







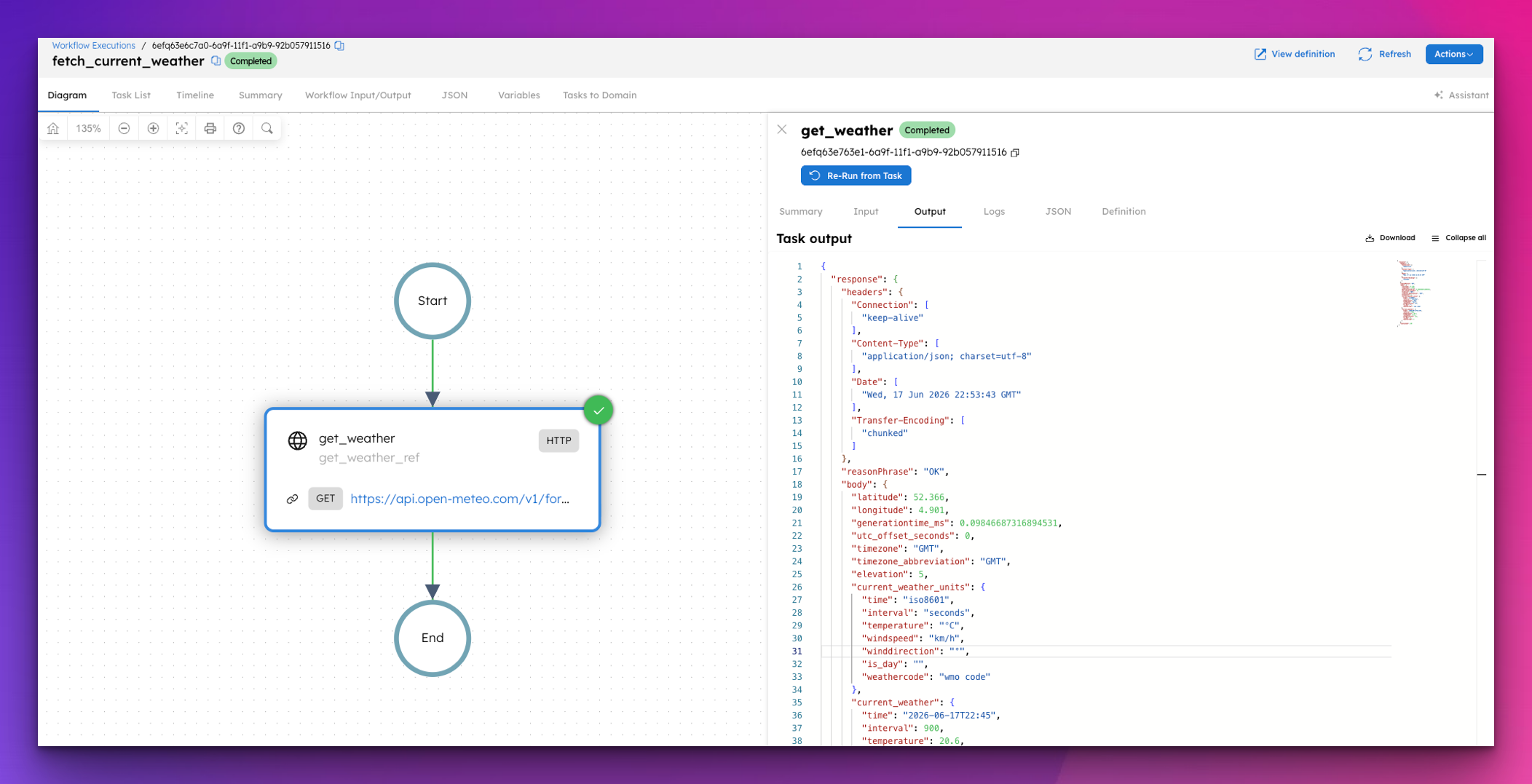
Featured Blog
How to Call Any External API From a Workflow in Orkes Conductor
Most workflows need to talk to the outside world at some point. Here's how Conductor's built-in HTTP task handles API calls, webhooks, and external se...
