







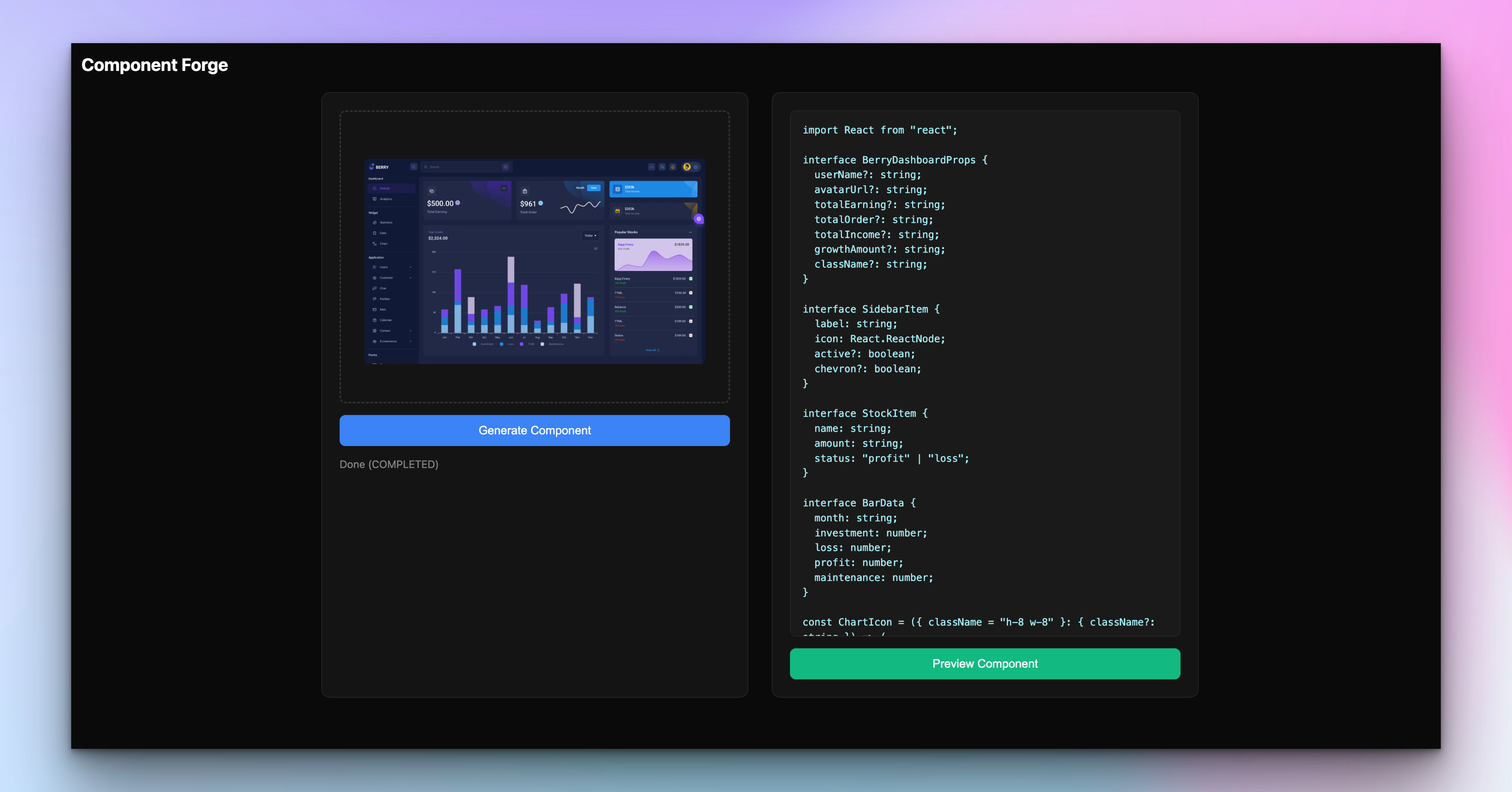
Featured Blog
How to Build a UI Screenshot-to-Code AI Agent
Build an AI agent that turns UI screenshots into working React + TypeScript components. Drop in a design, get back clean, Tailwind-styled code in seco...

ALL, ENGINEERING
What Is Loop Engineering?
July 5, 2026
Loop engineering is building a loop around your agent so the agent can reprompt itself without you needing to do it. but you still need to keep yourse...
