameters.
| Parameter | Description |
|---|---|
| text | An array of chunked text segments. Each element in the array represents one chunk of the original text. |
Adding a Chunk Text task in UI
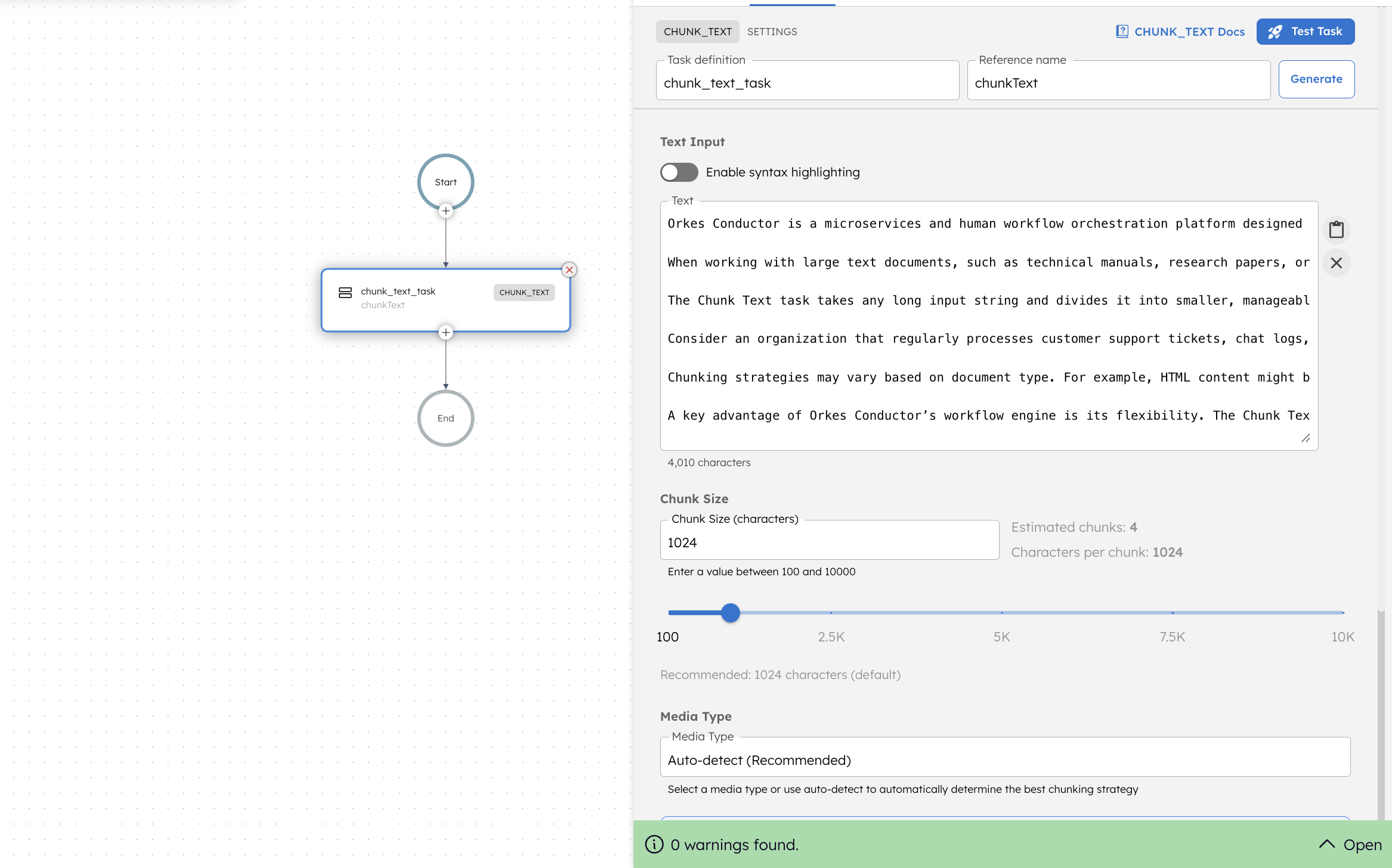
To add a Chunk Text task:
- In your workflow, select the (+) icon and add a Chunk Text task.
- In the Text Input field, enter or paste the text you want to chunk. The field displays a character counter below the input box.
- Optionally Enable syntax highlighting if your text contains code.