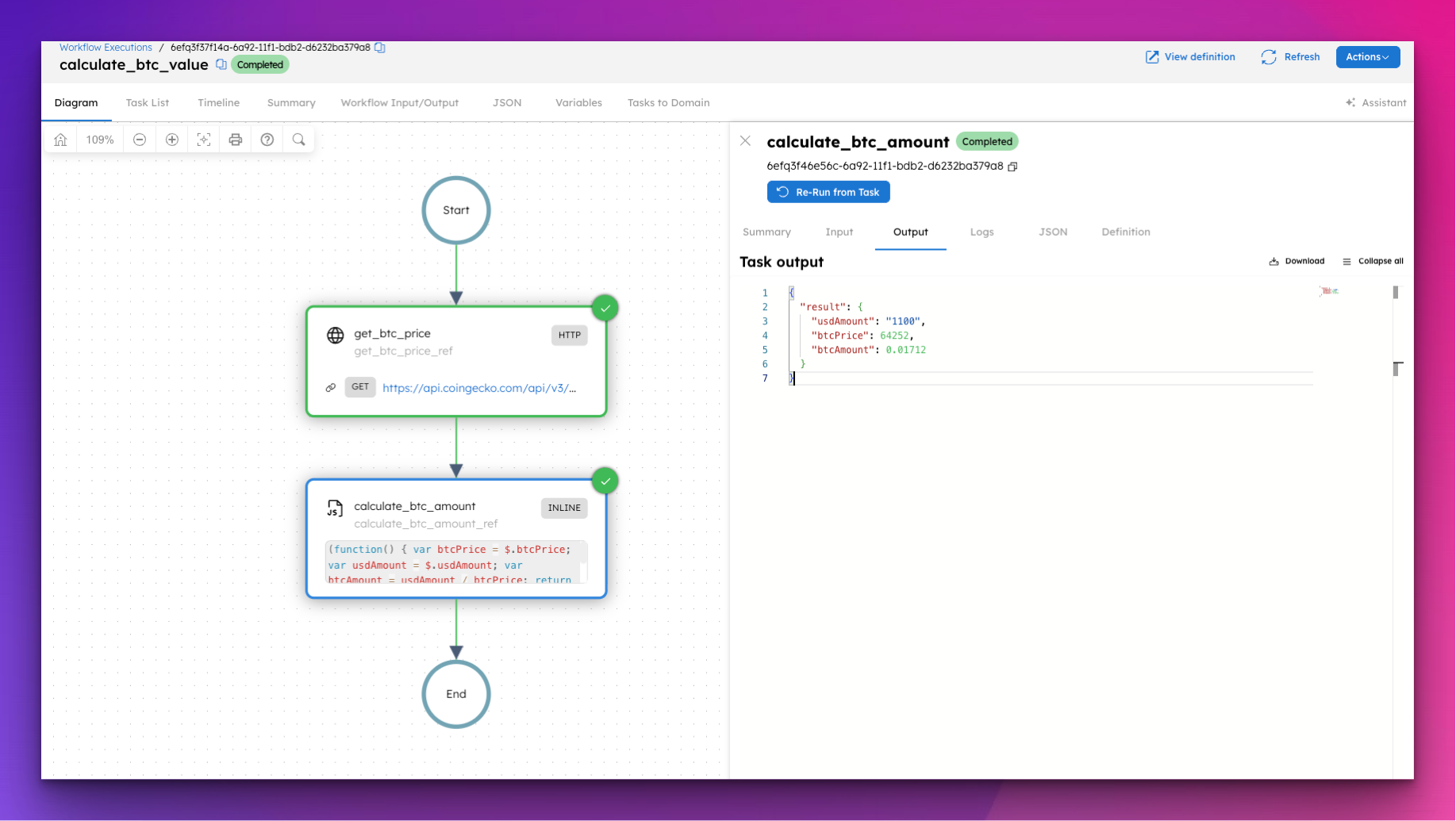
ALL, ENGINEERING
How to Run Custom Logic in Your Workflows Without Writing a Custom Worker
June 16, 2026
You have a workflow that needs to calculate a price, apply a business rule, or format a string. The last thing you want to do is deploy a whole servic...