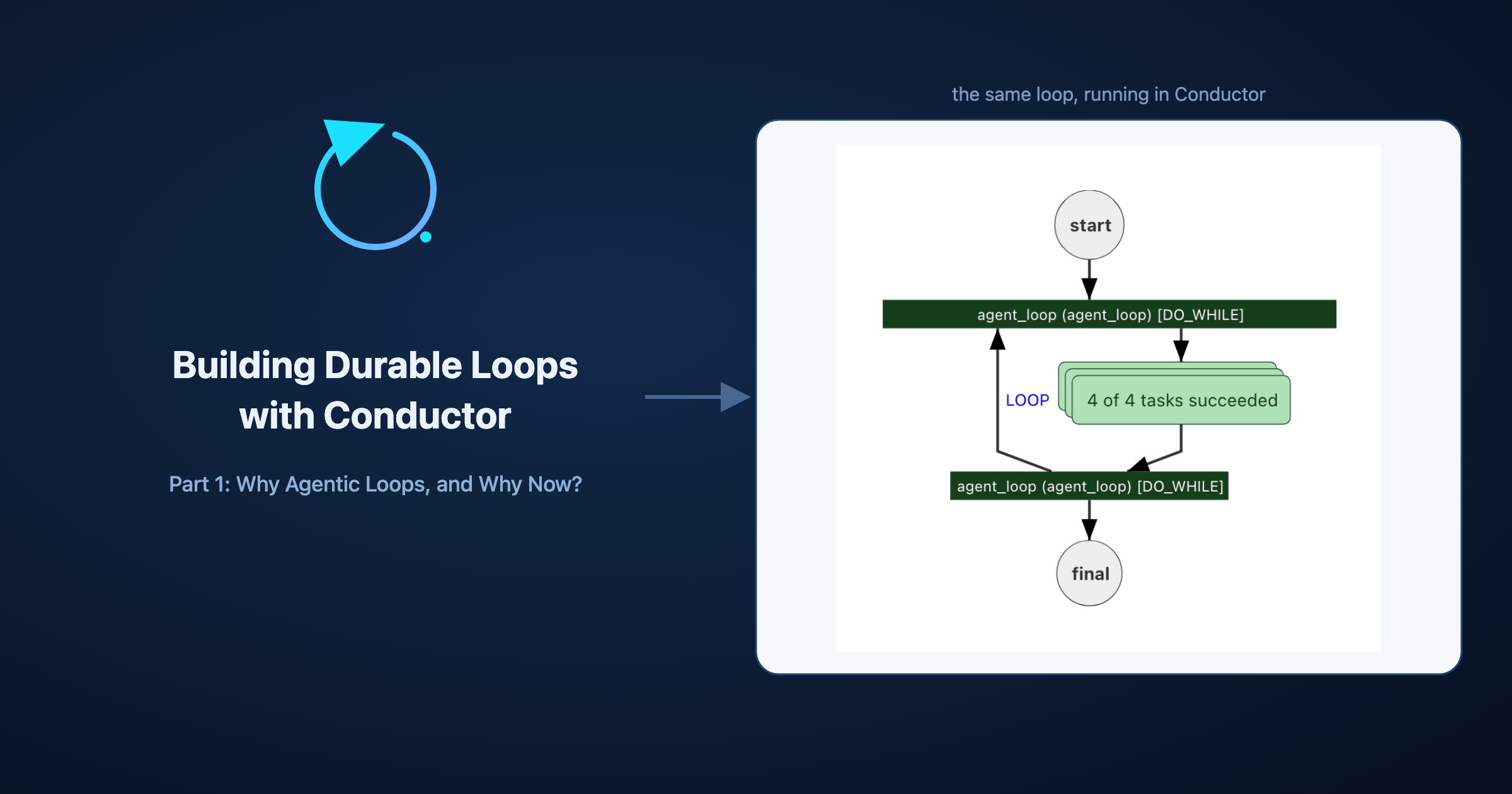
AGENTIC, ENGINEERING, INSIGHTS
Building Durable Loops with Conductor, Part 1: Why Agentic Loops, and Why Now?
June 30, 2026
Part one of a series on durable loops. Why agentic systems are loops, why naive loops fail as tasks get longer, and what makes a loop durable, grounde...