- In Chunk Size, specify the maximum number of characters per chunk (100-10,000). The slider helps select the chunk size range visually. The UI also displays the Estimated chunks and Characters per chunk based on the input.
- In Media Type, select a document format or choose Auto-detect (Recommended) to automatically determine the best chunking strategy.
Examples
Here are some examples for using the Chunk Text task.
Using Chunk Text task
To illustrate the use of the Chunk Text task in a workflow, consider a workflow that splits a long paragraph into smaller text chunks for downstream processing, such as embedding generation or summarization.
To create a workflow definition using Conductor UI:
- Go to Definitions > Workflow, from the left navigation menu on your Conductor cluster.
- Select + Define workflow.
- In the Code tab, paste the following code:
Workflow definition:
{
"name": "test_chunk_text",
"description": "Workflow to test the Chunk Text task",
"version": 1,
"tasks": [
{
"name": "chunk_text_task",
"taskReferenceName": "chunkText",
"inputParameters": {
"text": "Orkes Conductor is a microservices and human workflow orchestration platform designed to handle large-scale, distributed systems. It enables developers to model complex business processes as workflows and coordinate microservices, APIs, and human tasks seamlessly. Each workflow is made up of tasks that represent discrete units of work — such as invoking an HTTP endpoint, transforming JSON data, running scripts, or waiting for an event.\n\nWhen working with large text documents, such as technical manuals, research papers, or structured reports, it becomes challenging to process the entire content as a single block. For instance, AI models for embedding or summarization have token limits, and indexing systems perform better with smaller, coherent text segments. This is where the Chunk Text task becomes essential.\n\nThe Chunk Text task takes any long input string and divides it into smaller, manageable parts known as chunks. These chunks can then be processed independently, allowing downstream systems to parallelize operations like embedding generation, semantic search, summarization, and topic modeling. Each chunk maintains contextual integrity — sentences are preserved as much as possible without abrupt splits.\n\nConsider an organization that regularly processes customer support tickets, chat logs, or product manuals. Instead of sending an entire 200-page manual to a model for vector embedding, the document can first be divided into smaller pieces. These pieces can be processed in parallel, leading to faster performance and improved accuracy when querying or retrieving information.\n\nChunking strategies may vary based on document type. For example, HTML content might be chunked by paragraph tags, PDF files by section boundaries, and plain text by sentence delimiters. Auto-detect mode in the Chunk Text task simplifies this by analyzing structure and applying the most appropriate chunking logic automatically.\n\nA key advantage of Orkes Conductor’s workflow engine is its flexibility. The Chunk Text task can be combined with other tasks to create complete data-processing pipelines. For instance, after chunking, a workflow might include tasks to generate embeddings using an external AI service, store them in a vector database, and trigger an event to notify that preprocessing is complete.\n\nOrkes Conductor also supports caching mechanisms that can store chunking results for repeated inputs. This avoids unnecessary reprocessing when dealing with the same document multiple times, saving both computation time and resources.\n\nIn addition to technical use cases, chunking can be helpful for creative workflows. Writers and editors can divide long manuscripts or scripts into smaller sections for review. Translation pipelines can process each chunk independently, ensuring consistent context handling and reducing the risk of truncation errors.\n\nBecause the Chunk Text task operates at the workflow layer, it can be inserted anywhere in the orchestration chain — before data enrichment, after retrieval, or in preprocessing stages. It provides an easy way to scale text handling across hundreds or thousands of documents without modifying underlying microservices.\n\nThe recommended chunk size for most applications is around 1,024 characters. This size balances context and efficiency, though the ideal value depends on downstream use. Smaller chunks improve precision for fine-grained analysis, while larger chunks preserve broader narrative coherence.\n\nWith Orkes Conductor, such preprocessing workflows can be versioned, tested, and monitored, ensuring consistent results across environments. Developers can view execution metrics, track chunking performance, and visualize how text was divided at runtime.\n\nIn conclusion, the Chunk Text task transforms how large text inputs are processed in orchestration pipelines. Whether for search optimization, AI preprocessing, or content segmentation, it provides a scalable, reliable foundation for handling vast text data efficiently.\n",
"chunkSize": 1024,
"mediaType": "auto"
},
"type": "CHUNK_TEXT"
}
],
"schemaVersion": 2
}
- Select Save > Confirm.
Let’s execute the workflow using the Execute button.