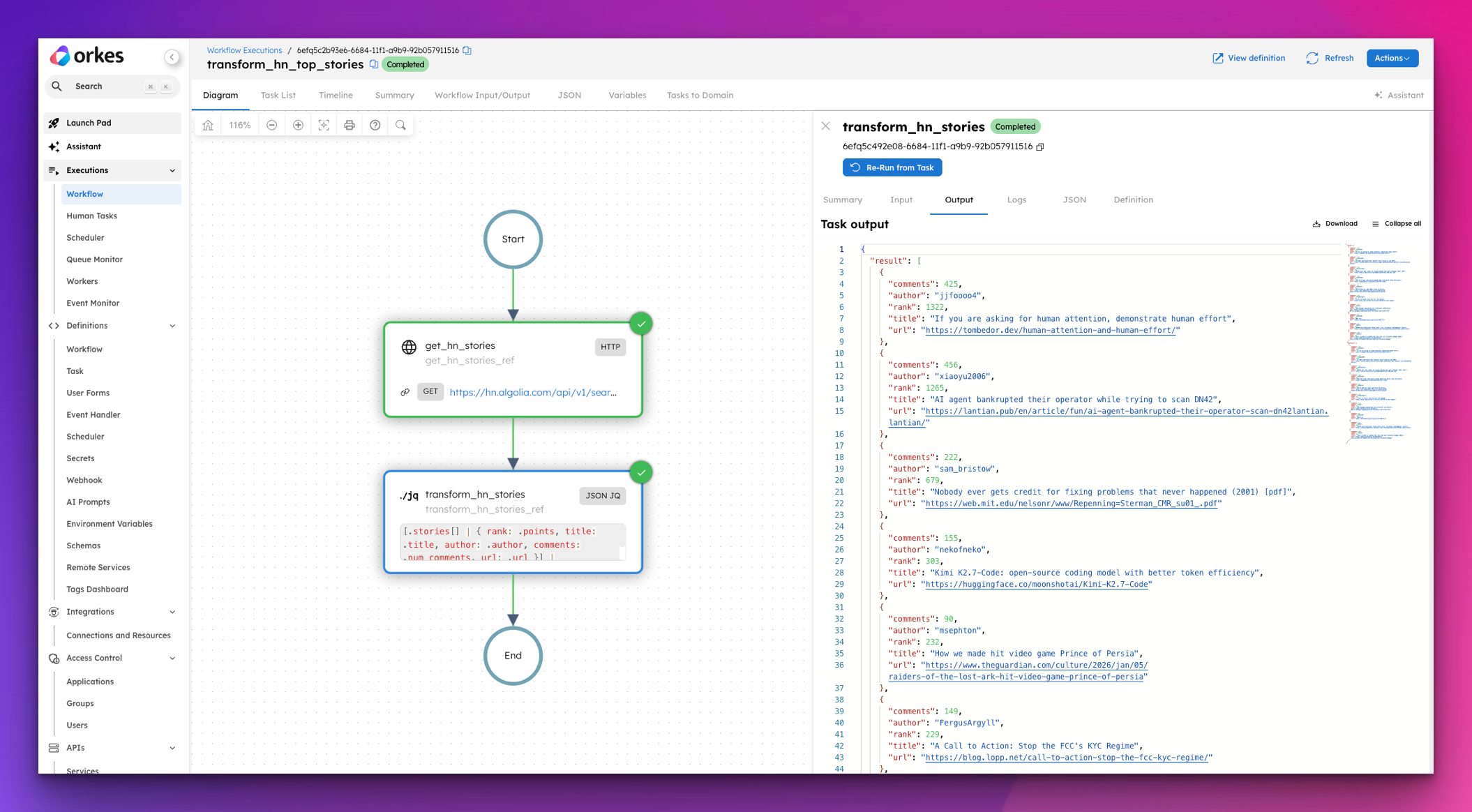
ALL, ENGINEERING
How to Transform JSON in Orkes Conductor Without Writing Custom Code
June 11, 2026
Stop writing custom workers just to transform JSON. Here's how Conductor's built-in JSON_JQ_TRANSFORM task handles reshaping, filtering, and merging i...