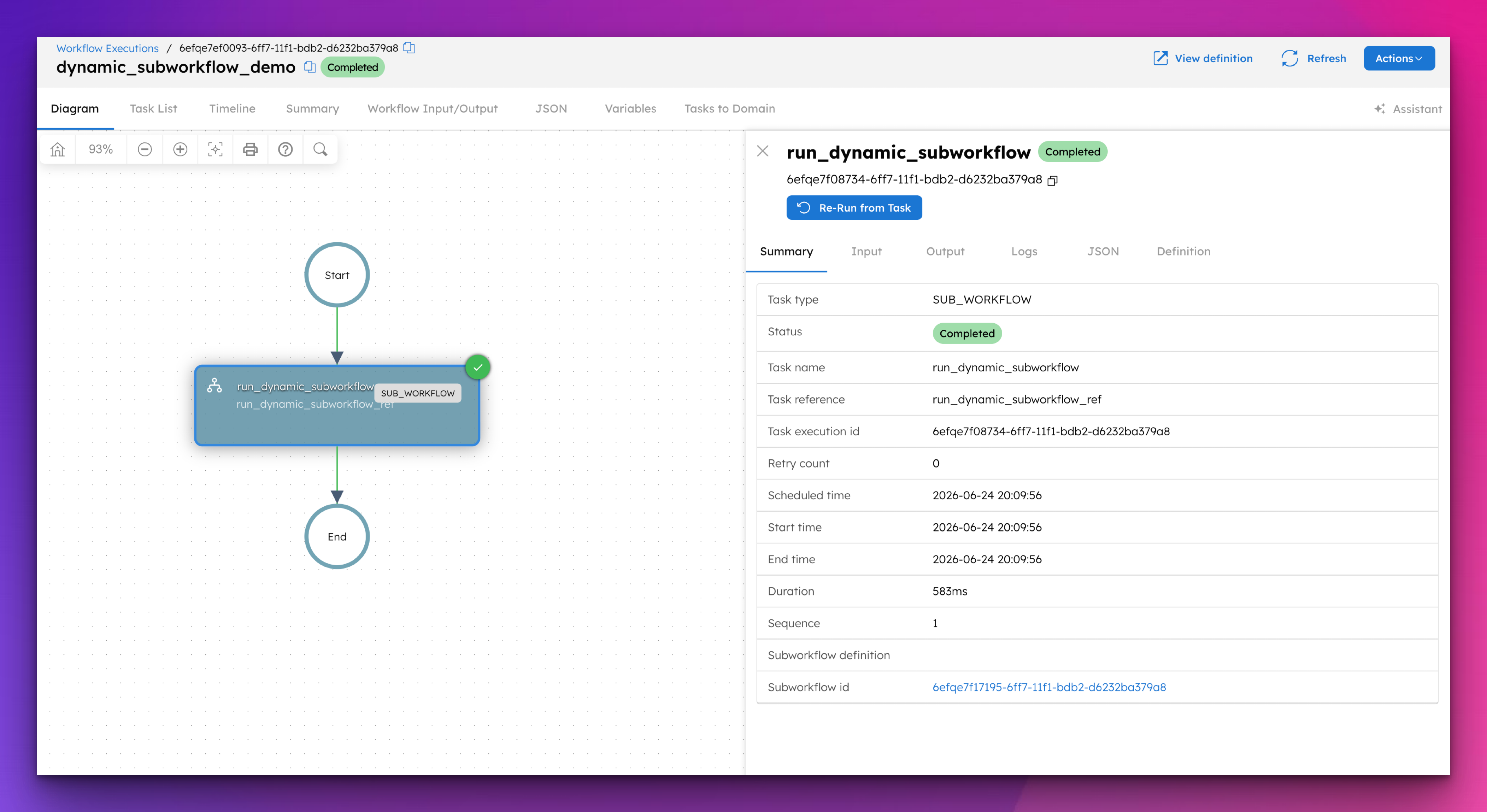
ALL, ENGINEERING
How to Reuse Workflows Inside Other Workflows in Orkes Conductor
June 24, 2026
Every time you copy workflow logic into a new workflow, you create a maintenance problem. Here's how the Sub Workflow task solves it....