When executed, this workflow receives a long text input and divides it into smaller chunks based on the defined parameters. With mediaType set to auto, the task automatically applies a natural language-based chunking strategy.
It scans the text until the chunkSize limit (1,024 characters) is reached, ensuring sentences and paragraphs remain intact. Each segment is then returned as an element in the text array, allowing downstream tasks to process the chunks independently.
After successful execution, the Chunk Text task produces the following output:
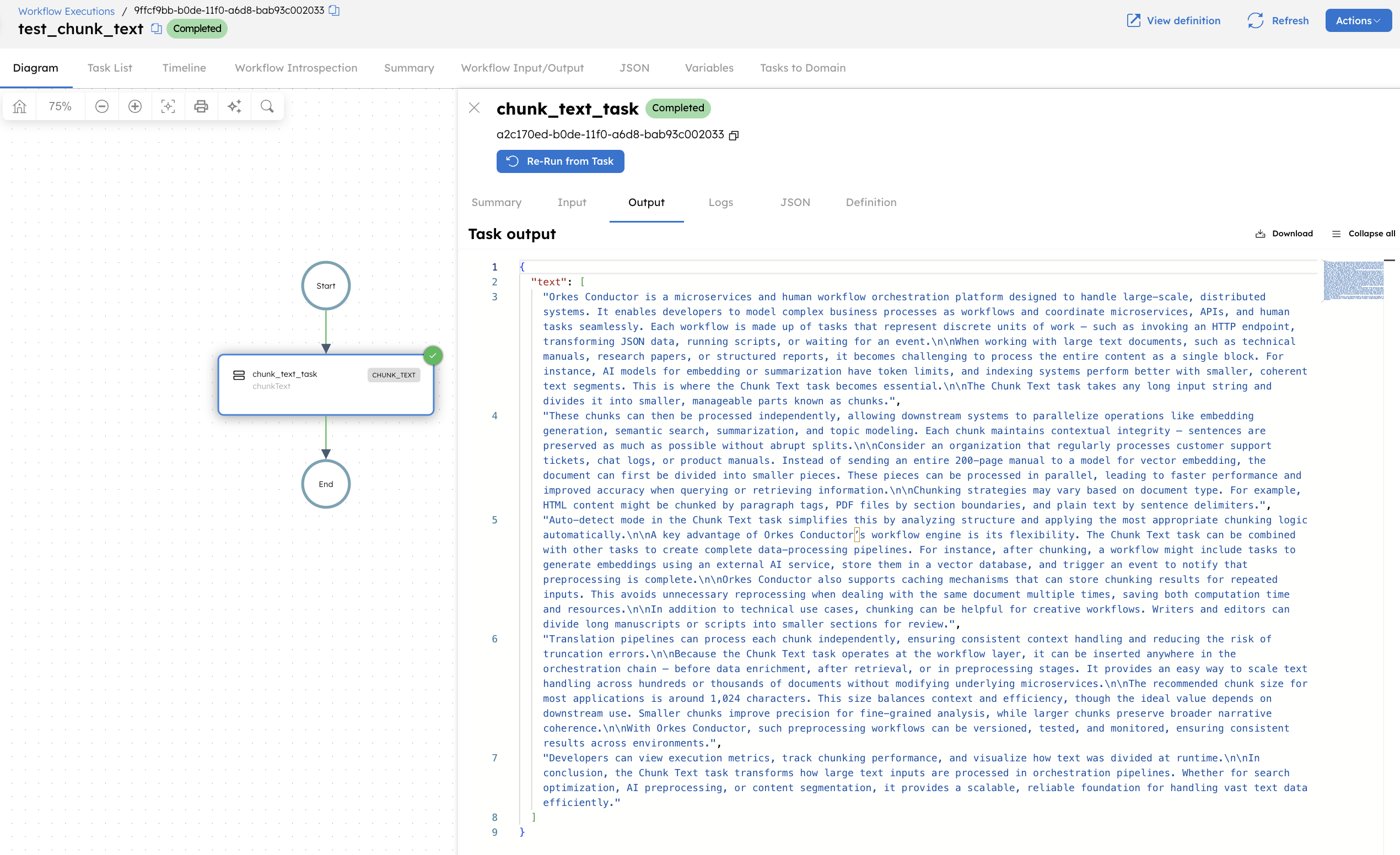
The task output contains a key named text, which stores an array of five chunks. Each chunk represents approximately 1,000–1,200 characters of the original text.