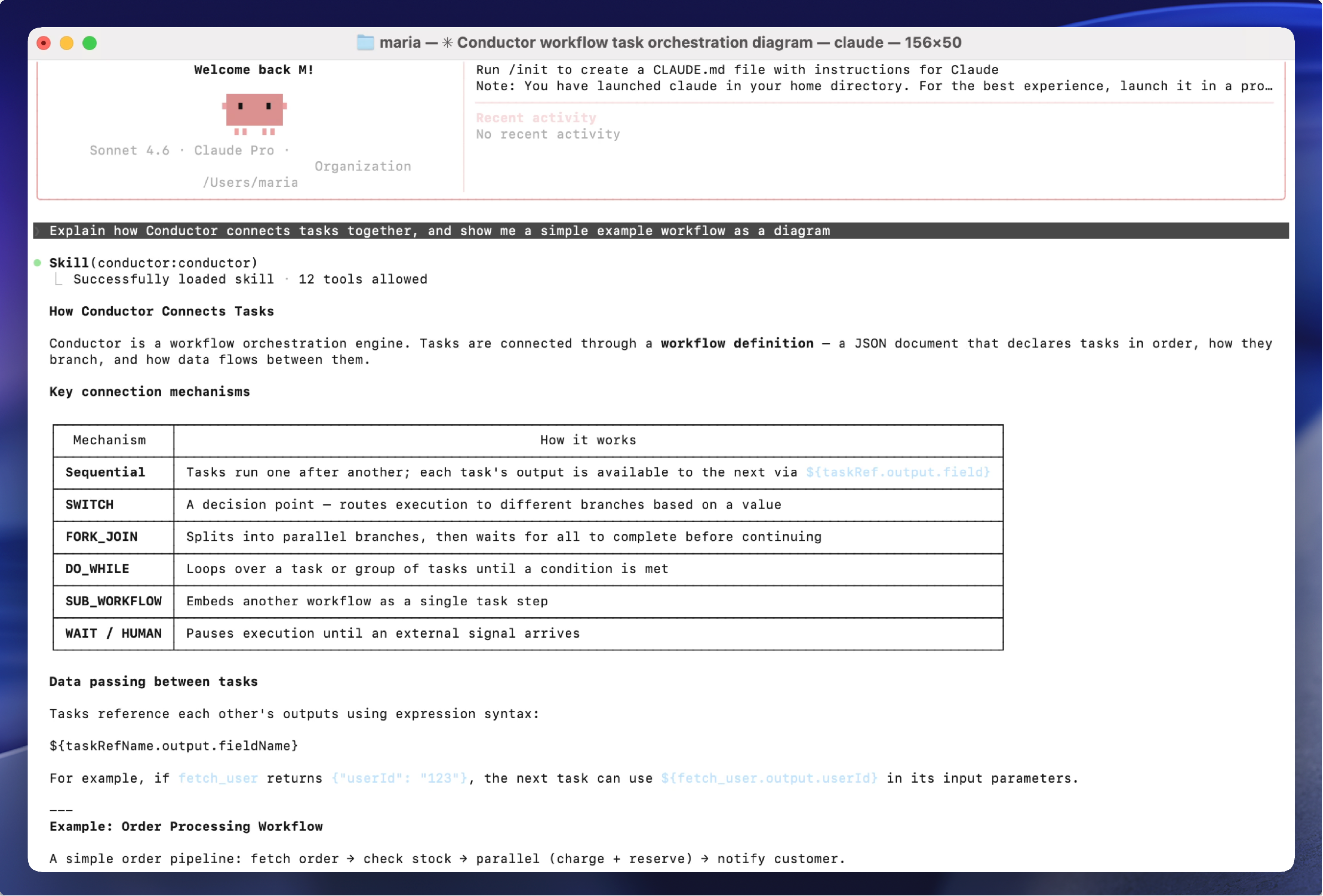
ALL, AGENTIC, ENGINEERING
How We Taught Claude, Cursor, and Copilot to Build Agentic Workflows
May 29, 2026
How conductor-skills teaches any AI coding agent—Claude Code, Cursor, Copilot—to create, run, and monitor Conductor workflows without you explaining a...
ALL, AGENTIC, SOLUTIONS
How to Build a Customer Success AI Agent in Python
May 24, 2026
Let’s build a customer success AI agent that can understand customer issues, gather context, and decide what to do next.....
ALL, AGENTIC, ENGINEERING
How to Test Your AI Prompts with Orkes Prompt Studio: Catch Prompt Issues Before They Hit Production
May 18, 2026
A walkthrough for treating prompts as first-class, testable artifacts before they ship inside your agents and workflows....
ALL, AGENTIC, ENGINEERING
I Built an AI Agent That Finds My Forgotten Subscriptions — Here's Exactly How
May 5, 2026
The four building blocks behind every AI agent — LLMs, tools, loops, and memory — and how to connect them up into something durable....
ALL, AGENTIC, ENGINEERING, SOLUTIONS
How to Build a Durable Conductor Workflow using Conductor Skills and Claude Code in Minutes
April 28, 2026
How you can use Claude Code and Conductor Skills to build all of your workflows...

ALL, AGENTIC, ENGINEERING, SOLUTIONS
Conductor CLI Guide: Register, Run, Retry, and Recover Durable Workflows Without Leaving Your Terminal 💻
March 24, 2026
How to install, configure, and use the Conductor CLI to manage workflows without leaving your terminal....

ALL, ENGINEERING, SOLUTIONS
Workflow Versioning and Backward Compatibility: Stop Breaking Long-Running Executions
March 17, 2026
How to ship new workflow versions without breaking in-flight executions....
Ready to Build Something Amazing?
Join thousands of developers building the future with Orkes.