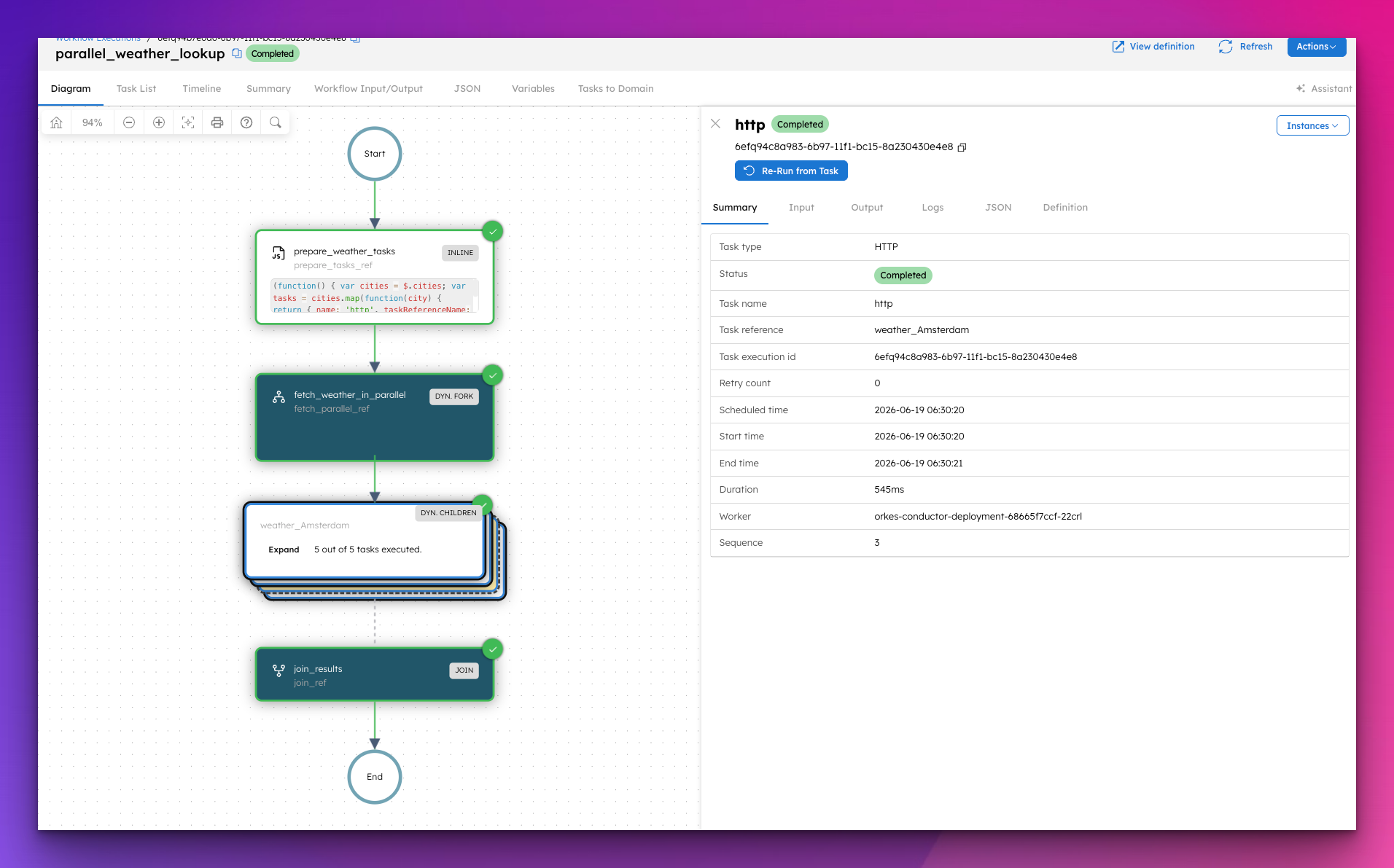
ALL, ENGINEERING
How to Process a List of Items in Parallel in Orkes Conductor
June 20, 2026
You have a workflow that needs to process a list of items and doing them one by one is too slow. Here's how the DYNAMIC_FORK task solves it....
ALL, ENGINEERING
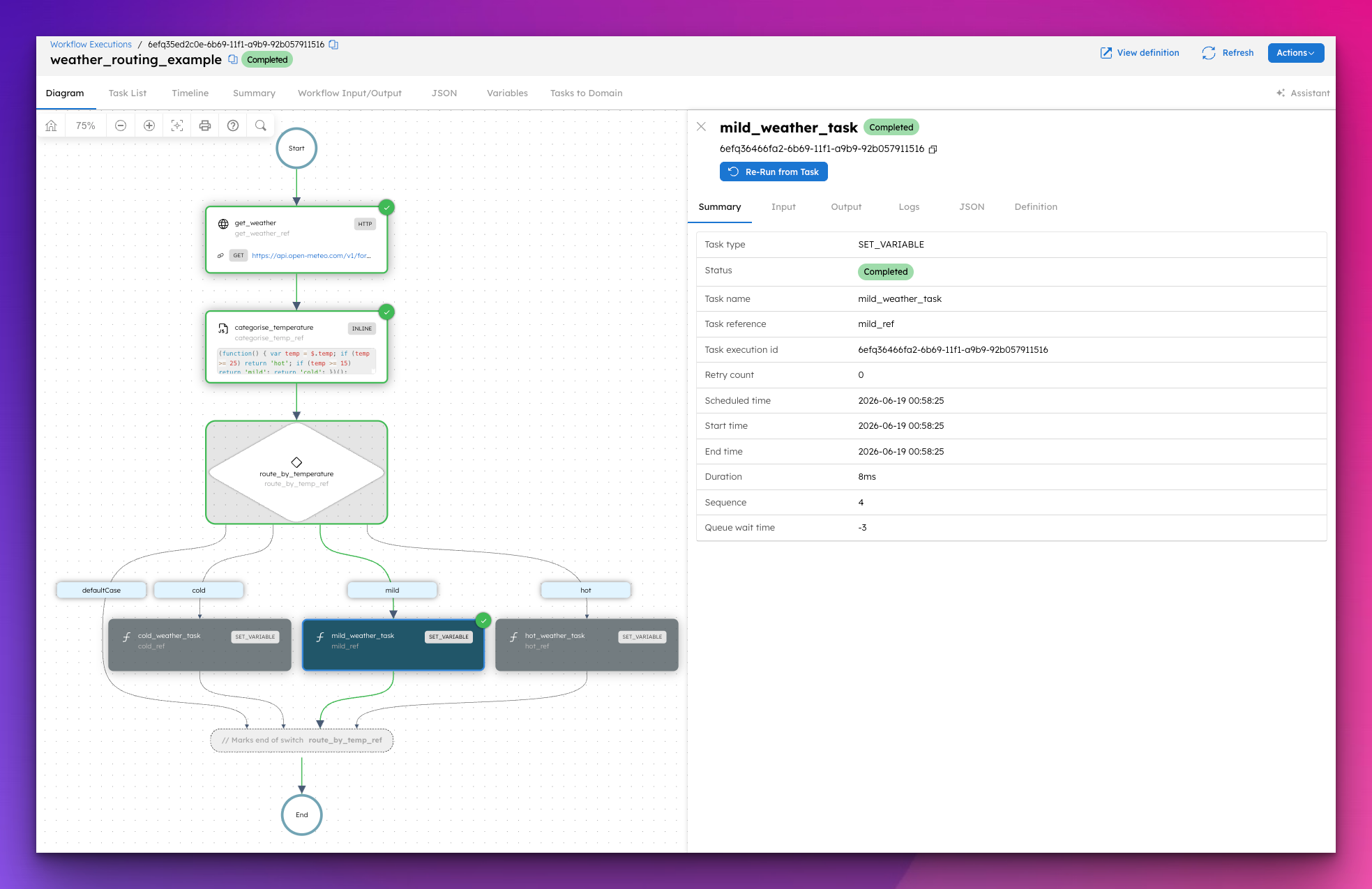
How to Add Conditional Branching to Your Workflows in Orkes Conductor
June 18, 2026
You have a workflow that needs to take a different path based on a score, a status, or a region. The last thing you want to do is build that routing l...
ALL, ENGINEERING
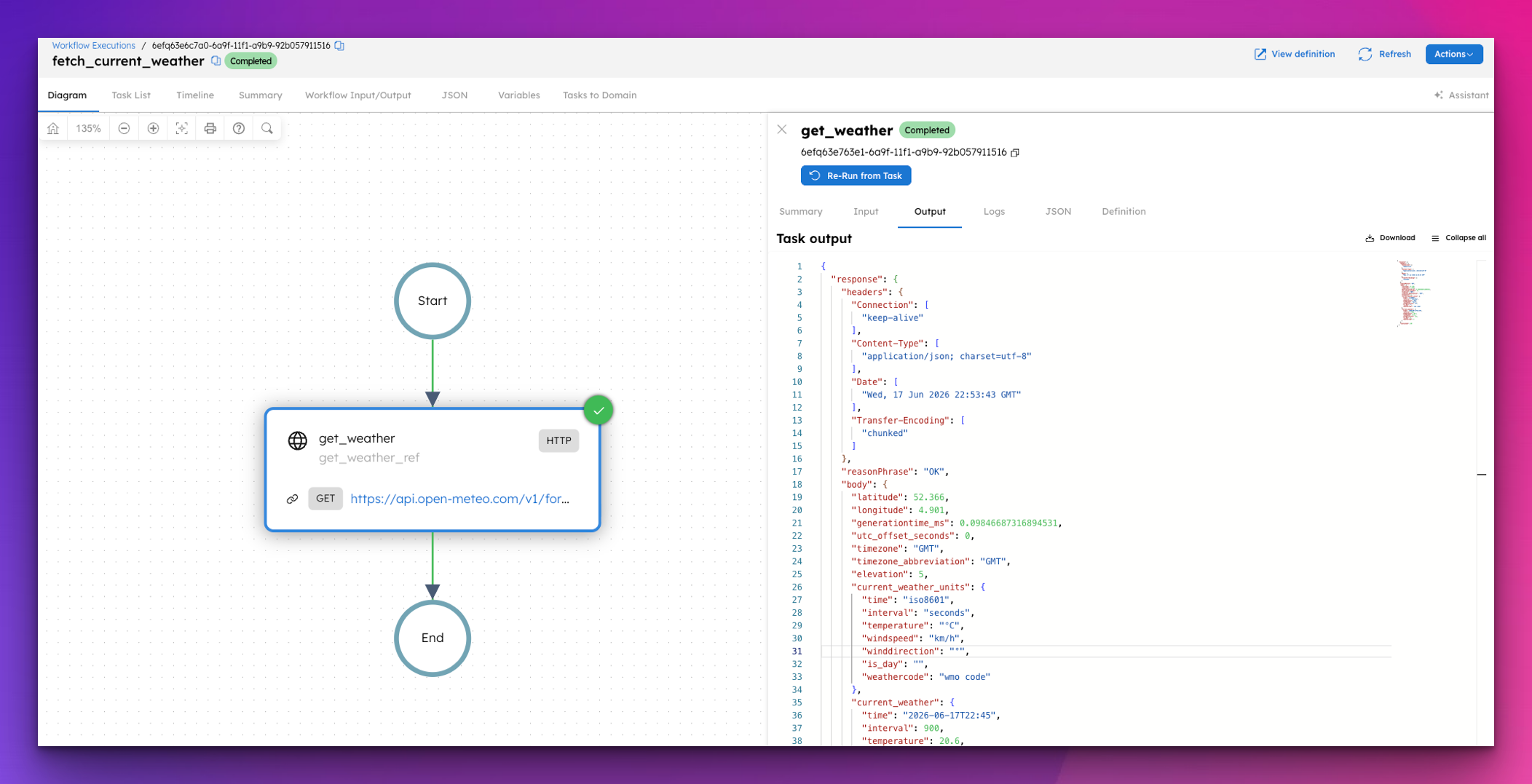
How to Call Any External API From a Workflow in Orkes Conductor
June 17, 2026
Most workflows need to talk to the outside world at some point. Here's how Conductor's built-in HTTP task handles API calls, webhooks, and external se...
ALL, ENGINEERING
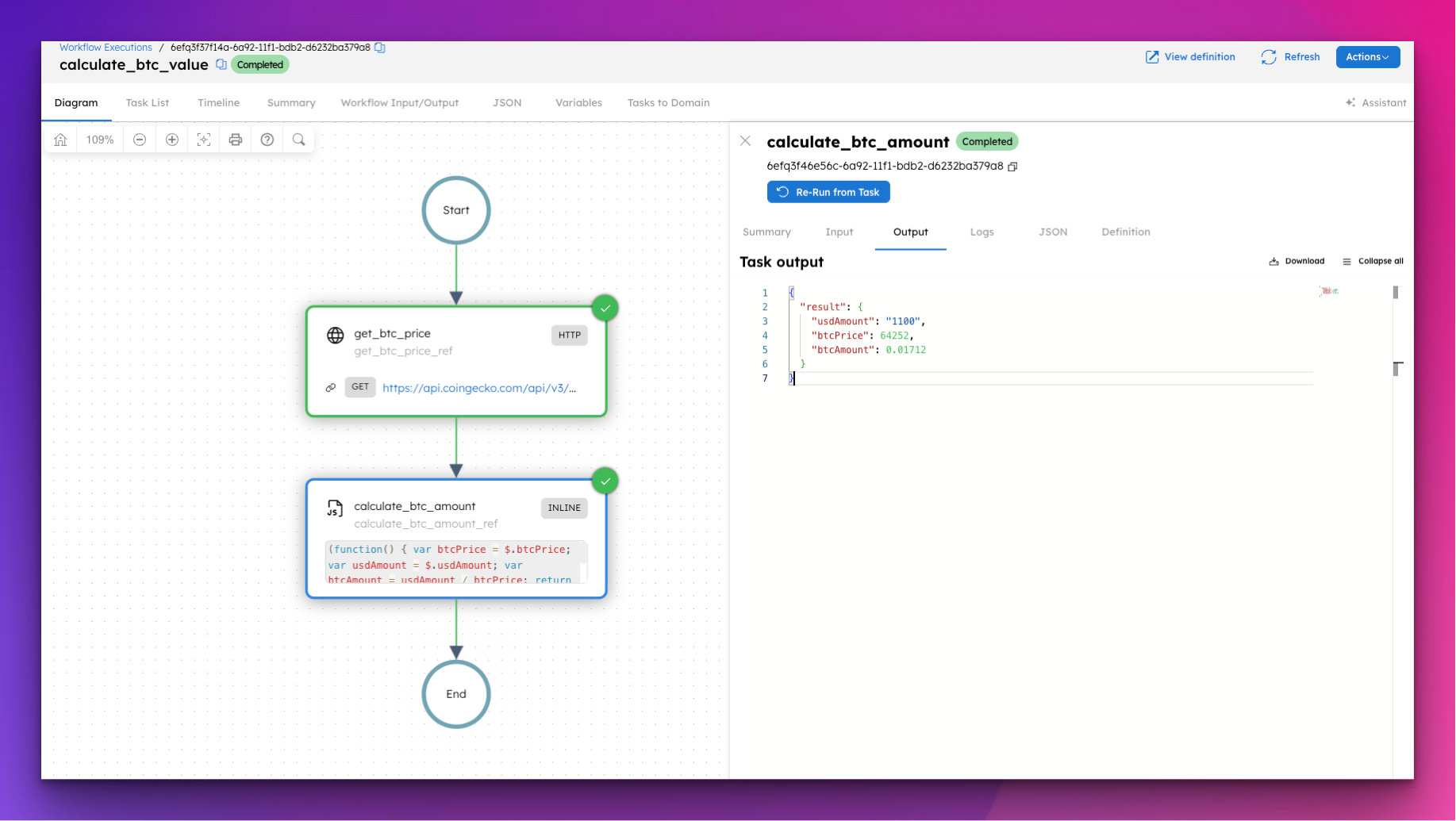
How to Run Custom Logic in Your Workflows Without Writing a Custom Worker
June 16, 2026
You have a workflow that needs to calculate a price, apply a business rule, or format a string. The last thing you want to do is deploy a whole servic...
ALL, ENGINEERING
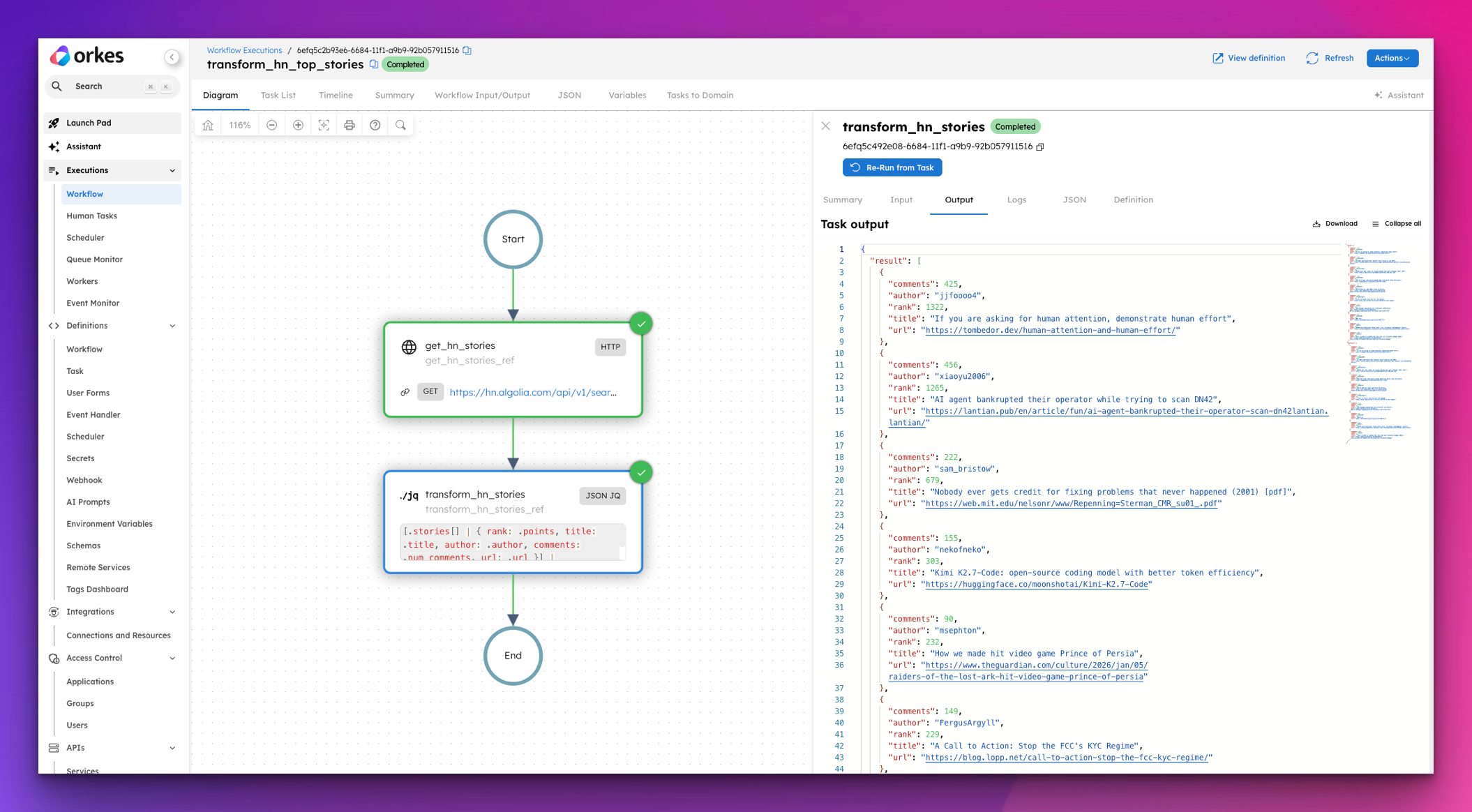
How to Transform JSON in Orkes Conductor Without Writing Custom Code
June 11, 2026
Stop writing custom workers just to transform JSON. Here's how Conductor's built-in JSON_JQ_TRANSFORM task handles reshaping, filtering, and merging i...
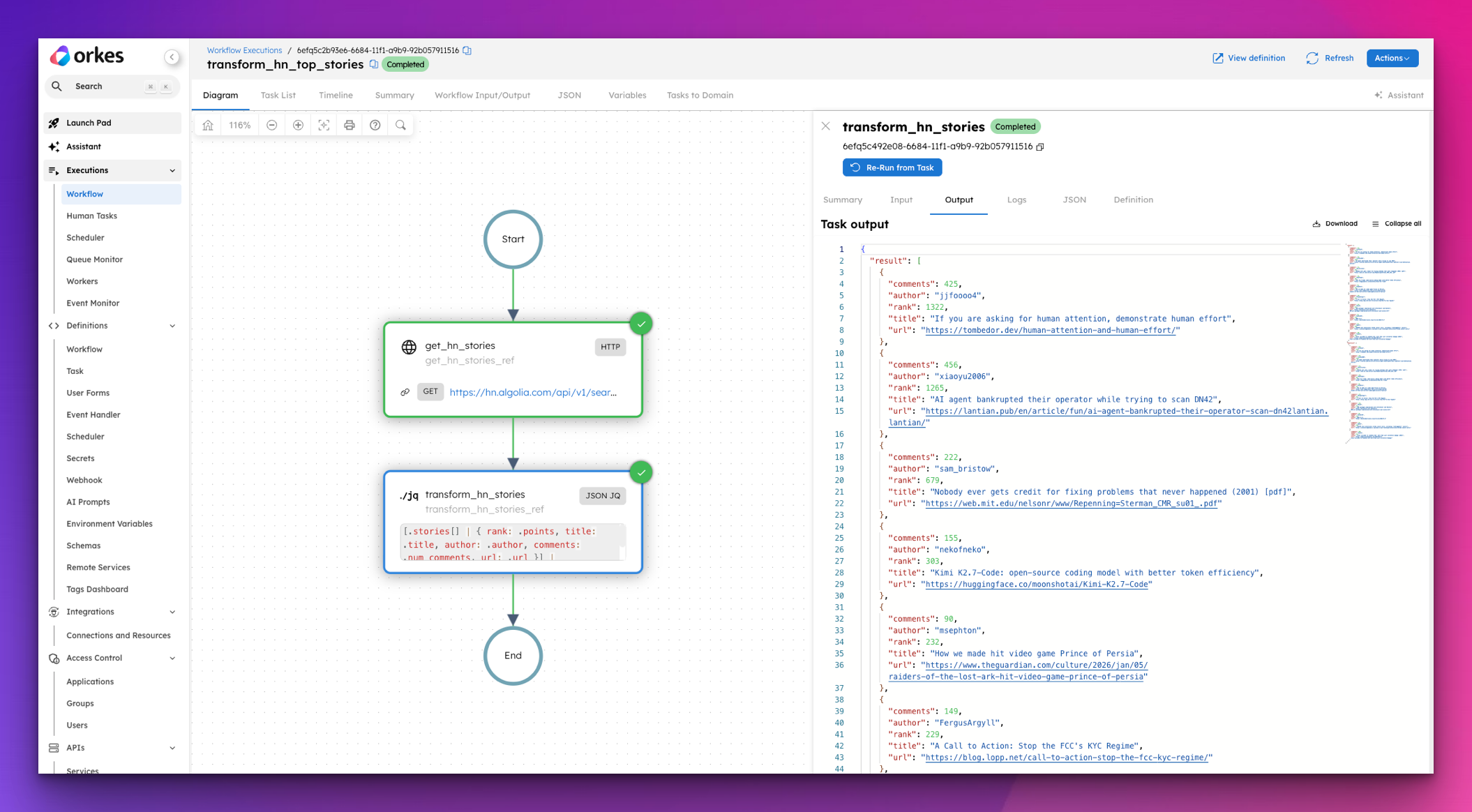
ALL, ENGINEERING
Stop Building This Yourself: JSON_JQ_TRANSFORM
June 11, 2026
Stop writing custom workers just to transform JSON. Here's how Conductor's built-in JSON_JQ_TRANSFORM task handles reshaping, filtering, and merging i...
Ready to Build Something Amazing?
Join thousands of developers building the future with Orkes.